论文地址:SynCoBERT:Syntax-Guided Multi-Modal Contrastive Pre-Training for Code Representation
对比学习的方法,做得估计比CodeBERT和GraphCodeBERT大不少,但是效果提升也很明显
SynCoBERT:标识符预测,AST边预测与多模态跨batch对比学习
Abstract
目前预训练模型已经表现出了很好的下游任务效果,目前的方法也更加重视结构信息(AST,数据流)。作者提出了两个新的预训练目标,标识符预测(IP)和AST边预测(TEP),以及一种多模态的对比学习策略来最大化不同模态之间的互信息
Introduction
为了更好的表示代码的语法结构,我们考虑两个关键但容易忽视的代码特征:
-
代码标识符包含了符号和语法信息,比如
x = len("x"),前一个x和后一个字符串x肯定不一样 -
AST边的语法信息被忽略了,比如图1里面
x+y语句可以用一个binary_operator指向三个叶子节点来表示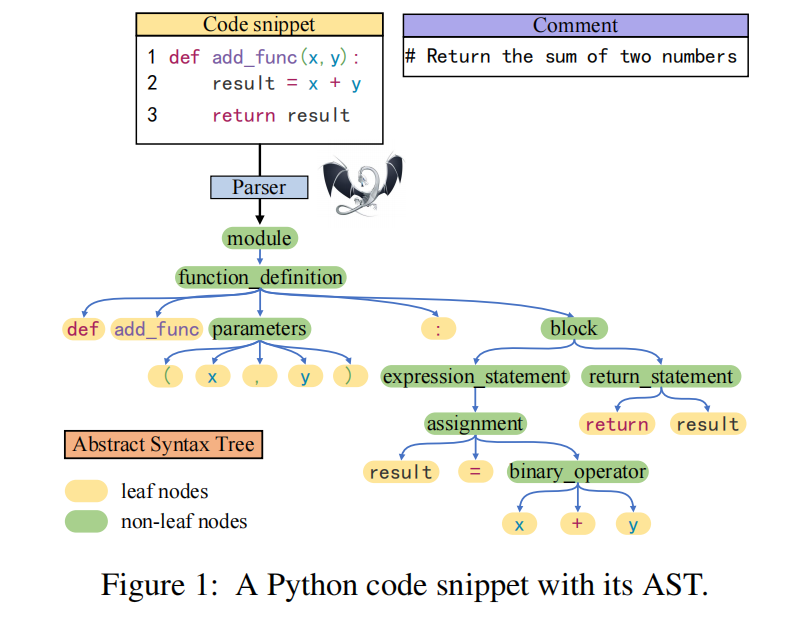
此外,一个程序可以被分解为代码块和注释,代码块还可以被分解为不同的语法结构,比如ast或者数据控制流图,本文将这些从不同视角得到的特征视为语义等价的多模态
主要贡献:
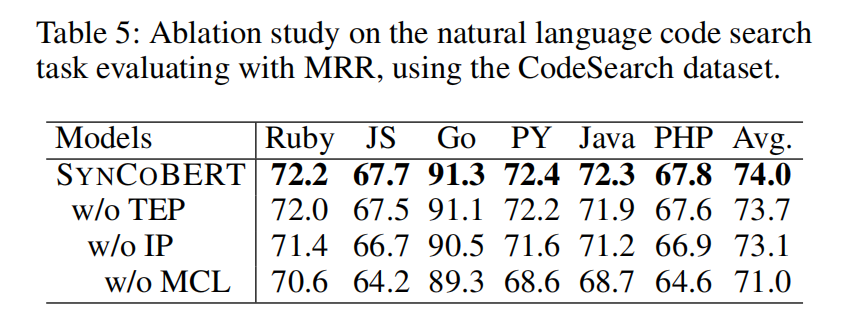
- 两种预训练目标:IP预测一个词元是不是标识符和TEP预测两个结点之间的边
- 多模态对比学习代码,注释和ast
SynCoBERT
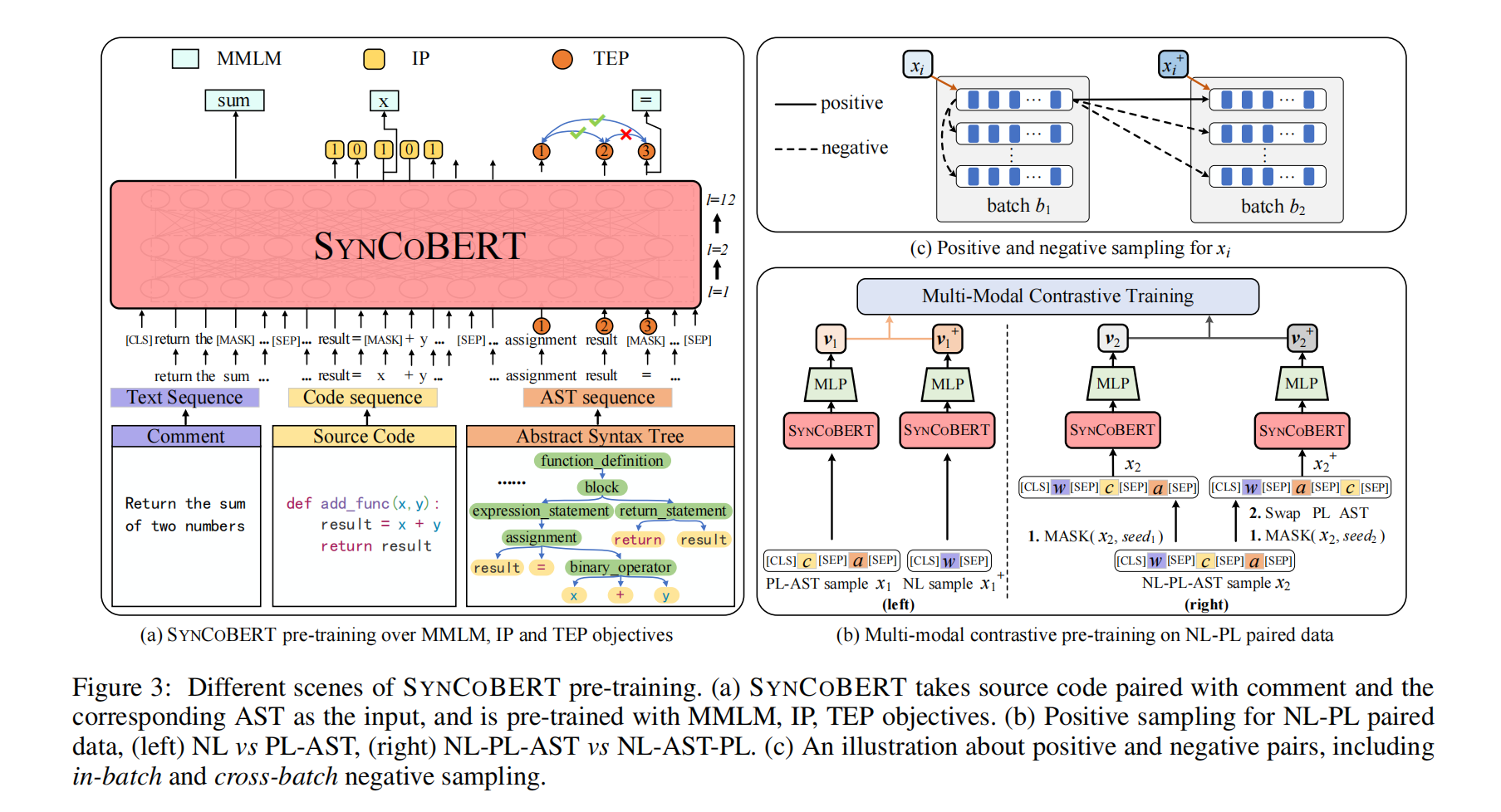
Preliminary
使用tree-sitter把代码转为ast,输入为(NL, PL, AST),$x={[CLS],w,[SEP],c,[SEP],a,[SEP]}$
12层Transformer,768hidden size,12个注意力头
Multi-Modal Masked Language Modeling (MMLM)
将掩码语言模型(MLM)扩展到多模态,三元组中随机选15%,其中80%变成[MASK],10%变成随机词元,剩下10%不变
Identififier Prediction (IP)
详细预测具体的标识符太难了不可能,所以把词元分为了标识符和非标识符,与MMLM不同,对所有代码都提出了标识符预测目标,1表示是标识符,0表示不是
AST Edge Prediction (TEP)
把AST边mask掉,让模型去预测,比如图3 (“assignment”, “result”) 是有边的,但是 (“result”, “=”) 是没边的
Multi-Modal Contrastive Learning (MCL)
词元不平衡问题在代码里面也很严重,比如python函数里面def哪里都有
Positive Samples
图3b左,NL和PL-AST
图3b右NL-PL-AST和NL-AST-PL,就是换了个位置
Negative Samples
图3c,先拿一个batch为b1,然后取它的正样本对batch为b2,同一位置为正样本,不同位置为负样本,同一batch不同位置也为负样本
Experiment
8张32GB的V100
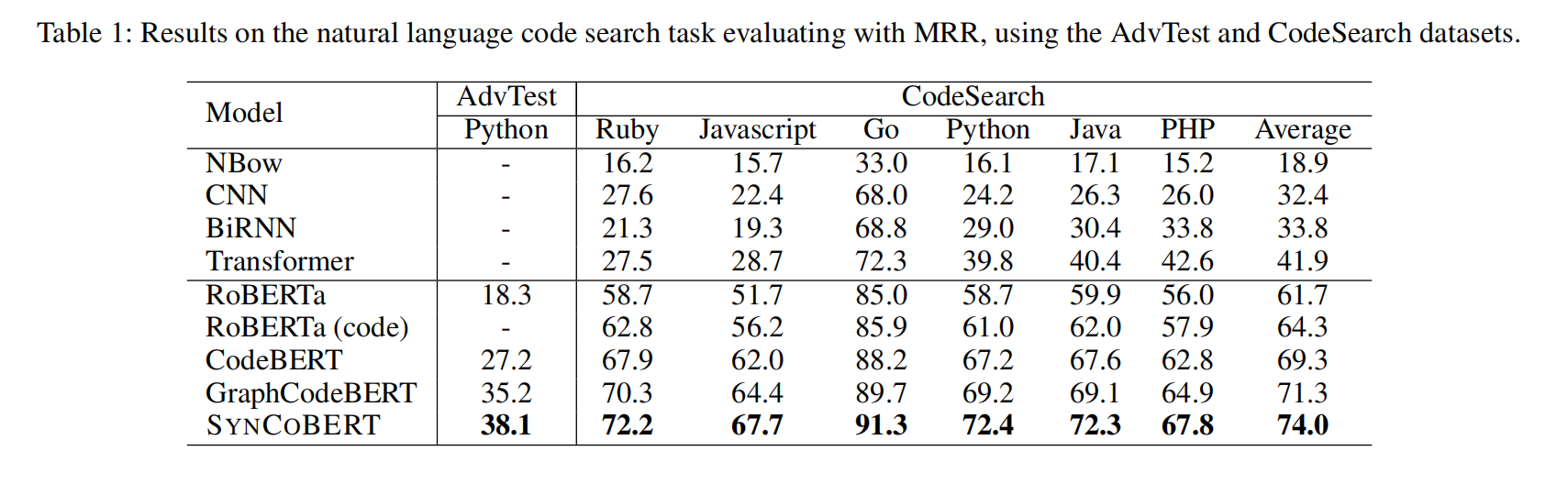
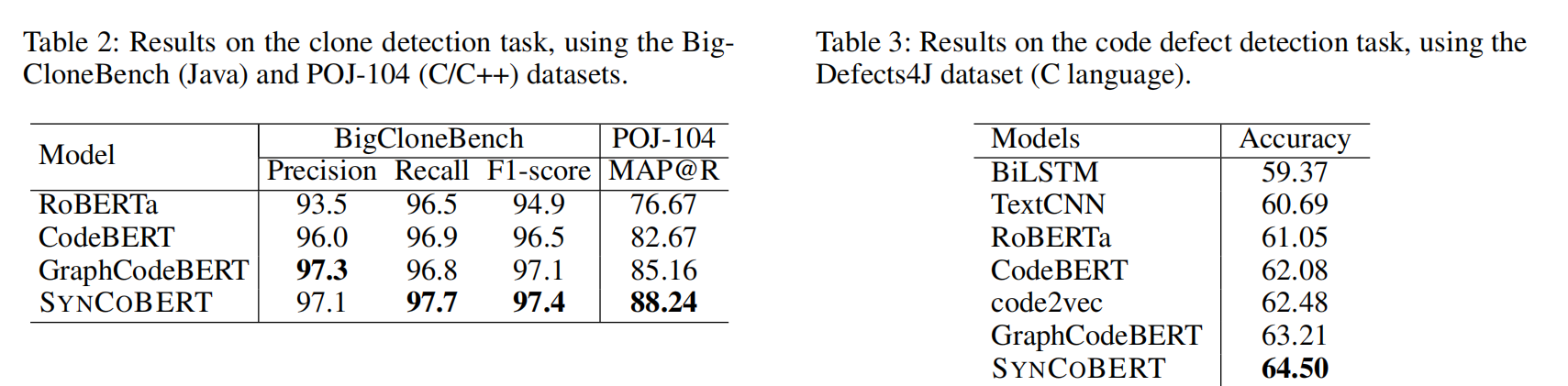
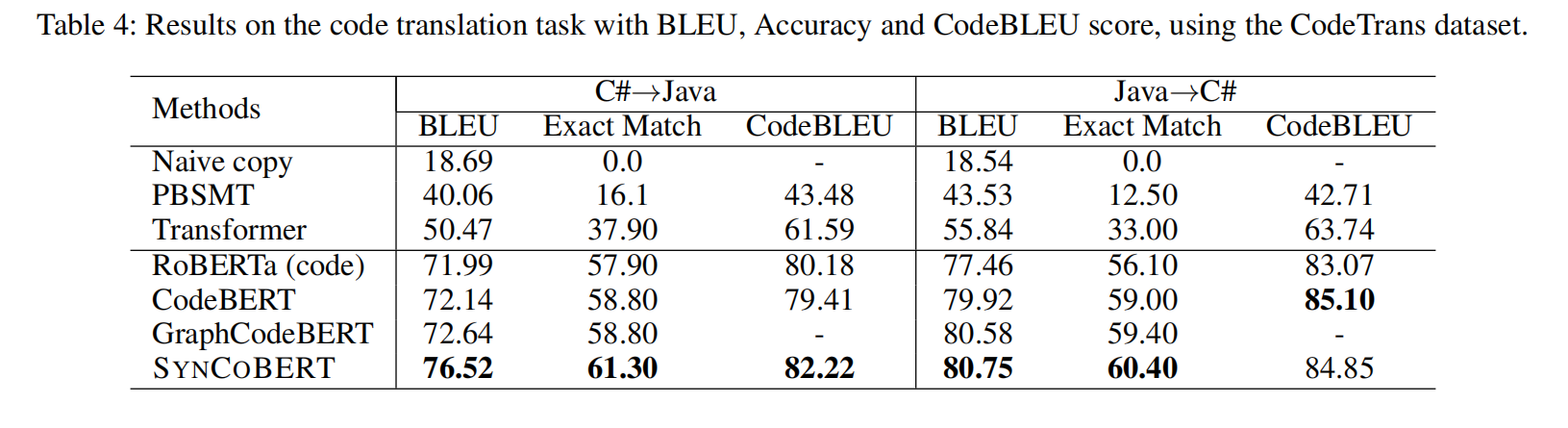
在两个数据集上所有语言都表现最好