code-docstring-corpus:python代码注释生成数据集
Abstract
作者提出了一个大的多样的Python函数与注释文本的平行语料库,以及实验了一些数据增强方法来增加训练数据量
Introduction
Existing corpora
一些现有的语料库,如 DJANGO 数据集和 Project Euler 数据集已经由人注释,可以产生高精度的样本,但导致成本高且小(从几百到不到20000个例子)和同质数据集
其他语料库是由用户生成的描述与从公共网站挖掘的代码片段匹配的,如 StackOverflow 或 IFTTT。这些数据集可以很大(>10万),但通常非常嘈杂
其他的方法是适用于特定领域的
这些语料库都存在一定的问题,比如 DJANGO 和 Project Euler 语料库使用伪代码而不是真正的自然语言作为代码描述,这导致代码片段和描述相似,易于对齐。The Magic the Gathering 和 Hearthstone 代码片段是重复的,例子中的大多数代码要么是样板,要么以有限的方式对应于描述中的特定关键字
Our proposal
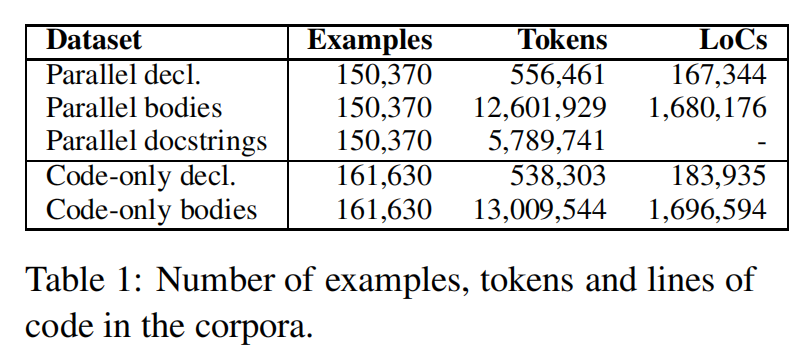
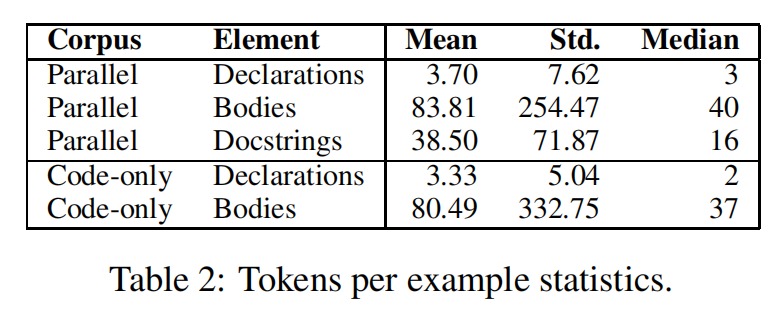
因此作者提出了包含了一条“docstring”的代码语料库,只提取最高层次的函数,添加了元信息(仓库所有者,仓库名等)可以重建上下文关系图
Dataset

Baseline results


