论文地址:Unsupervised Translation of Programming Languages
论文实现:https://console.cloud.google.com/marketplace/details/github/github-repos
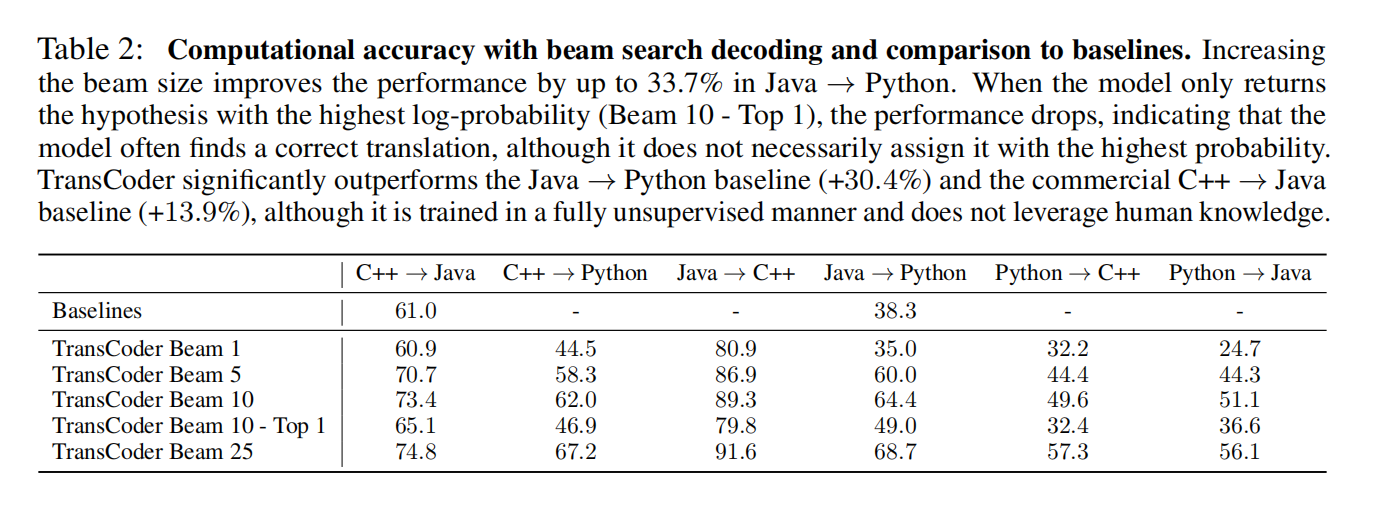
TransCoder:代码转换翻译
Abstract
转换编译器将用过时或不弃用的语言(例如cobol,Python2)编写的代码库移植到现在流行语言的代码库中,过去的方法多是采用基于规则的模板方法,而且经常出错需要有对两种语言都非常了解的人来修正成本很高。目前神经网络模型能够大幅提高上下文的表达效果,所以使用C++,python,java三种语言的并行数据进行无监督训练
Introduction
新的语言通过提供新的特性,解决了目标语言的一些缺点,如列表理解(CoffeeScript)、面向对象编程和类型检查(TypeScript),同时检测错误并提供优化,所以本文主要是将过时的语言转换为新语言
主要贡献:
- 一种基于单语言的将函数转换语言的新方法
- TransCoder能够抓取每种语言的复杂模式,且效果很好
- 创建和发布了3种语言的验证集和测试集,以及单元测试
- 代码和预训练模型开源
Model

TransCoder使用seq2seq模型,由transformer编码器解码器组成
Cross Programming Language Model pretraining
使用Cross-lingual Language Model (XLM)在单语言源代码数据集上进行掩码语言建模预训练
跨语言特性来自于跨语言的大量公共标记(锚点),比如语言翻译的数字,城市或人名等,在编程语言就是一些关键词比如if,while,try这些
Denoising auto-encoding
XLM预训练允许seq2seq模型生成高质量的输入序列表示。然而,解码器缺乏翻译的能力,因为它从未被训练成基于源表示来解码序列,为了解决这个问题,使用去噪自动编码(DAE)
DAE目标能训练模型生成有效函数,并且提高对噪声的鲁棒性
Back-translation
在实践中,仅XLM预训练和去噪自动编码就足以生成翻译,但是效果差,加上反向翻译效果好很多
在无监督设置中,源到目标模型与反向的目标到源的模型是并行训练的
Experiment