论文地址:ViLT:Vision-and-Language Transformer Without Convolution or Region Supervision
论文实现:https://github.com/dandelin/ViLT
没有使用目标检测的region featrue,简化流程,训练昂贵效果略有下降,但是极大的减少了推理时间
ViLT:拓展VIT到多模态学习
Abstract
视觉和语言预训练(VLP)在视觉和语言下游任务上有极大的提升,而往往视觉方面花的时间越多最终效果会更好,所以大部分VLP方法都非常依赖特征抽取过程,或者看作一个目标检测问题加上ResNet卷积架构。有两个主要问题:1. 抽特征比多模态融合花太多时间;2. 表达能力受限于嵌入和预定义好的视觉词表。所以提出了ViLT,极简化的设计
Introduction
多模态的VLP用上预训练再微调策略后发展很快,一般模型都是用图像文本对预训练,用图像文本匹配和MLM做目标函数(基本所有模型都用到了),再在下游任务双模态中微调
输入VLP的时候不能把像素扔进去,要把像素和词元一起嵌入成离散的高层语义特征才能做transformer,所以大部分工作都依赖于目标检测器(因为1. 目标检测出来的region就是天然的带有语义的离散表示;2. 下游任务比如VQA,如果物体和任务是高度相关依赖的),所以覆盖的类别数越多好越好,图像文本才能匹配更好
但用目标检测抽特征太贵,所以一部分工作在下降这个成本,比如Pixel-BERT用在ImageNet训练好的ResNet网络抽特征图当作离散序列,这样计算量就只有backbone,没有目标检测的任务
但即使这样还是需要一个图像抽取过程,比较耗时,也是受到了VIT的启发,打成patch之后再抽特征
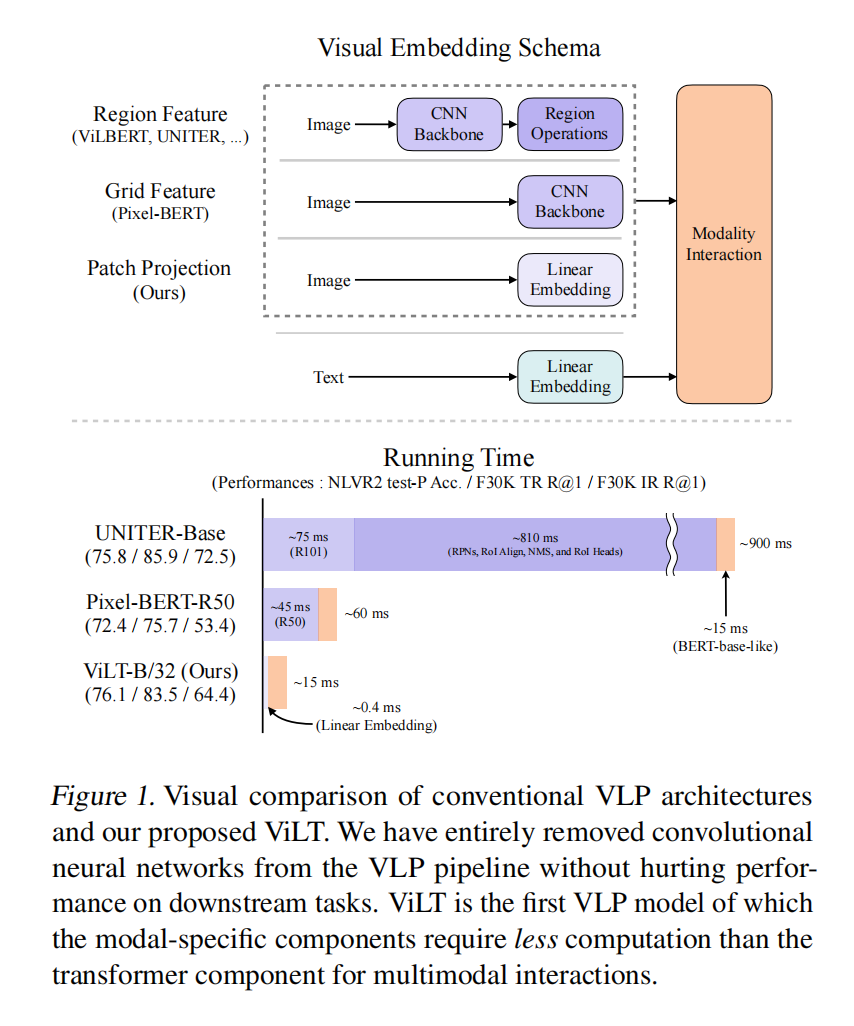
之前表现好的都是区域特征的一些模型,抽出物体特征;然后就拿掉目标检测这个过程,使用网格特征;ViLT就类似VIT把backbone换成了一个可学习的线性层,非常快,结果也有竞争力
主要贡献:
- ViLT是迄今为止最简单的架构,带来了显著的时间提升和参数减少
- 不使用区域特征或残差网络性能损失也小
- 第一个在VLP使用图像增强
Background
Taxonomy of Vision-and-Language Models
根据1. 图像和文本表达力度,参数平不平衡;2. 模态怎么融合;分为了四个类
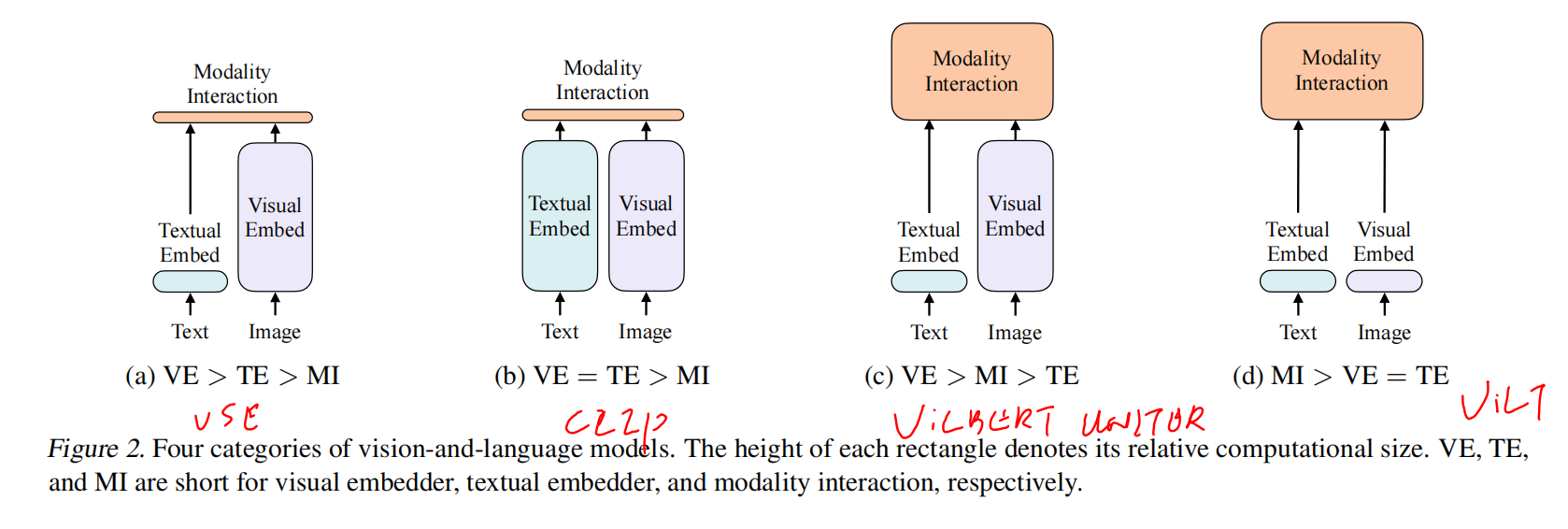
Modality Interaction Schema
singale-stream:把两个序列concat起来学习交互;dual-stream:先各自处理挖掘信息再融合
很多时候dual-steram好一些,但是引入了更多的参数
Visual Embedding Schema
Region Feature
给定一个图像时通过Backbone,NMS和RoI head
Grid Feature
使用便宜,但是相对比较贵而且性能下降厉害
Patch Projection
类似ViT打patch
Vision-and-Language Transformer
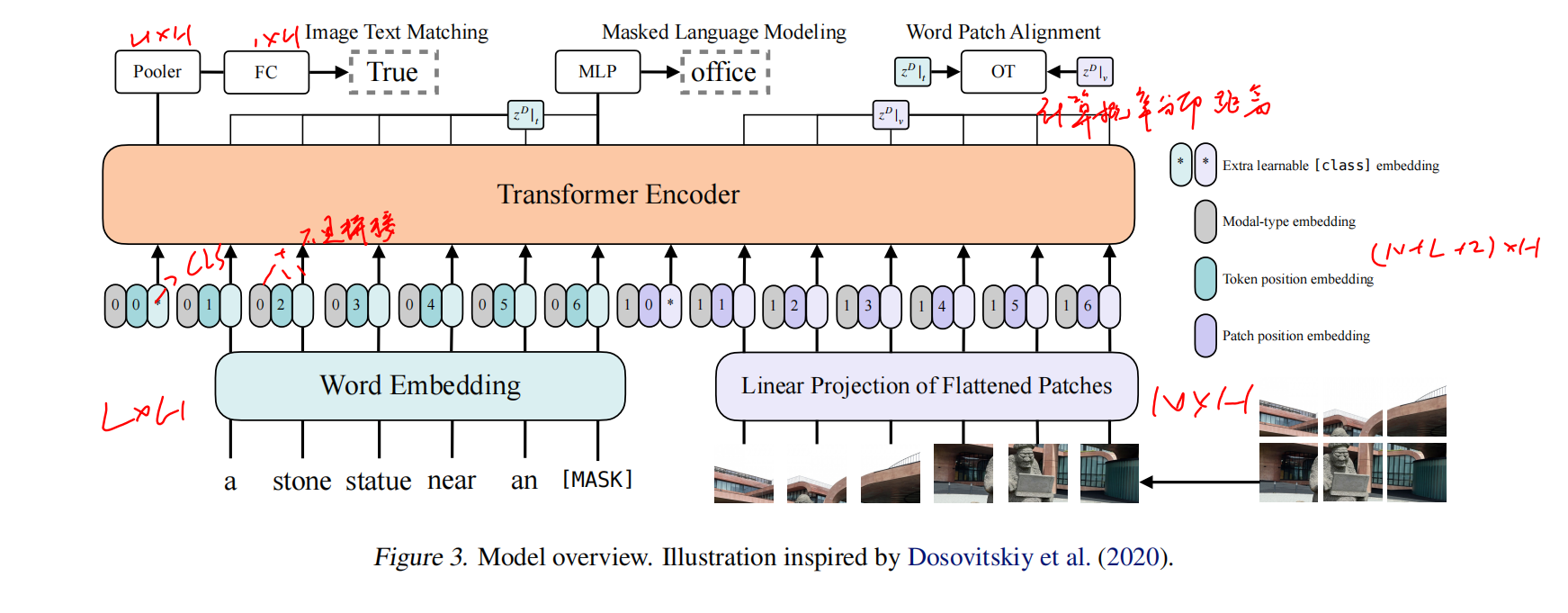
Whole Word Masking
比如把giraffe分词成三个词元[gi, ##raf, ##fe],然mask掉中间的词,模型其实很容易就学习到中间这个词,因为在gi和fe中间的词本身就不多,记住就好,这样就太简单而且也没从图像中学习到有用的信息,不如把整个词都给mask掉,让模型从图像中去重建这个长颈鹿的文本信息
Image Augmentation
之前多模态的那些方法没法用数据增强,因为都是提前抽好特征存硬盘的,做了增强还要重新抽特征
作者用了randAugment,但是颜色变换和裁剪没用,因为这个变了文字肯定也变了
Experiment
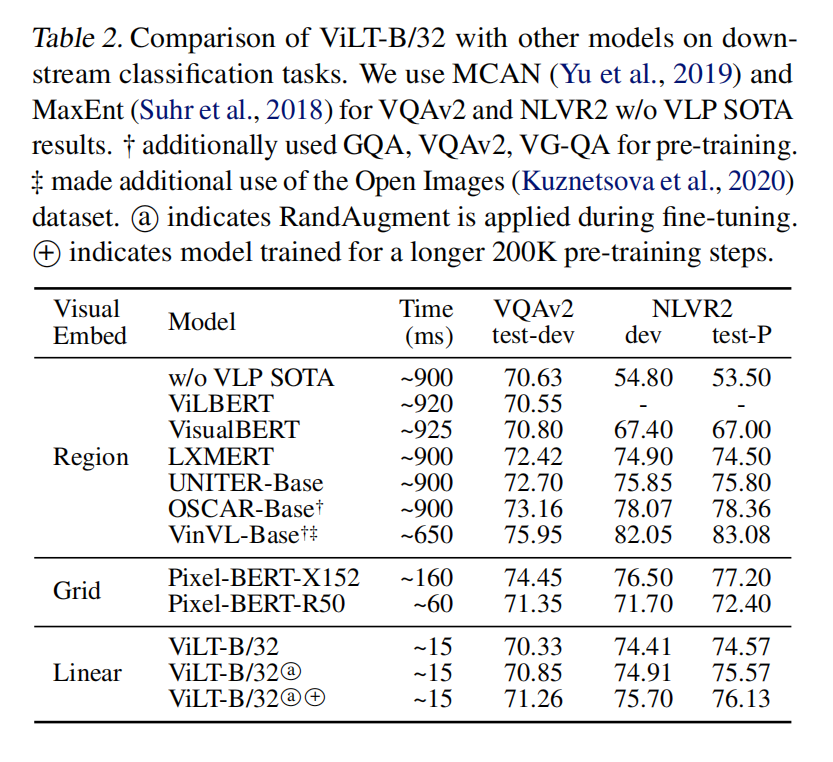
用了区域的结果还是比较好的,但是ViLT做了速度和精度的tradeoff
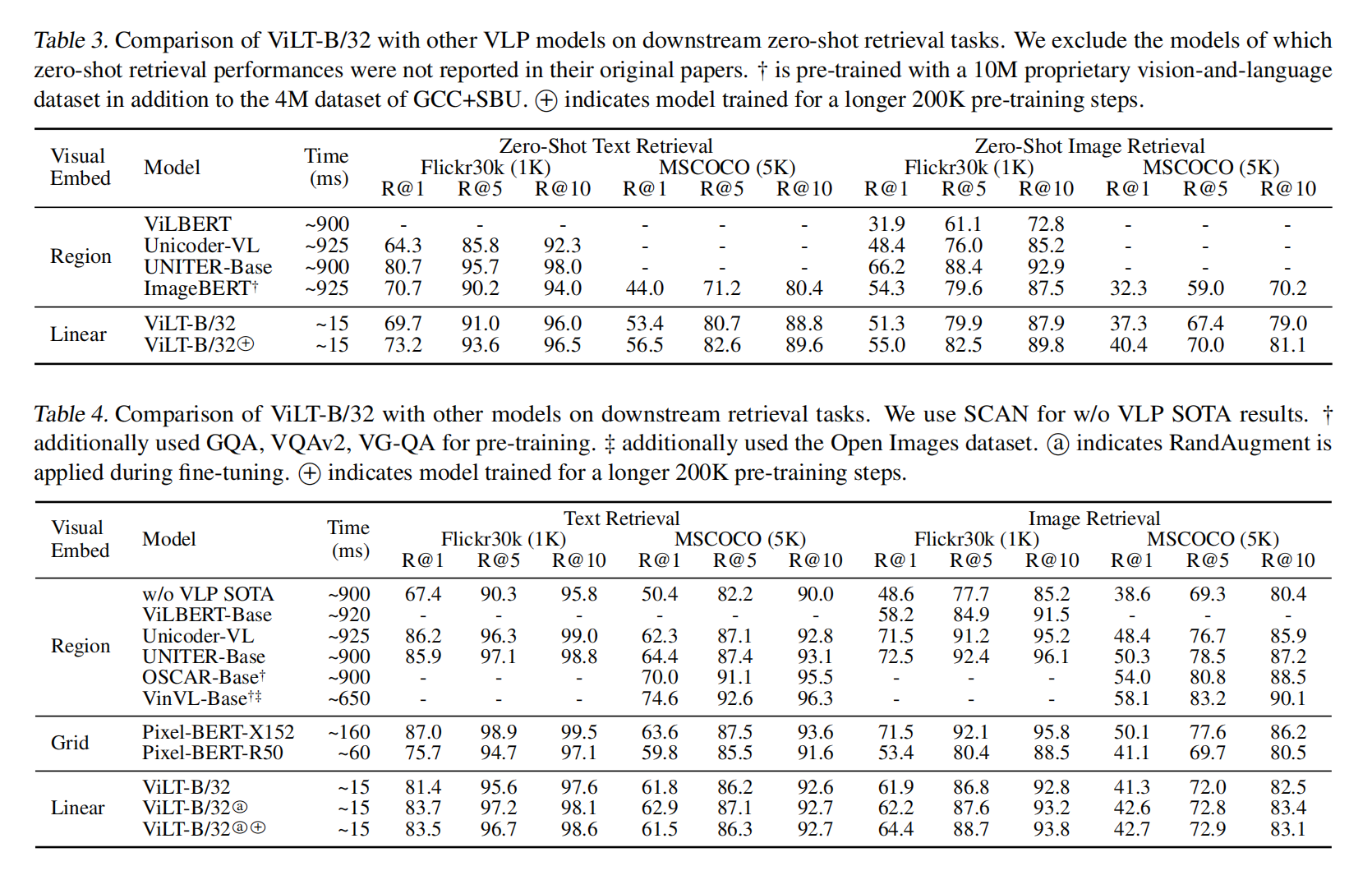
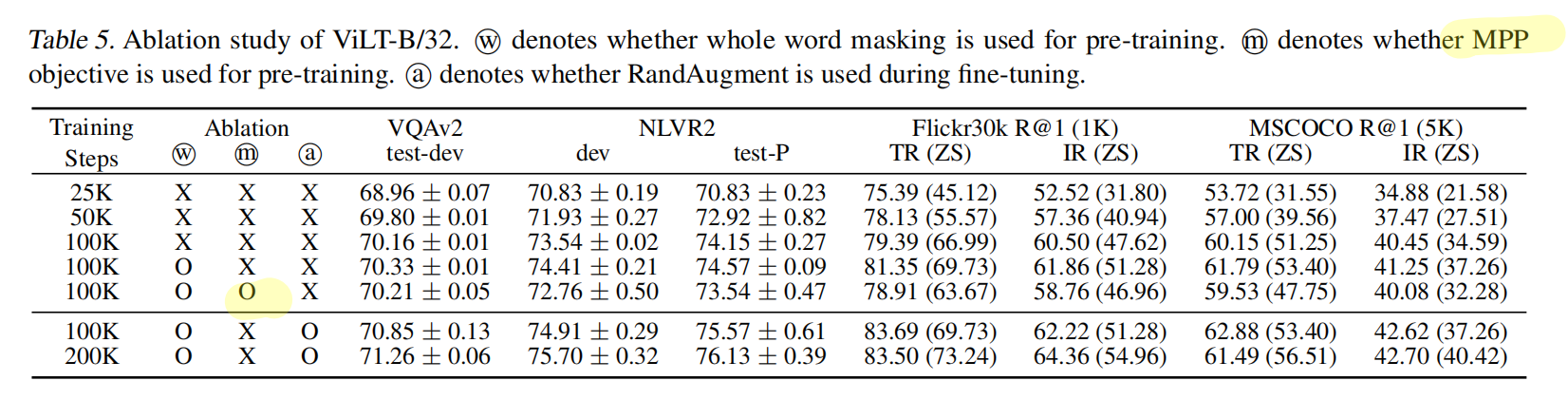
作者这里用了图片mask叫做MPP,但是没啥用,后面的文章的trick才证明这个方法有用
Conclusion and Future Work
Scalability:越大越好;Masked Modeling for Visual Inputs:做图像重建;Augmentation Strategies:提升很大

