GraphCL:图增强对比学习及其分析
Abstract
作者设计了四种图增强方法来融合不同的先验知识,系统性研究了不同组合的图增强技术在不同数据集下的效果,在四种不同的设定下:半监督,无监督,迁移学习和对抗攻击。结果表示即使不调优增强的范围也不用复杂的GNN架构,GraphCL框架依旧能生成堪比SOTA的方法的很好的图表示
Introduction
相比于CNN在图像上的应用,GNN预训练策略对图结构的设计有独特的困难,因为他有丰富的上下文结构化信息,比如分子原子的键,社交网络的交互等等,这就导致了很难设计一个对下游任务很泛化有效的预训练策略
主要贡献:
- 设计了四种类型的图形数据增强,每一种都对图形数据施加了一定的先验,并对其范围和模式进行了参数化
- 提出了一种新的图对比学习框架(GraphCL)用于GNN的预训练,从而可以为不同的图结构数据学习对特定扰动不变的表示,并且证明了GraphCL可以被重写为一个图数据上的通用框架
- 评估了在不同类型的数据集上对比不同增强的性能,揭示了性能的基本原理,并为采用特定数据集的框架提供了指导
Methodology
Data Augmentation for Graphs
数据增强的目的是通过应用某些转换,在不影响语义标签的情况下创建新的、现实合理的数据,在图领域还没有得到很好的探索
我们主要关注三类:生化分子(如化学化合物、蛋白质)、社会网络和图像超像素图

- 结点丢弃:节点丢弃将随机丢弃顶点的某些顶点及其连接,缺少部分顶点并不影响g的语义意义。每个节点的丢弃概率遵循默认的i.i.d.均匀分布
- 边缘扰动:通过随机添加或删除一定比例的边来干扰G中的连接性,说明G的语义意义对边缘连接模式方差具有一定的鲁棒性。遵循i.i.d.均匀分布,以进行每条边的增减
- 属性屏蔽:属性屏蔽提示模型使用它们的上下文信息来恢复被屏蔽的顶点属性。基本的假设是,缺少部分顶点属性对模型预测没有太大影响
- 子图:使用随机游走从G中抽取一个子图,假设G的语义可以大大保留在其(部分)局部结构中
Graph Contrastive Learning
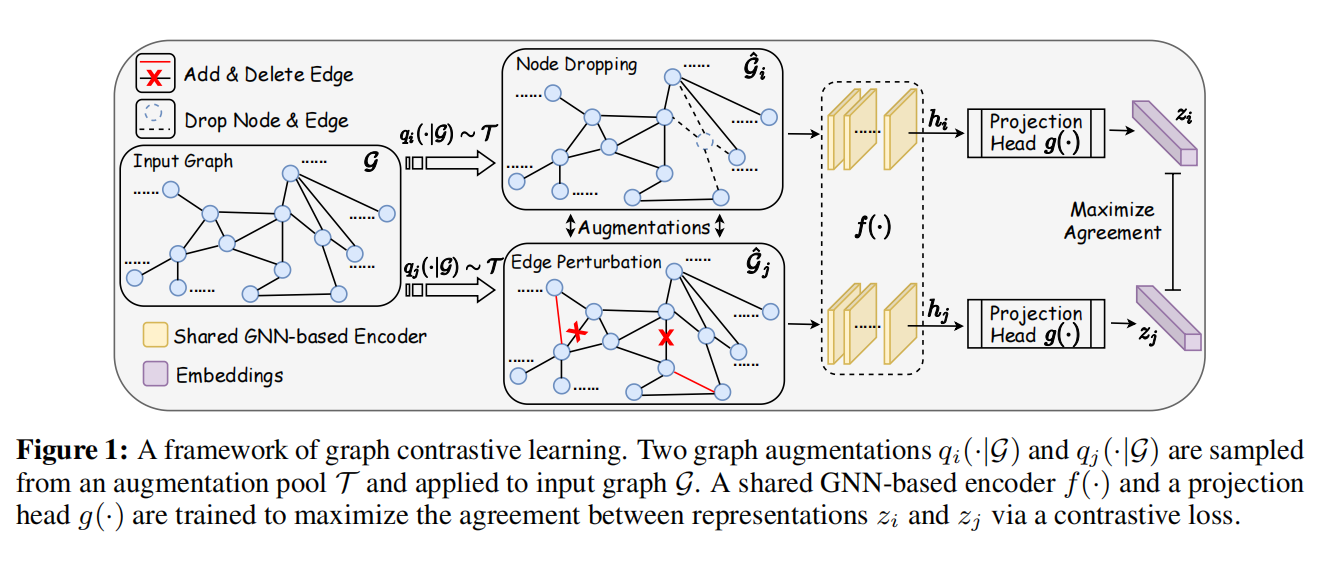
The Role of Data Augmentation in Graph Contrastive Learning
Data Augmentations are Crucial. Composing Augmentations Benefifits
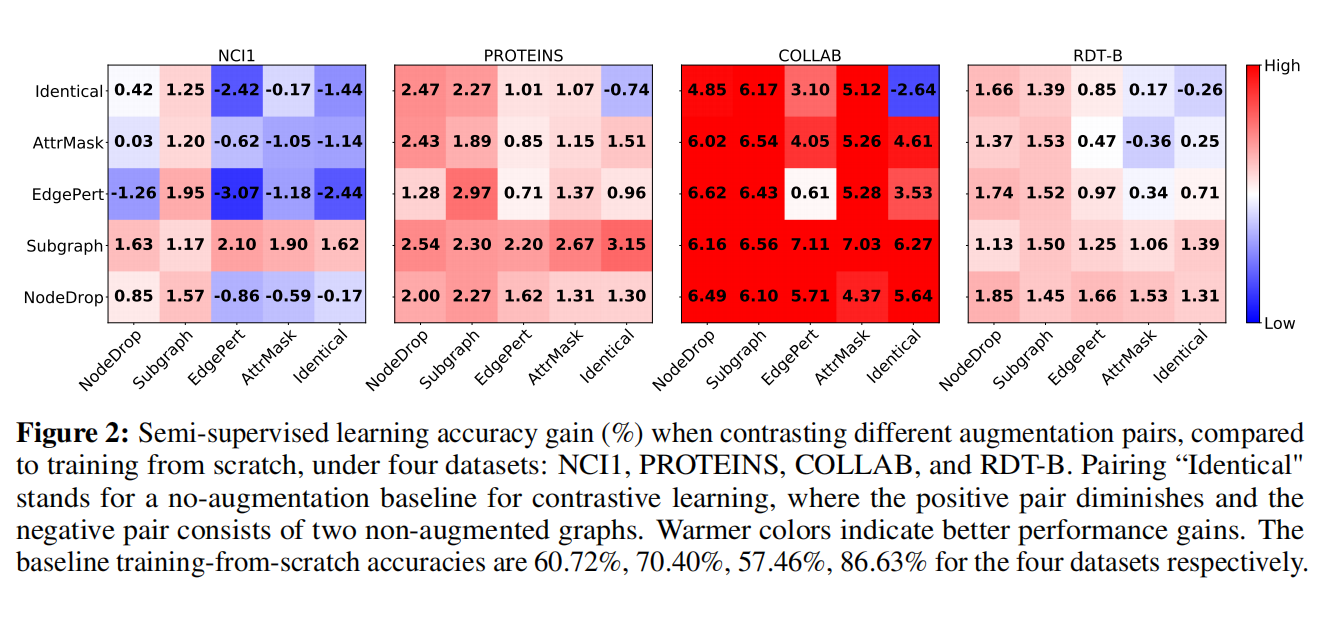
Obs. 1. Data augmentations are crucial in graph contrastive learning
从最上面行或最右列可以看出单一数据增强也带来了一定的提升,应用适当的增强时,在数据分布上注入相应的先验,通过最大化图及其增强之间的一致性来强制模型学习对期望扰动不变的表示
Obs. 2. Composing different augmentations benefifits more
同时组合多种数据增强可以带来更好的效果,可能是因为组合不同类型的增强对确实对应于一个“更难”的对比预测任务
The Types, the Extent, and the Patterns of Effective Graph Augmentations
Obs. 3. Edge perturbation benefifits social networks but hurts some biochemical molecules
与社交网络的情况相比,一些生物分子数据的“语义项”对单个边缘更为敏感,改了分子的边可能意义就完全变了,但是社交网络的边影响不大
Obs. 4. Applying attribute masking achieves better performance in denser graphs
掩蔽模式也很重要,而掩蔽有更多度的枢纽节点有利于更密集的图,因为gnn不能根据信息传递机制重建孤立节点中的缺失信息
Obs. 5. Node dropping and subgraph are generally benefificial across datasets
对于节点删除,强调缺少某些顶点(例如化合物中的一些氢原子或社交网络中的边缘用户)不会改变语义信息的先验,直观上符合我们的认知
子图和全局信息一致性有助于表示学习,这解释了观察结果,比如化合物的子图可以表示结构或功能
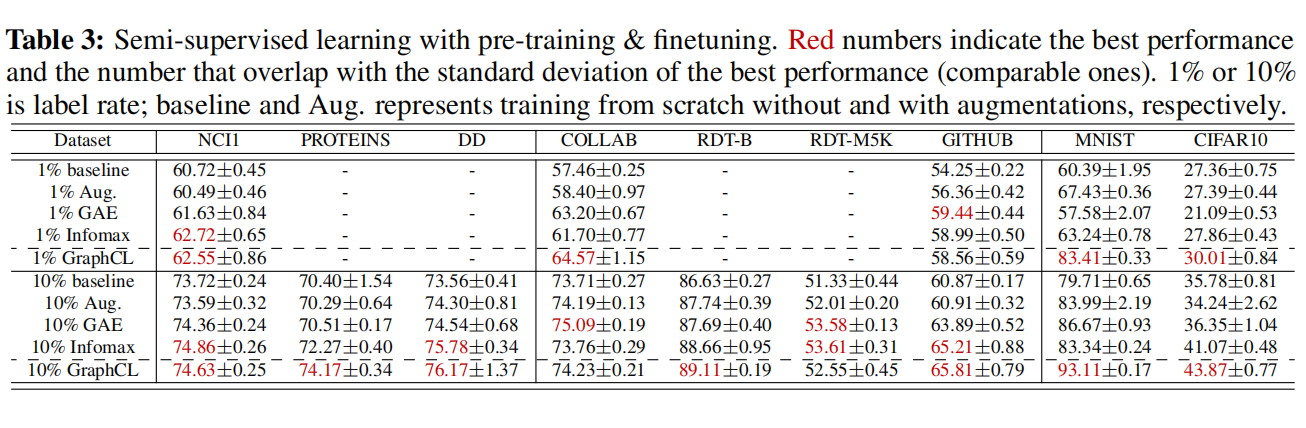
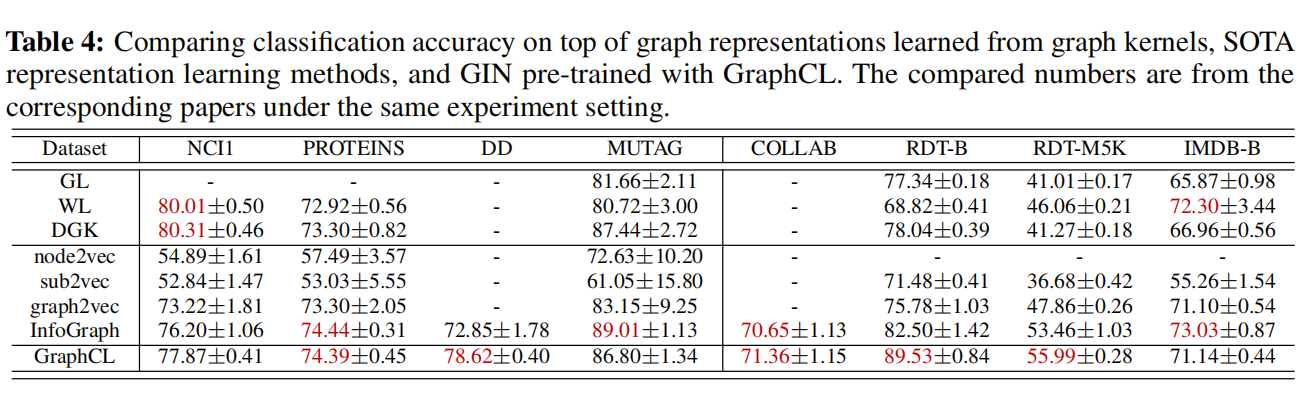
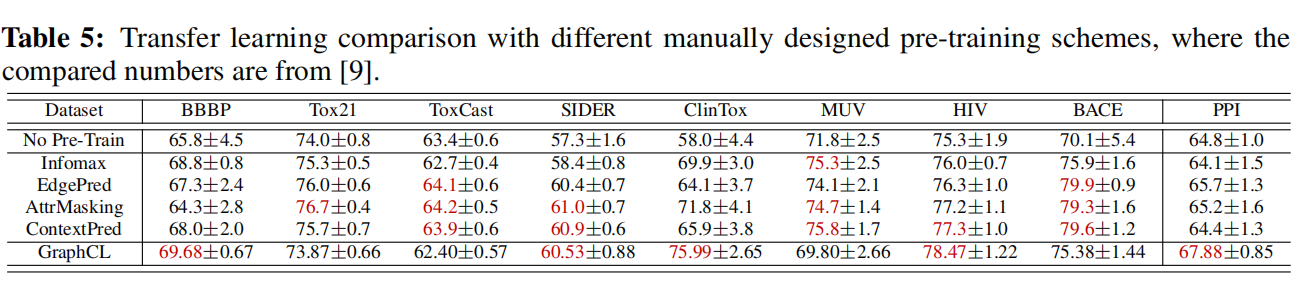
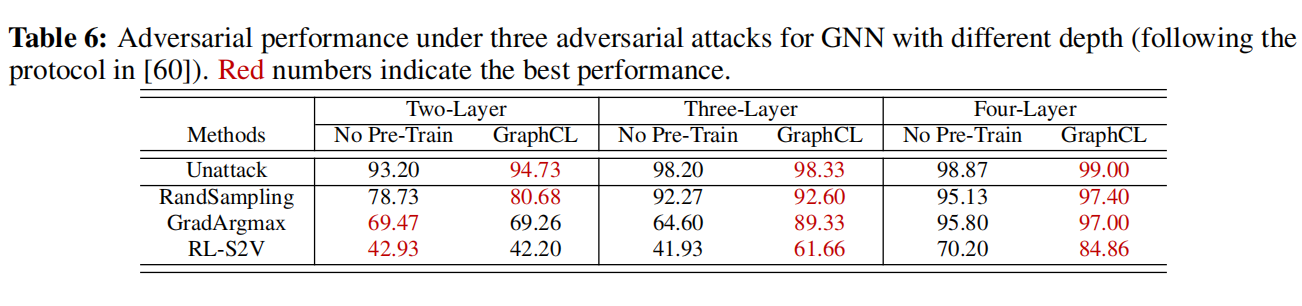
Comparison with the State-of-the-art Methods