论文地址:Cross-Domain Deep Code Search with Few-Shot Meta Learning
CDCS:元学习随机划分数据集做代码搜索任务+大量实验
Abstract
近些年像CodeBERT一样的预训练模型在代码搜索方面有很大进展,但需要大量的语料来微调语义分布,这使得限制了其在特定领域的实用性,所以作者提出了CDCS,先在python或Java这种常用语料库预训练,然后迁移到SQL之类的其他语言,用基于MAML的few-shot元学习算法来初始化参数
Introduction
特定领域语言的数据很少,因此只能先训练一个大型的多语言的模型,然后在任务特定数据集上微调。问题在于怎么样迁移先验知识,不同语言特征不同表示不同,容易导致一个冲突的共享表示,特别是在领域特定的代码搜索,目标语言样本在训练数据中很少
CDCS就是CodeBERT+元学习算法,来找一个好的初始化参数适应小训练数据集的新任务
Approach
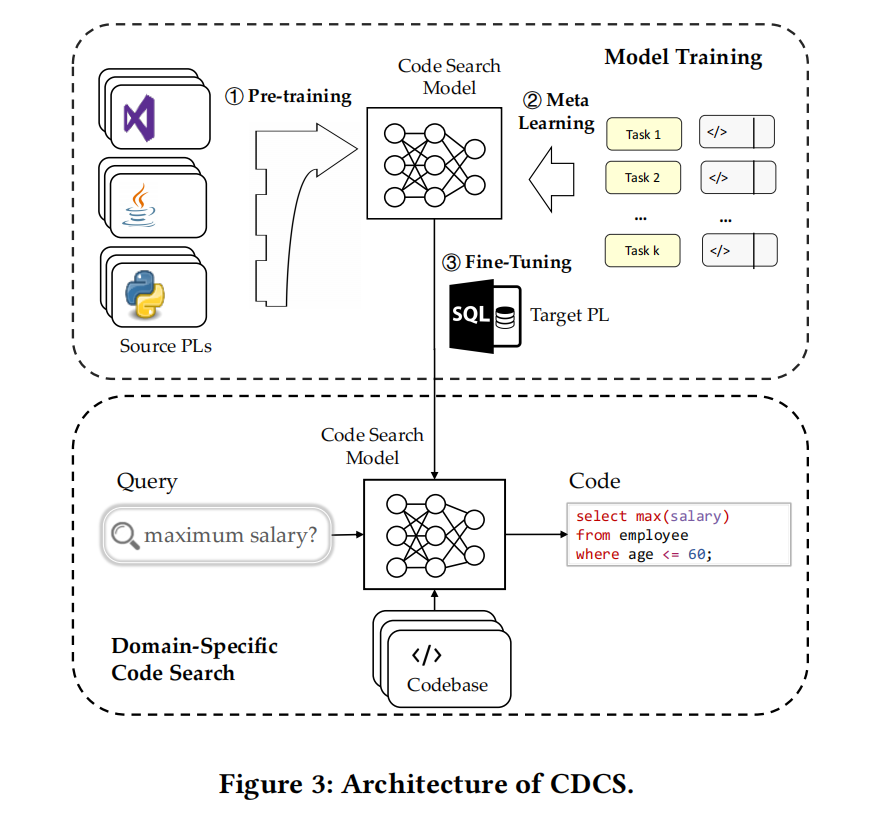
Pre-training
类似CodeBERT使用了MLM预训练任务,但没用RTD,因为没啥用
输入为<NL, PL>对,[CLS], w…, [SEP], c…, [EOS],前面是自然语言后面是程序语言
Meta Learning

把训练数据拆分为k个batch ${D_1,…,D_k}$,每个 $D_i$ 视作一个局部任务 $T_i$ ,再进一步划分出训练集和验证集进行局部更新,然后每M步进行一次全局更新
Fine-Tuning
在代码搜索任务上微调时把代码检索任务变成二分类,1相关,0不相关,[CLS]视为输入序列的聚合表示,输入一个全连接分类头来预测给定的<NL, PL>对是否相关
Domain-Specific Code Search
输入查询Q与代码数据库里的代码段形成一个个<NL, PL>对,输入训练好的模型得到分数排序
Experiment
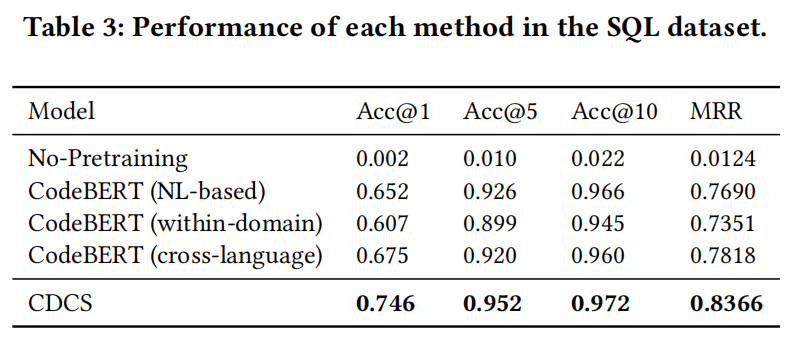
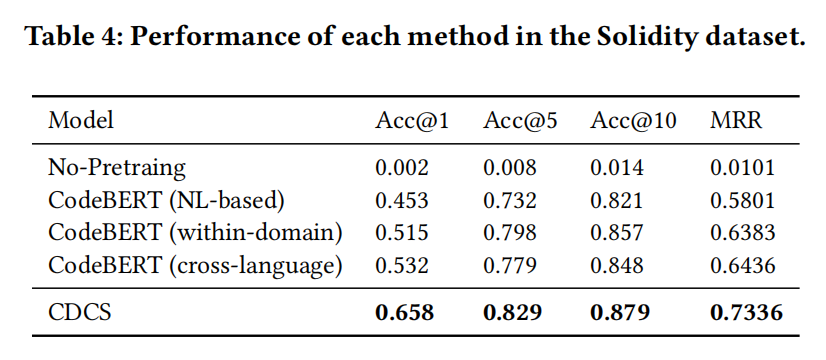
RQ1:CDCS在跨域代码搜索中的效果如何?
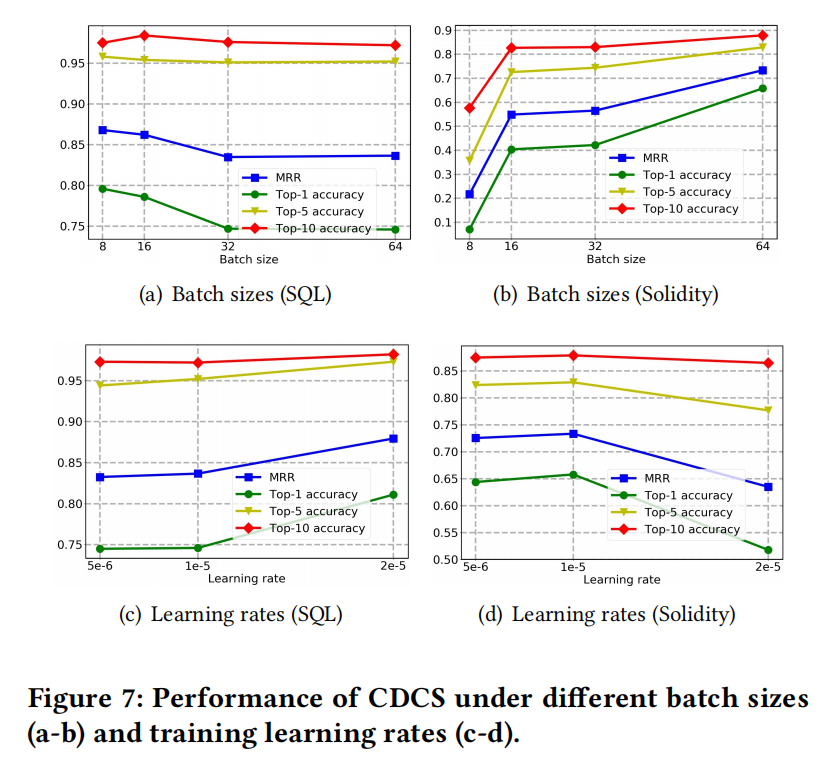
RQ2:不同训练数据集大小的表现
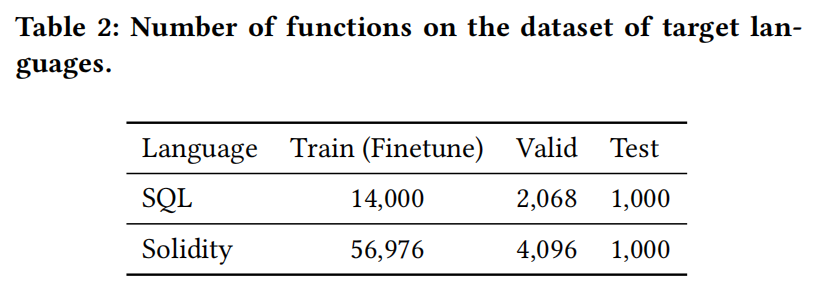
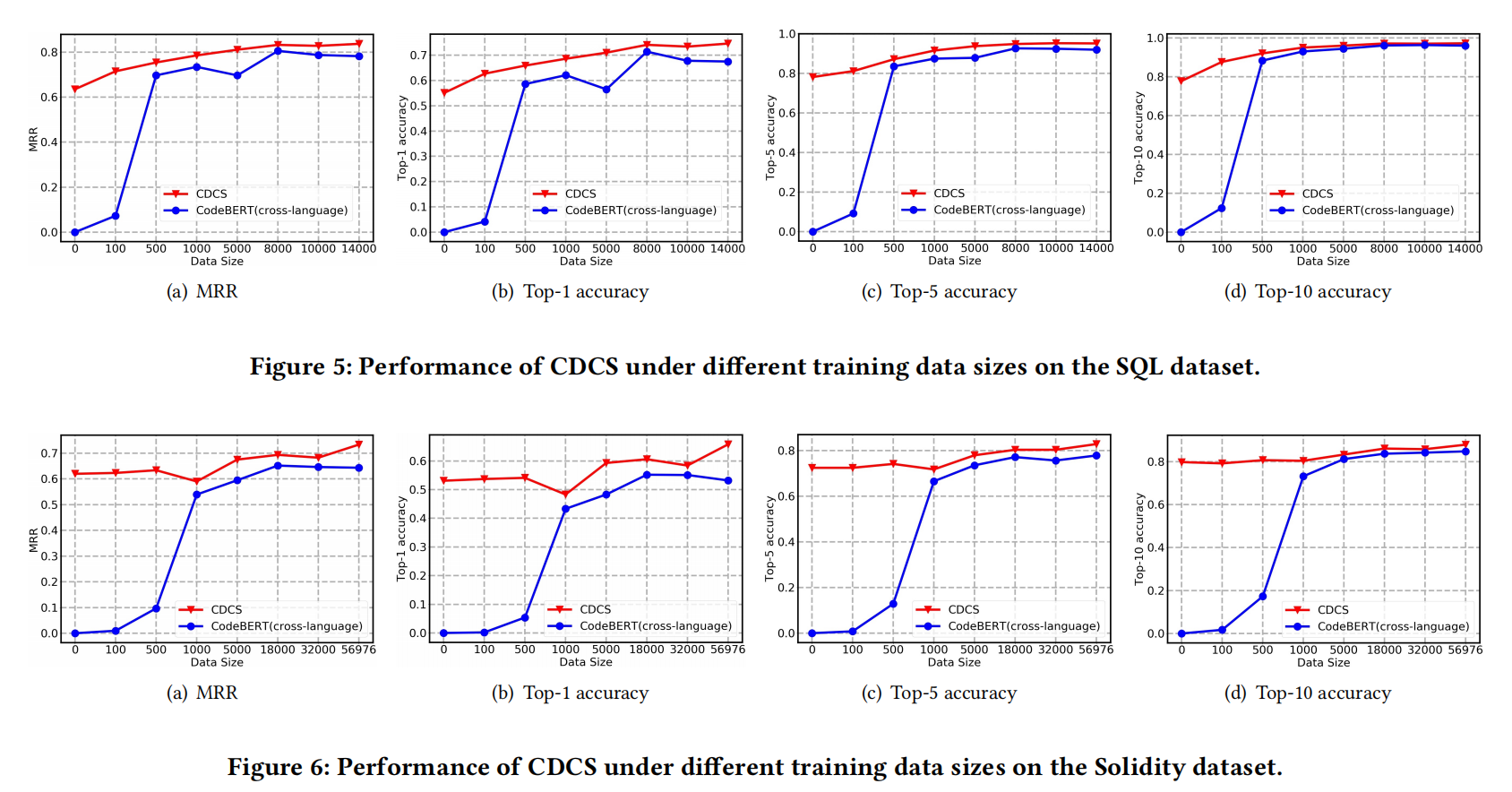
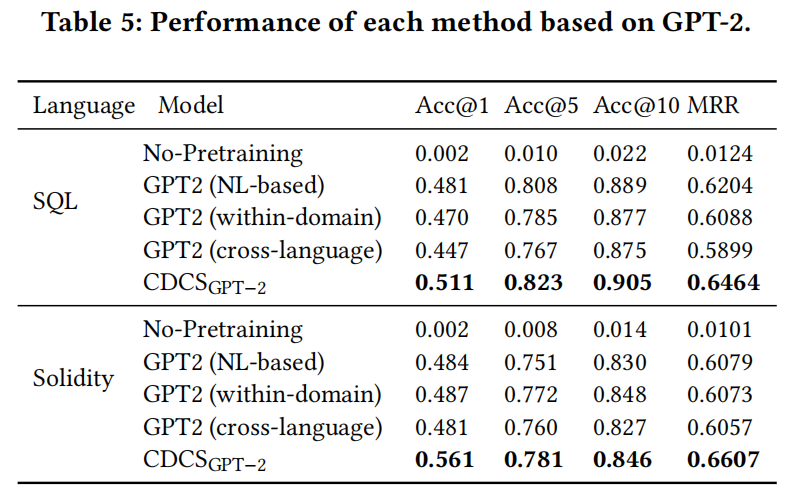
RQ3:其他预训练模型的表现
RQ4:不同超参影响
这里很奇怪的是图7a里面把batch_size变大了反而精度下降了,作者也没有解释