Zecoler:预训练提示学习做零样本学习
Abstract
学习代码表征是很多智能代码任务(代码搜索,克隆检测等)的先决条件,但像CodeBERT一样收集大量数据是高开销的,而且在一些数据少的特定领域比如智能合约是不可行的,因此作者提出了Zecoler,一种zero-shot的方法来学习代码表征,主要是在原始输入中插入可学习的提示模板,然后再用提示学习技术通过仅仅调整远数输入来优化预训练模型,使得在数据稀少的领域能使用到预训练知识,在Solidity和Go语言三个任务上不用训练数据做了实验
Introduction
目前的SOTA方法依赖于大量数据,但是标注数据稀少且贵,而且对于新兴语言比如Solidity不友好,这限制了监督数据和方法,一种解决办法就是通过预训练模型(PLM),但是代理任务在不同下游任务有局限性,比如MLM不能用在代码搜索,这导致先验知识的重用性在微调阶段降低,而且预训练模型在小数据上容易过拟合
本文提出Zecoler采用提示学习,通过PLM输入的可训练提示标记,将下游任务适应到与预训练时相同的形式,这样可以在预训练阶段最大化利用先验知识
主要贡献:
- 第一个提出zero-shot代码表征学习
- 提出了基于方法的代码表征提示学习
- 做了很多实验
Approach
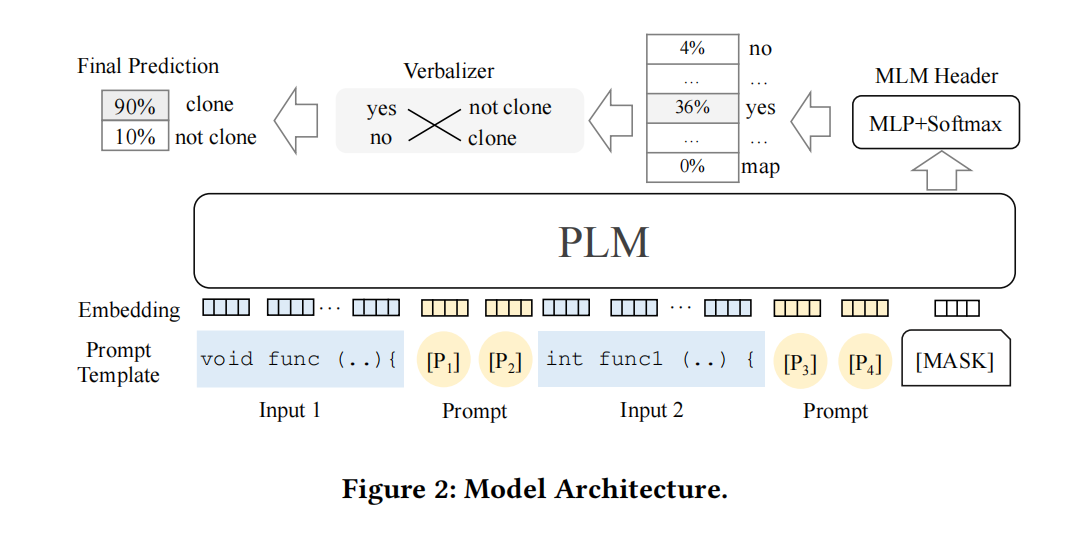
首先,在任务的输入中插入可训练的提示和一个[MASK](3.3),将任何下游任务强制转换为预训练(MLM),将得到的数据作为输入,然后使用MLM任务,然后预测[MASK](3.4),最后使用一个语言表达器将预测的单词强制转换为类标签(3.5)
Casting Downstream Tasks into MLM
给两个片段 $x_1$ 和 $x_2$ ,输入是 $\tilde{x}=[CLS];x_1;x_2;[MASK]$ ,然后通过PLM
Prompt-based Learning
设计了一系列的提示词 $P=[P_1,…,P_m]$ ,通过一个定义好的模板 $T=[P];x_1;[P];x_2;[P];[MASK]$ 插入到遮蔽过的序列 $\tilde{x}$ ,原始输入就变为
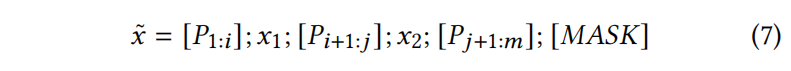
比如代码克隆检测给两个代码,输入就变成
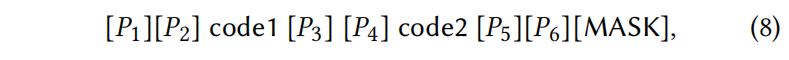
这样包含了6个可训练的提示
和普通词汇一样,提示词也被嵌入到可学习向量空间通过梯度下降优化
Reverting MLM Outputs to Classification Labels
将MLM的预测还原为下游任务的分类标签,使用了一个词汇表达器来实现这样的还原,我们只考虑两个候选词{yes,no},如果PLM预测更接近yes词汇表达器就映射到标签“true”
Experiment
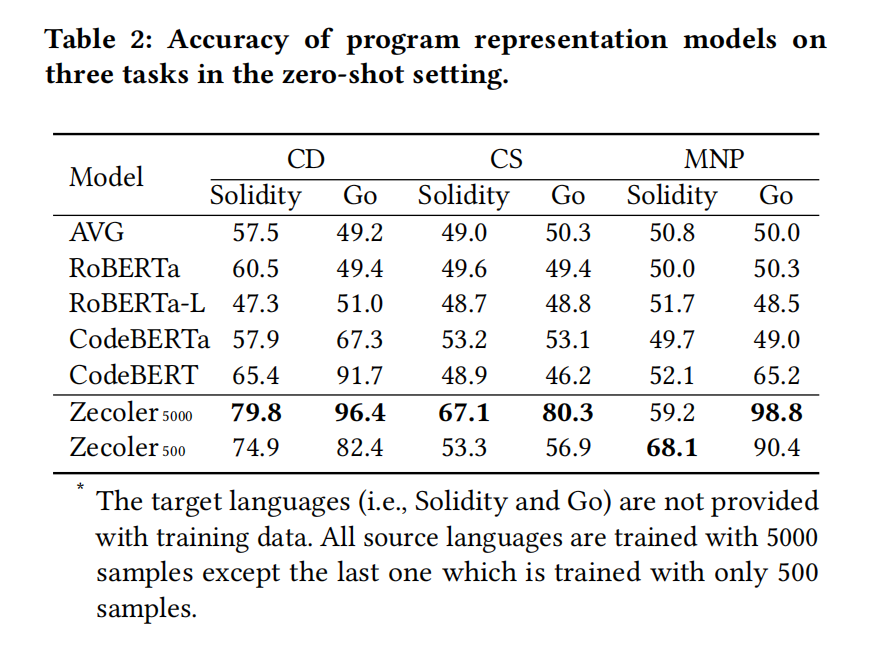
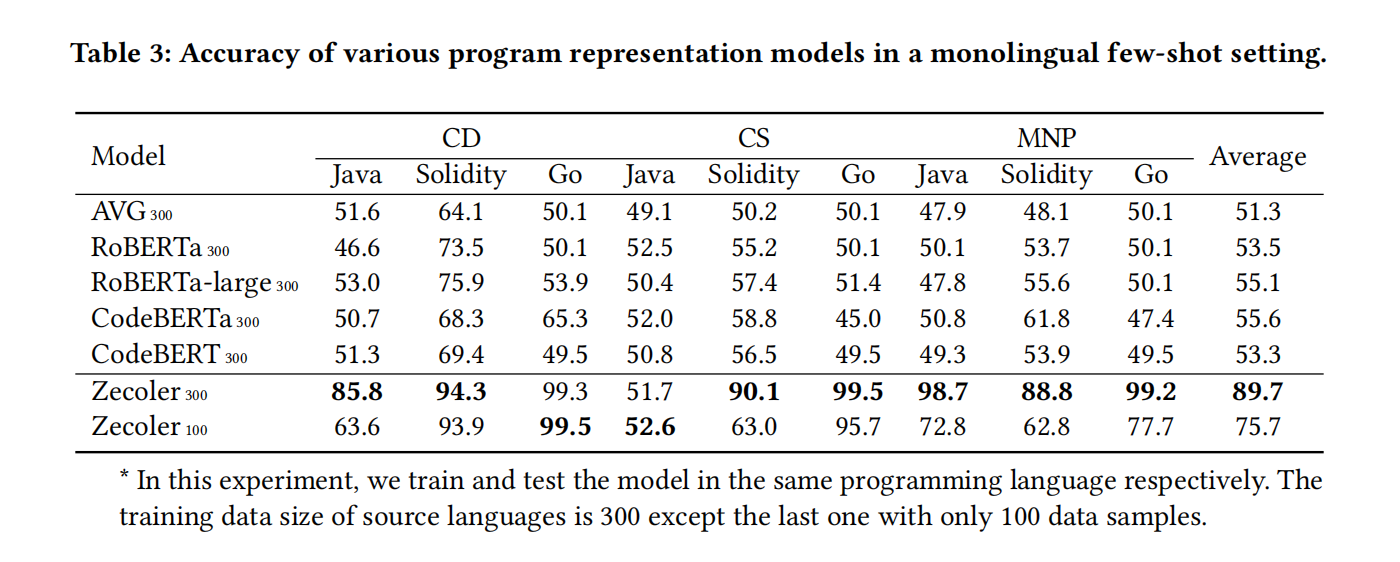
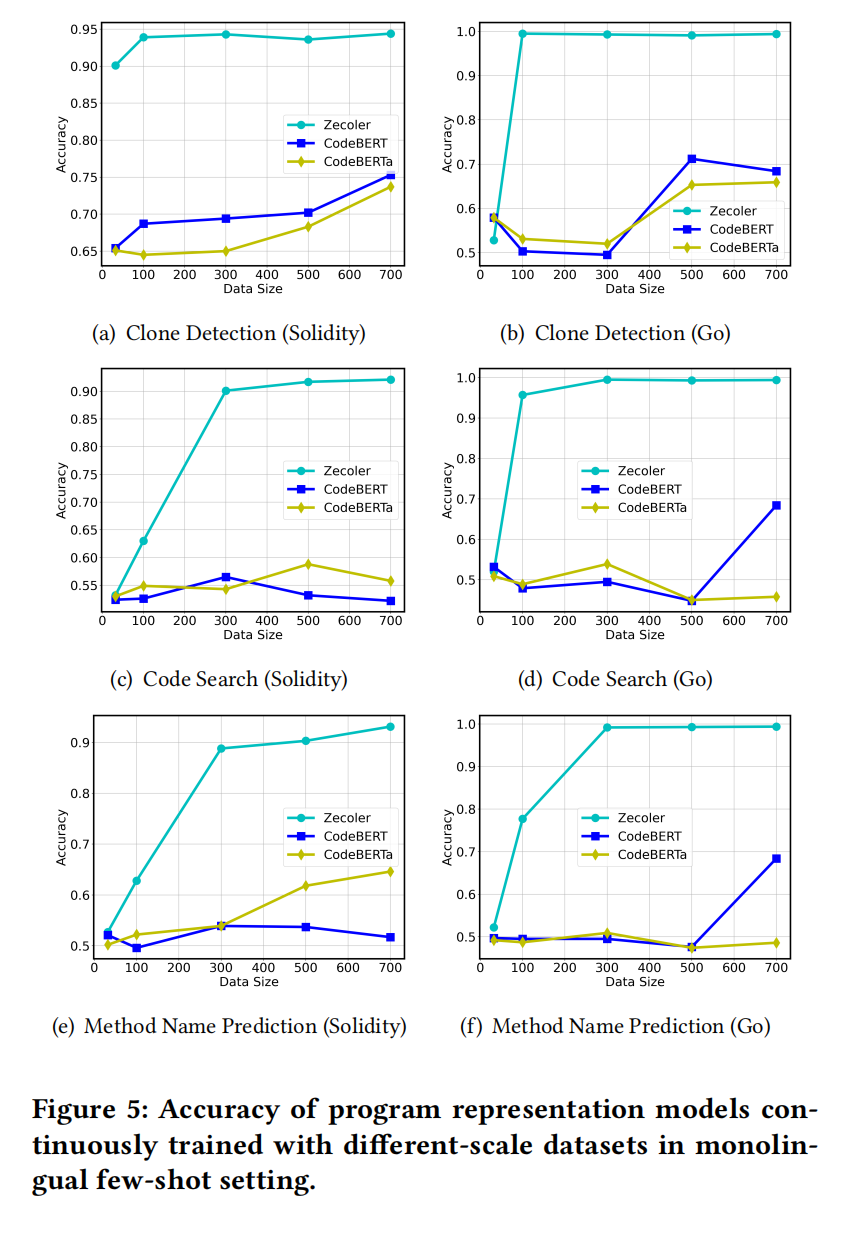
初始对每个任务训练表征模型使用java数据,用5000个和500个Java数据样本来训练模型,以评估不同数据大小下的影响