论文地址:Hierarchical Text-Conditional Image Generation with CLIP Latents
论文介绍:DALL·E 2
来自OpenAI的工作,能够通过文本对图片进行生成,修改
DALL·E 2:CLIP+扩散模型文本图片生成
Abstract
对比学习比如CLIP已经能够学习到很好的语义和风格信息,为了使用这些表示做图像生成,作者提出了一种两阶段模型:先是给定文本特征生成CLIP图像嵌入表示(prior),然后解码器根据表示生成图像(decoder),这种显式生成图像表示对多样性很好。解码器用了扩散模型
Introduction
CV领域主要的进展就是用了更大的数据集和模型,CLIP通过简单的对比学习方式就能学到很好的特征,对于分布偏移等问题也比较健壮。扩散模型在最近也推进了视频和图片任务的SOTA,多样性比GAN更好,但保真度,细节不如GAN系列工作,但最近的一些技术又推进了扩散模型

Method
数据集和CLIP一样都是图像文本对,两个组件:prior和decoder
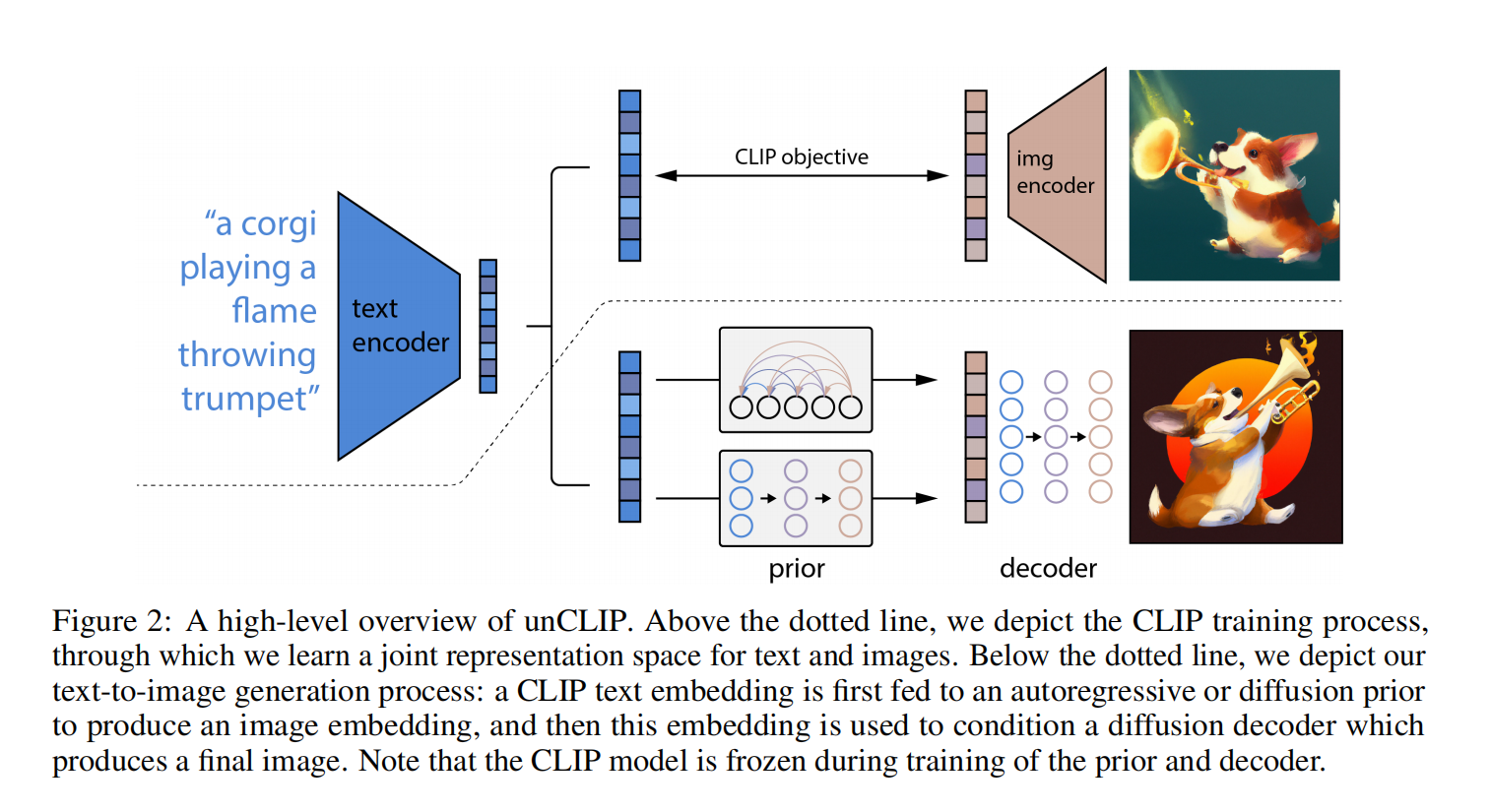
图2上半部分是CLIP,训练好了一直都是锁住的不会再训练了
下半部分是DALLE,CLIP文本编码器是固定的,文本和文本特征一一对应,然后用文本特征预测上面CLIP的Ground truth的图像特征
Decoder
用了classifier-free guidance,10%的CLIP嵌入随机设置为0(或学习嵌入),并在训练期间50%随机删除文本
在模型中只用了空间卷积,没有用attention,所以在推理的时候可以用在任意尺寸上,不用序列长度保持一致,生成高清图
Prior
作者尝试了两种方案:自回归做prior或者扩散模型做prior
用扩散模型时仅训练了transformer的解码器,模型输入:文本,CLIP文本的嵌入,扩散步数的嵌入,加入噪声的CLIP图像嵌入,最后还有transformer本身的嵌入背用于预测没有噪声的CLIP图像嵌入
这里作者发现直接预测图片比预测噪声效果更好
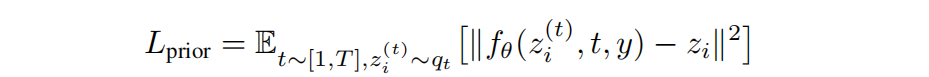
Experiment
图像内差,图像与文本内差示例


扩散比自回归好一点点
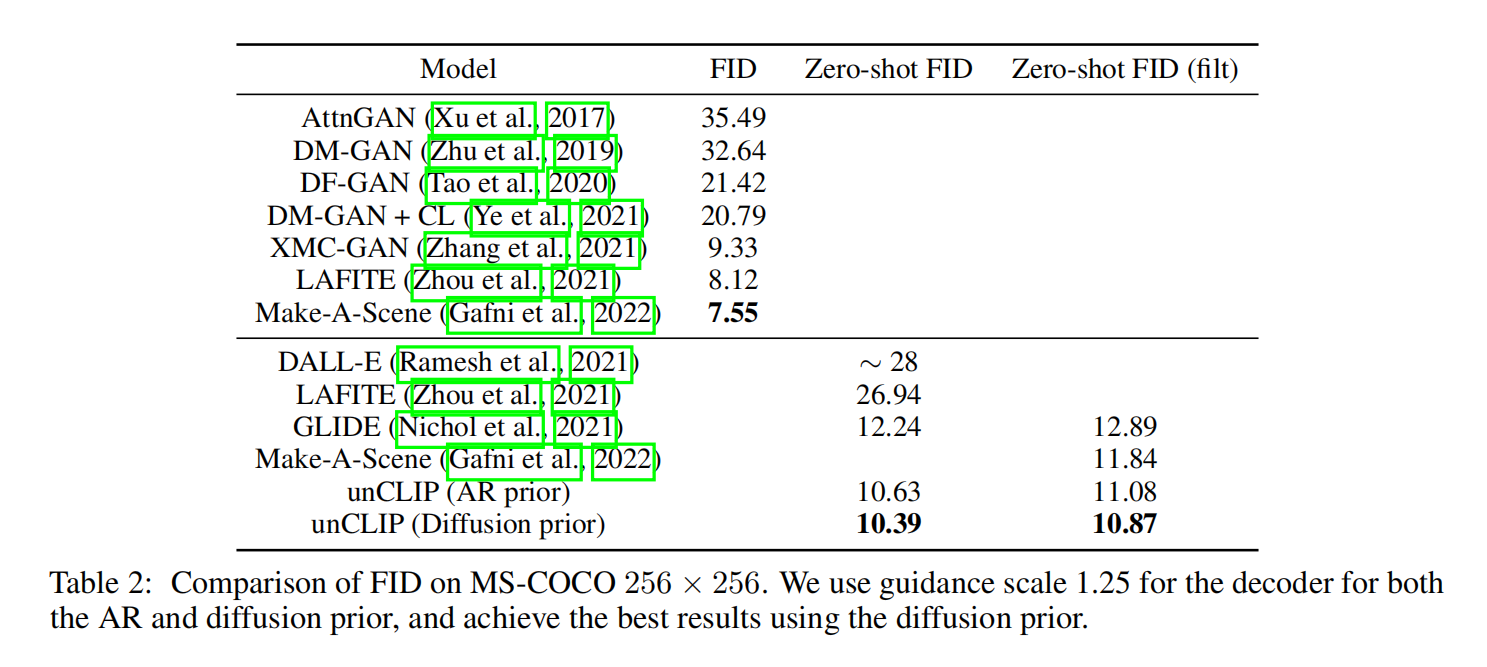
具体效果

Limitation
不能很好的把物体跟属性结合起来,可能是用了CLIP的原因,主要找物体上的相似性

提示词生成的顺序不对,可能由于文本编码器关注于词根词缀或其他原因导致的

不能生成复杂的场景,缺失很多细节


