论文地址:Unified Pre-training for Program Understanding and Generation
PLBART:多语言训练+去噪解码器
Abstract
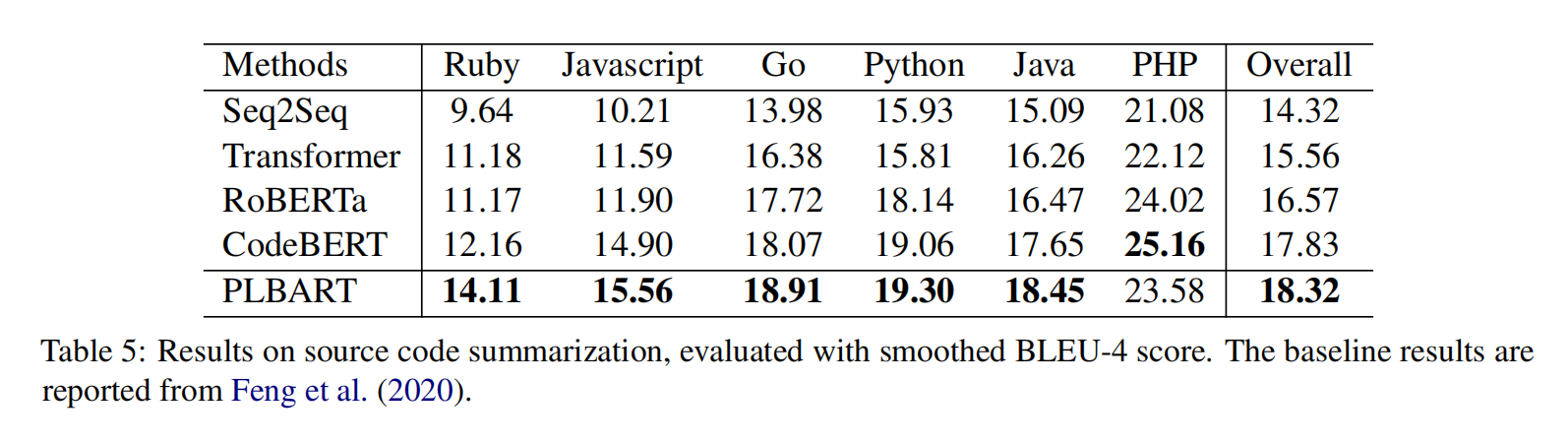
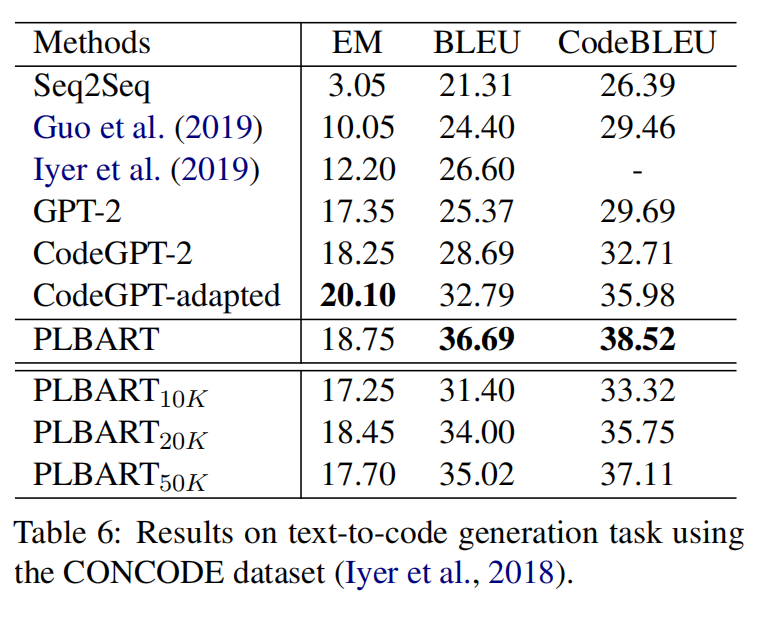
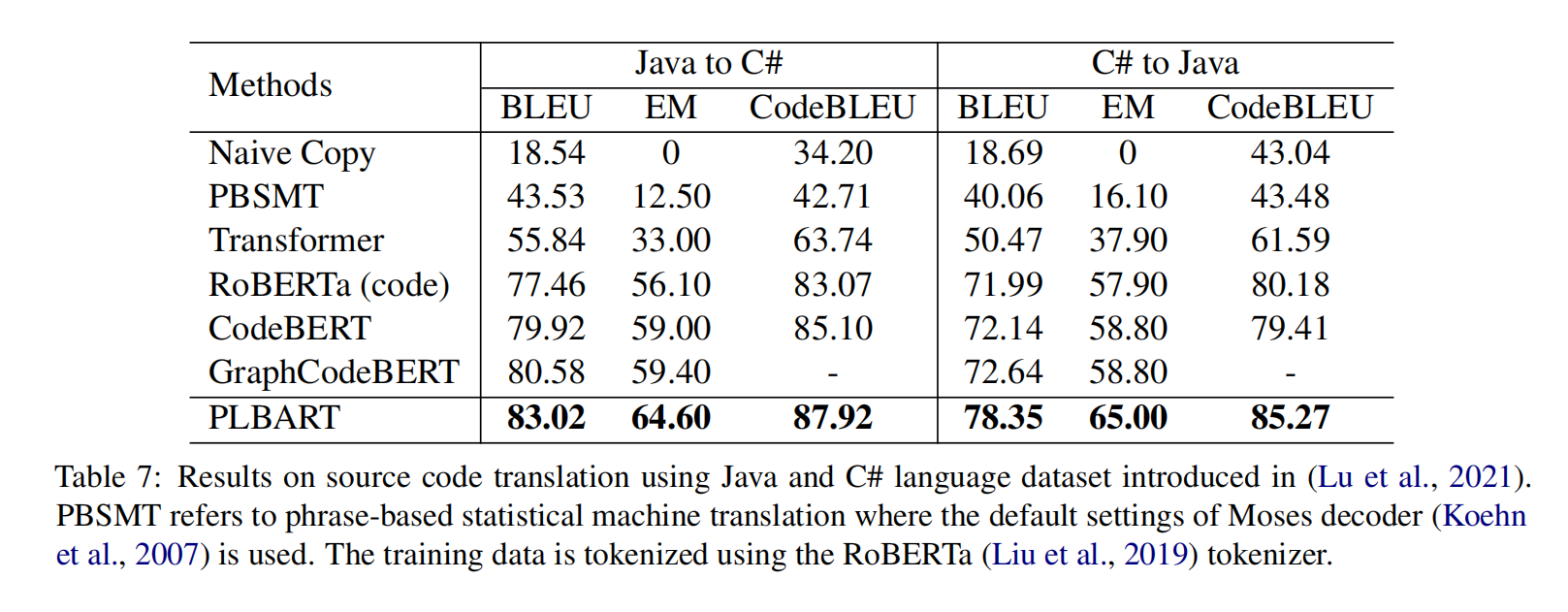
PLBART是端到端的模型,使用很多java和python的函数以及自然语言通过去噪自编码器来预训练,在代码注释生成,代码翻译7个语言上达到了SOTA,在程序修复,克隆检测等任务上取得了有竞争力的结果,分析显示还学习到了代码语法和风格
Introduction
如源代码摘要、生成和翻译,在很大程度上依赖于对PL和NL的理解——我们统称为PLUG(Program and Language Understanding and Generation)
作者提出了PLBART(Program and Language BART),这是一种双向和自回归transformer,对跨PL和NL的未标记数据进行预训练,以学习适用于广泛的PLUG应用程序的多语言表示
PLBART
Denoising Pre-training
Data & pre-processing
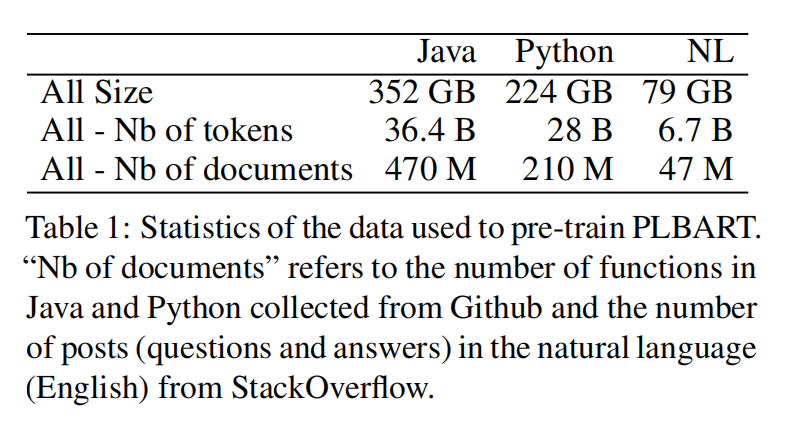
从 Google BigQuery 上下了很多java和python的github仓库;从 stackexchange 上下了stackoverflow的很多帖子,包括问题和回答,不要代码段
问题是一些模态可能有更多的数据,比如PL是NL的14倍,所以对数据进行混和和上/下采样,用以下概率
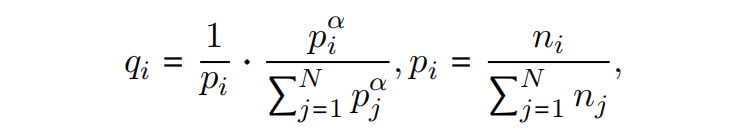
N是语言总数,$n_i$ 是某个语言的实例总数,$\alpha=0.3$
Architecture
架构与 BART_base 一样,6层编码器,6层解码器,768隐层,12个头,只是在编码器和解码器顶上加了一层LN
Noise function
三种噪音策略,token masking,token deletion,token infilling,词元填充就是把一段词元换成 <mask>,距离用泊松分布($\lambda=3.5$)
Input/Output Format

编码器输入是噪音文本序列,解码器输入是一个位置偏移的原始文本,以及分别在尾头添加了 <java>,<python>等符号,截断512
Learning
多语言预训练,这里是3,主要是最大化以下损失
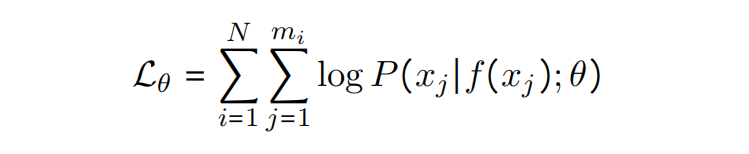
Optimization
8张2080Ti训练100000步长,Adam学习率1e-6,beta2=0.98,batch_size=2048,
Fine-tuning PLBART
Sequence Generation

Sequence Classifification
连接一对输入之间插入 </s>,在输入序列的末尾添加了一个特殊的标记,最后解码器表示丢入全连接层
Experiment