论文地址:Learning code summarization from a small and local dataset
GCB-hybrid:数据增强去噪解码器+时序分割同项目微调
Abstract
像CodeBERT,GraphCodeBERT,CodeT5这类模型用了数十亿的词元来进行有监督的预训练,但是软件其实是非常项目相关的,不同项目环境可能大不相同,所以在项目专有数据上进行训练,在同一项目上进行测试是有希望的,在时序设置上进行评估可以防止训练-测试数据泄露
本文比较了多种模型和训练方法,包括同项目训练,跨项目训练,训练了一个特别为样本有效性设计的模型(在有限样本相同项目设置中学习),以及提出一种最大化混和方法,在很多语言微调后在同一项目训练
Introduction
数据可用性有限制:
- 一些不热门的语言(Ruby),高质量数据就少
- 一种语言的项目可能偏向于特定应用领域(javasript在web),因此模型训练出来可能不均匀
- 一个奇怪而独特的问题:项目特殊性
对于开发者而言,不同的项目表现不同,跨项目的模型在缺陷任务上表现不如项目内模型,早期的文献也表明了application-specific甚至是project-specific,file-specific影响
这些现象引出了一个问题:项目特定训练数据真的能提升效果吗?
- 从好的方面讲,词汇表,代码风格都是明现特定于项目的,同一项目应该会提高性能
- 但也有一些问题
- 必须小心划分训练集和测试集
- 项目内训练需要从较少的样本中学习很好的模型
因此研究提高基础模型训练微调阶段提升样本有效性的方法是有必要的,模型A跟模型B表现差不多,但是A用的数据更少,拿肯定说明A是一个样本高效的模型
本文用了多语言模型PolyGlot(在CodeXGlue榜单上登顶了一段时间)来看看同项目训练是否提供了一定提升,作者想了解即使这种经过广泛调整的良好模型是否在同项目中微调也能得到改进,实际上也确实改进了
主要贡献:
- 使用项目内训练,时间序列场景,过去数据上训练,未来数据评估
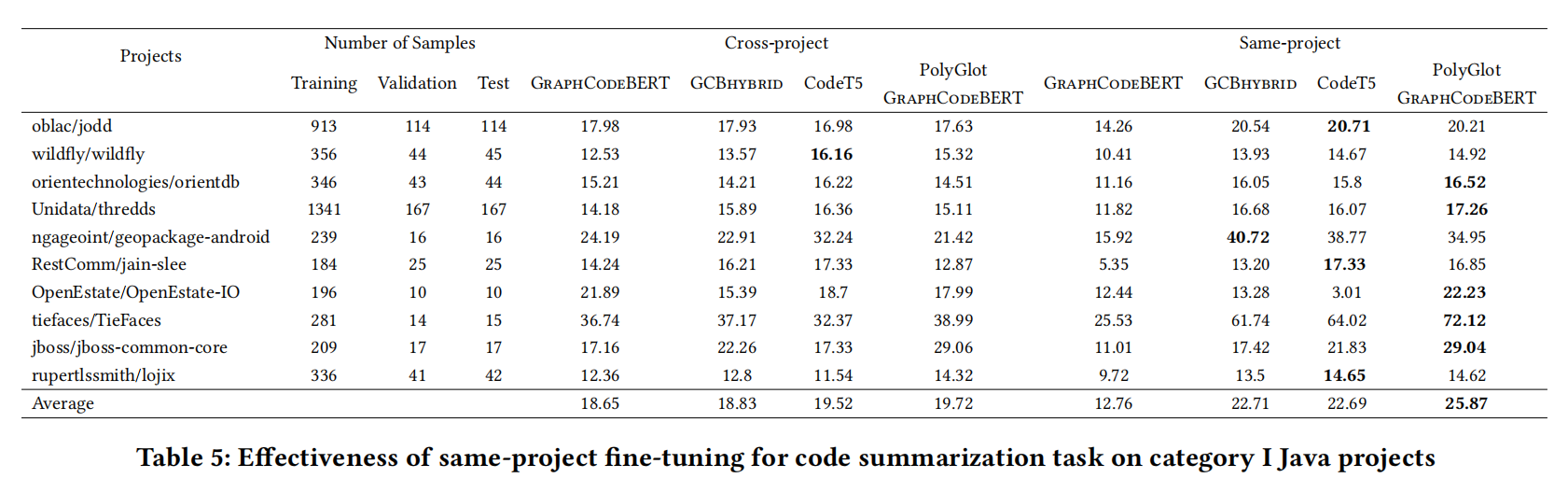
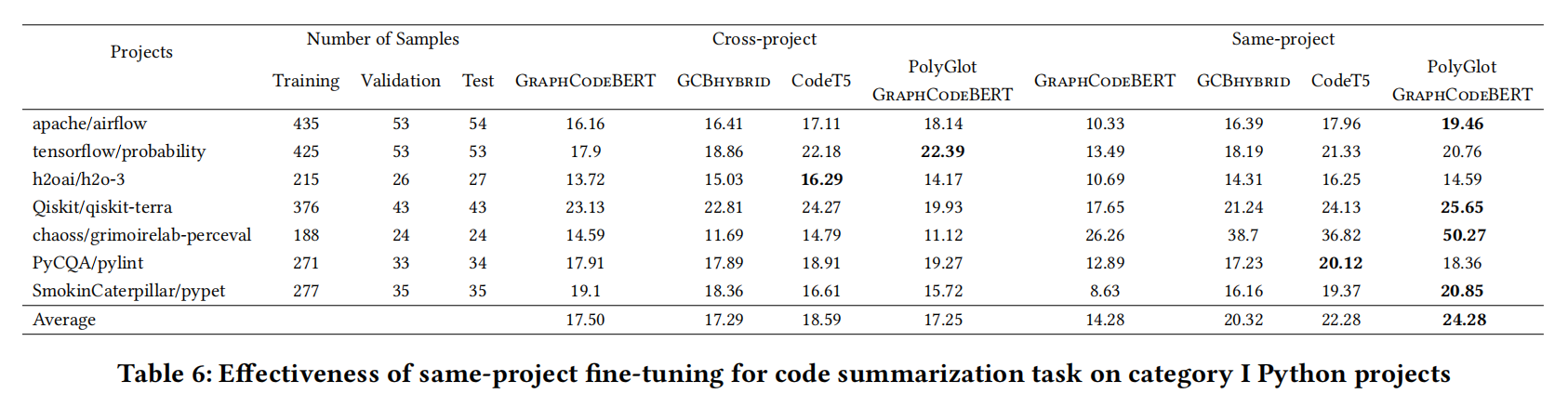
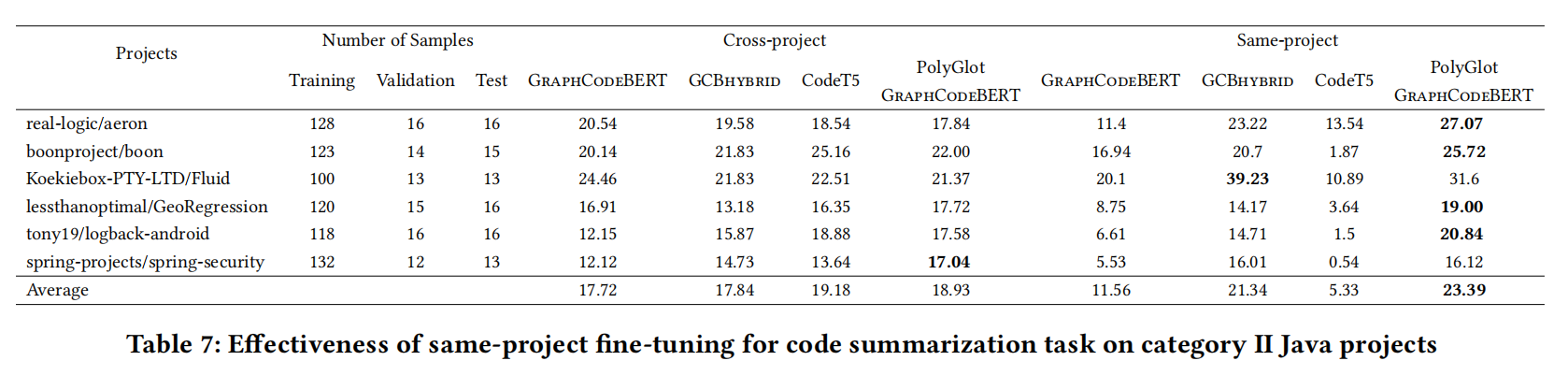
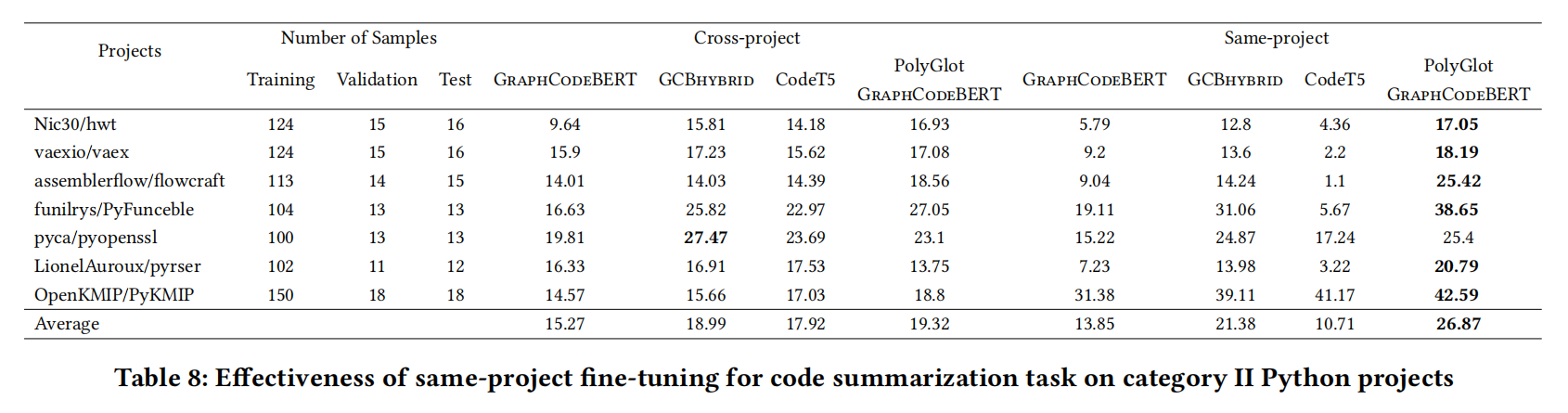
- 提高了GraphCodeBERT在代码摘要的样本效率,成为GCB-hybrid
- 对PolyGlot增加了project-specific微调打败了CodeT5
- 同项目设置确实最强,而且最大的项目也只用了跨项目训练不到2.5%的时间
Background & Motivation
PMQ 1
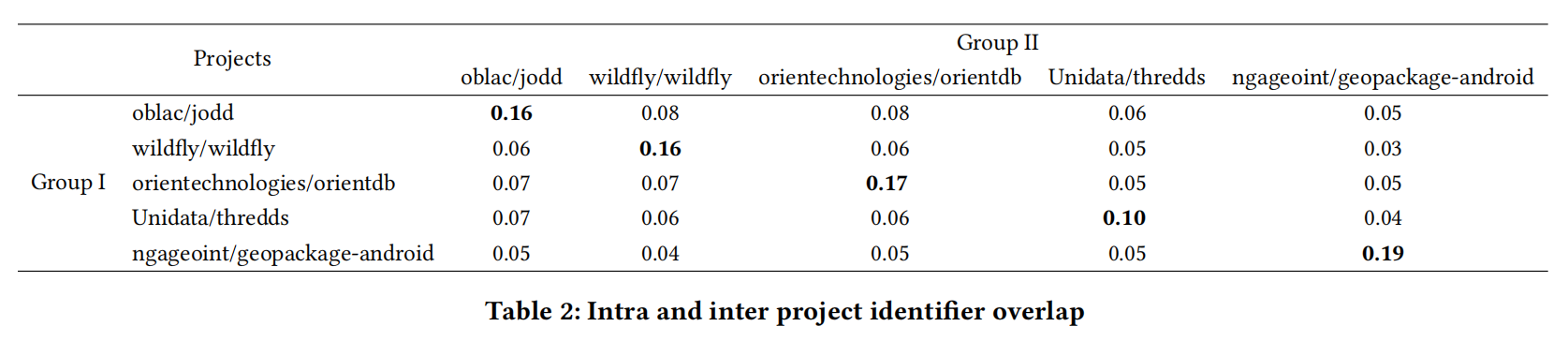
同一项目中的不同样本是否比随机项目抽样的样本共享更多的标识符?
取了5个项目,每个项目大概200条样本,分2组计算相似度发现的确同项目更高
PMQ 2
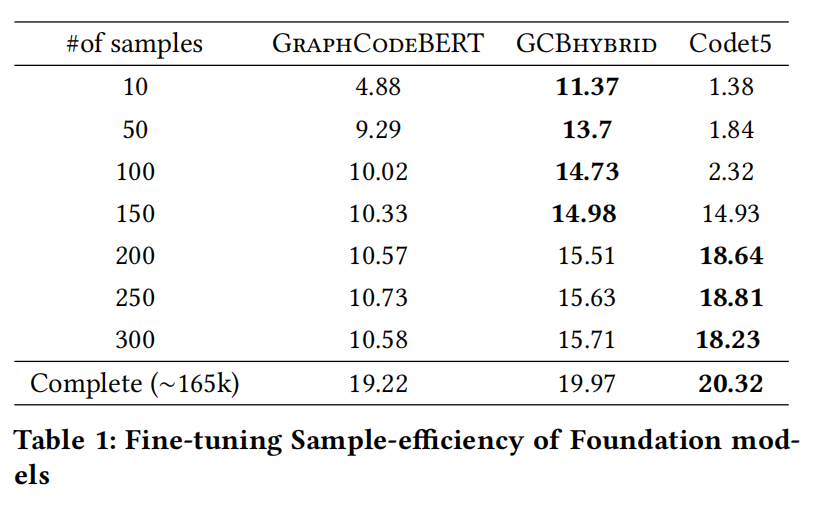
高容量的预训练模型的样本效率高吗?
预先训练好的模型可以适应于微调样本效率,这种模型在代码摘要任务中有最好的竞争力
Methodology
Dataset Preparation
在CodeXGLUE上准备了同项目数据集,按8:2时间分割训练集,验证集和测试集
Assigning creation date for functions

用 git blame -ignore-rev 获取特定行的第一次提交时间,从函数第一句扫描到最后一句,最早时间视作创建函数的时间,比如图1的第一句话是2018年提交的,但是剩下的都是2015年,所以这个函数初始时间被定为2015年
那如果所有句子都被改过了,导致找不到初始时间咋办,作者说这种情况不可能
还有一个问题是这种方法不能跟踪代码在本地修改的情况,作者说没关系,我们相信这样还是能给出公平的时间分割的实例
Prepared datasets for different instance ranges
创建同项目数据集的时候只用了CodeXGLUE的测试集,因为训练集在预训练模型中用过了会数据泄露,不用验证集因为预训练模型是在上面评估的,效果肯定好
主要使用python和java两种语言,按训练样本数分为三类:150+,100-150,100-
Foundation Models
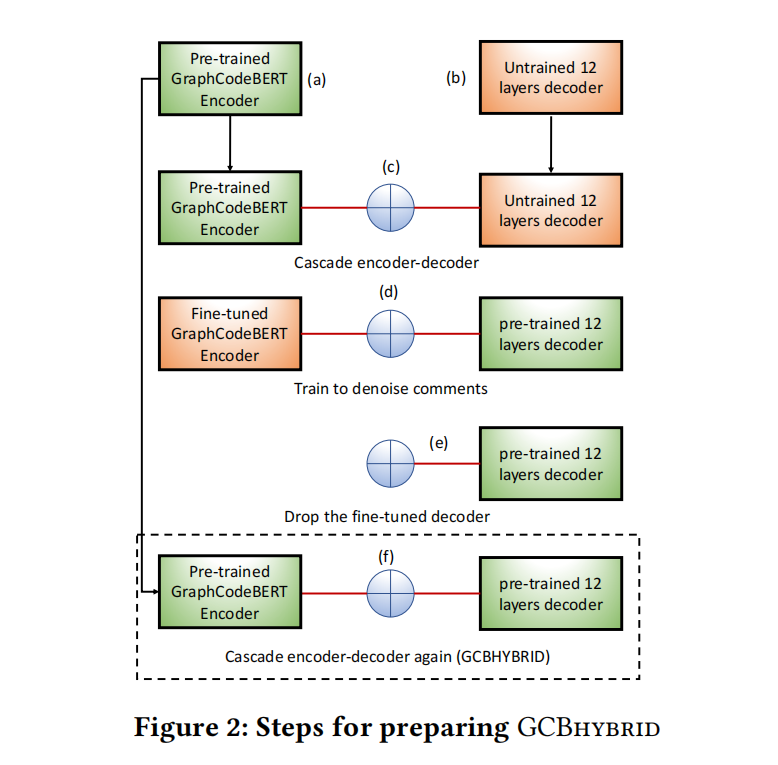
作者提出的GCB_hybrid模型将GraphCodeBERT连上了一个特殊的decoder来对自然语言注释降噪

对每个样本使用了两种不同的噪音模式进行增强:
- commnet permutation:取一个时间刻的注释随机打乱token
- comment rotation:随机选个token放开头,有利于建模注释初始选择
- token deletion:选15%注释丢了,建模生成能力
- token masking:选15%注释屏蔽,要解码器恢复
- token infilling:从 $\lambda=3$ 的泊松分布中随机选跨度,用
<mask>替代这个跨度的句子
为了加速训练,GraphCodeBERT用CodeBERT初始化,CodeBERT用RoBERTa的权重
Results