论文地址:CODE-MVP:Learning to Represent Source Code from Multiple Views with Contrastive Pre-Training
CODE-MVP:多视图对比学习
Abstract
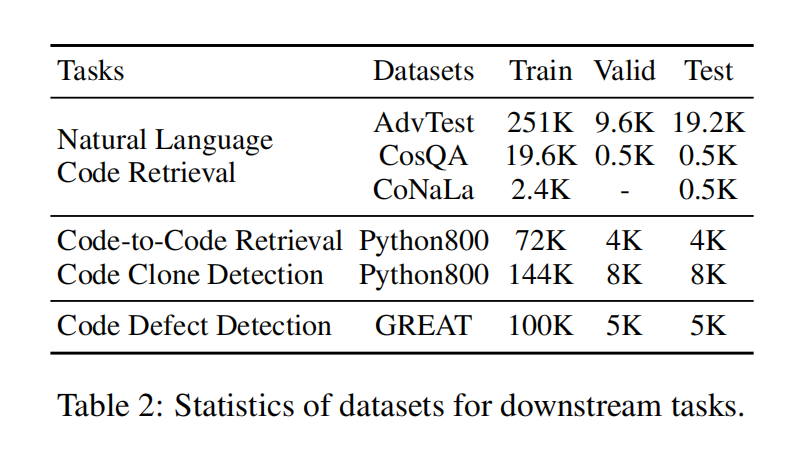
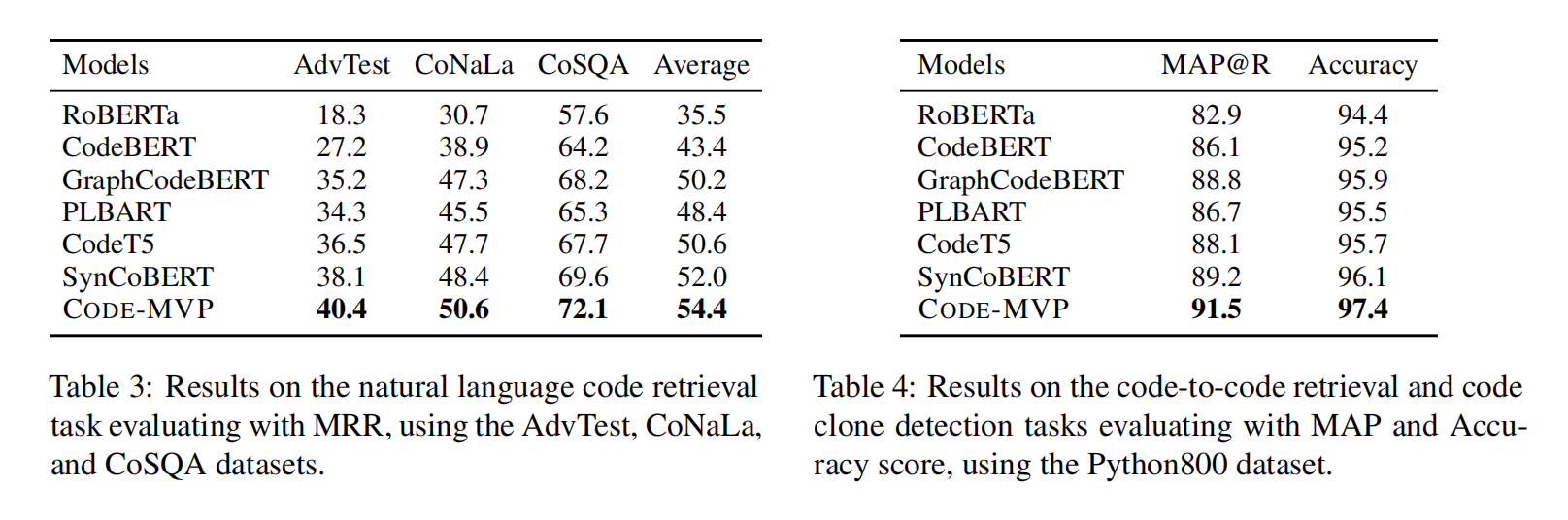
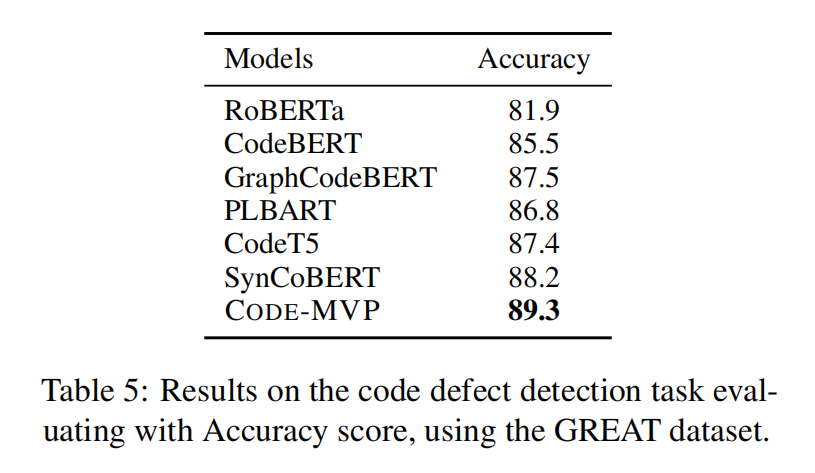
现有学习代码表征的方法有很多,比如纯文本,AST,代码图,但大多数都只关注了一种代码视图,忽略了不同视图下的联系,所以本文提出将不同的视图与源代码的自然语言注释集成到一个统一的框架与多视图对比预训练,叫做Code-MVP,用编译工具提取不同的代码视图,然后用对比学习学习互补的信息。在三个下游任务五个数据集上取得SOTA
Introduction

现有的方法主要代表来自不同代码视图的源代码,包括纯文本中的代码标记、抽象语法树(AST)和代码的控制/数据流图(CFGs/DFGs),此外还有一些训练掩码语言模型的工作
不同视图往往有互补的语义信息,比如源代码词元(例如,方法名称标识符)和注释总是显示代码的词汇语义。而代码中间结构,比如AST和CFG揭示句法和执行信息。一个程序还可以改写成同样功能的不同变体,这反应程序的功能信息表达同一语义
主要贡献:
- 第一个对比学习用不同视图来表示代码,包括词元,AST,CFG和不同程序变体
- 做了很多实验在代码检索,相似度和缺陷预测任务上
Multiple Views of Code
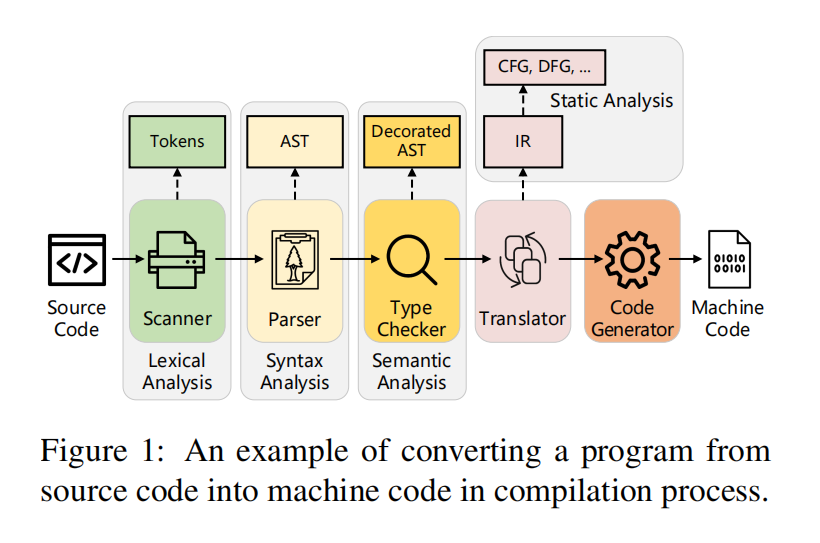
上图表示了一个程序转化为机器码的过程
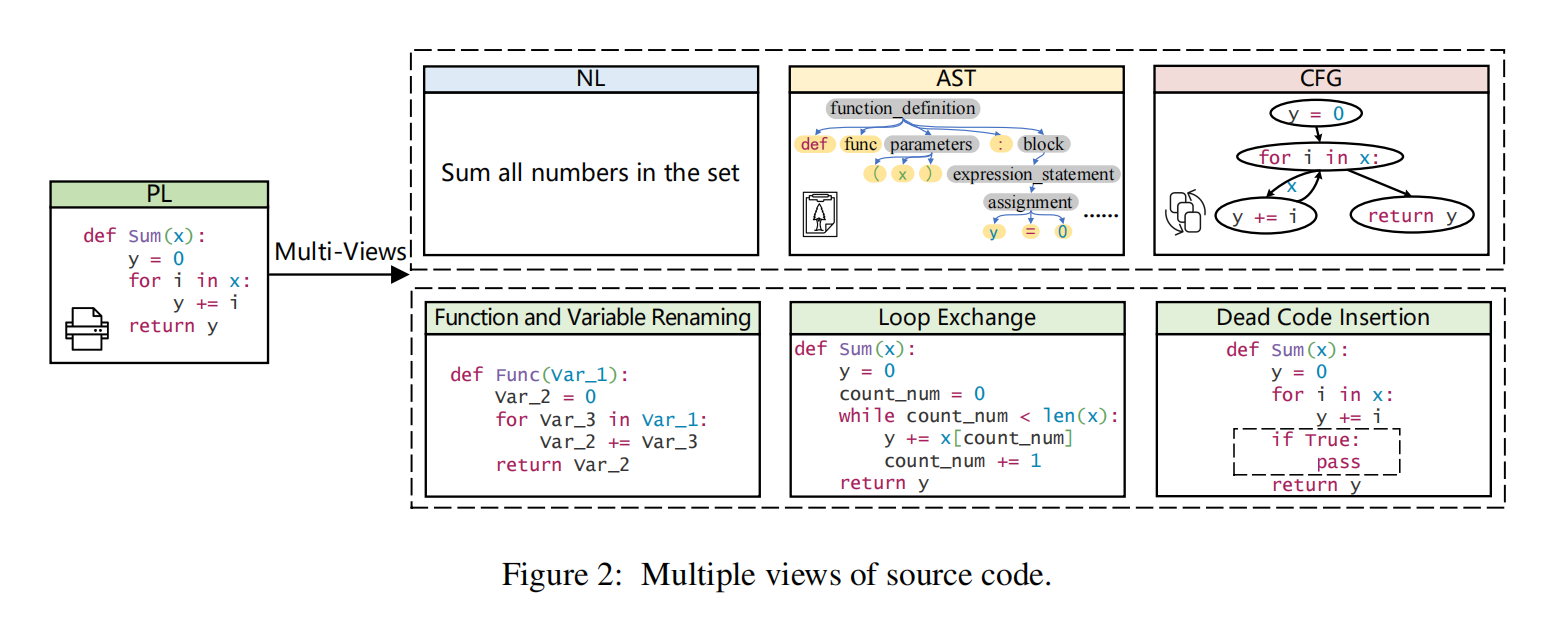
作者使用的不同视图如图2所示
Code-MVP
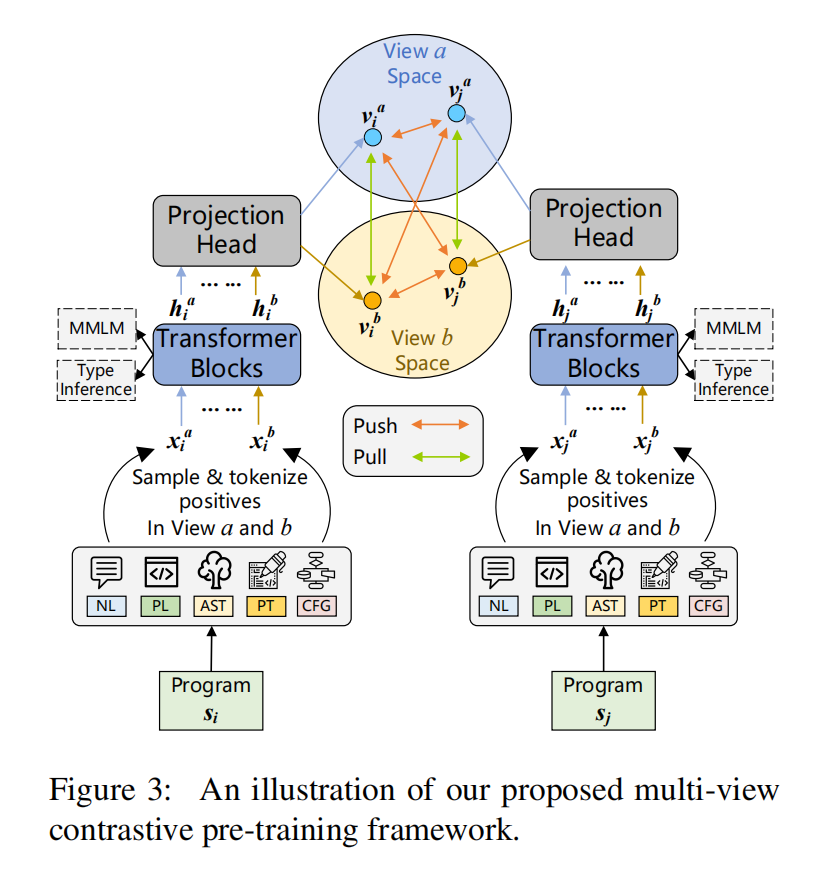
Multi-View Contrastive Learning
用成对数据和非成对数据来训练,成对数据是有自然语言的,非成对数据是没有自然语言的,对这两种情况分别构建正负样本
Multi-View Positive Sampling
设计了Single-View(针对成对和非成对数据)和Dual-View(只针对成对数据,需要NL)
- Single-View:来自一个程序的两个不同视图形成视图间的正对,输入是 $x_i^a={
,s_i^a}$ 和 $x_i^b={ ,s_i^b}$ - Dual-View:提出了NL条件双视图对比预训练策略,冻结了NL的位置,输入是 $x_i^a={
,S_i^{NL}, ,s_i^a}$ 和 $x_i^b={ ,S_i^{NL}, ,s_i^b}$
可以注意的是这里可以输入很多不同种的组合构建正样本对,本文只考虑了以下:
- Single-View:NL vs PL,NL vs PT,PL vs AST,PL vs CFG,PL vs PT
- Dual-View:NL-PL vs NL-AST,NL-PL vs NL-CFG,NL-PL vs NL-PT
Multi-View Negative Sampling
使用小批量和交叉小批量策略构建视图内和视图间负样本,对于每个样本的每个视图会有2N-2个负样本
Pre-Training with Type Inference
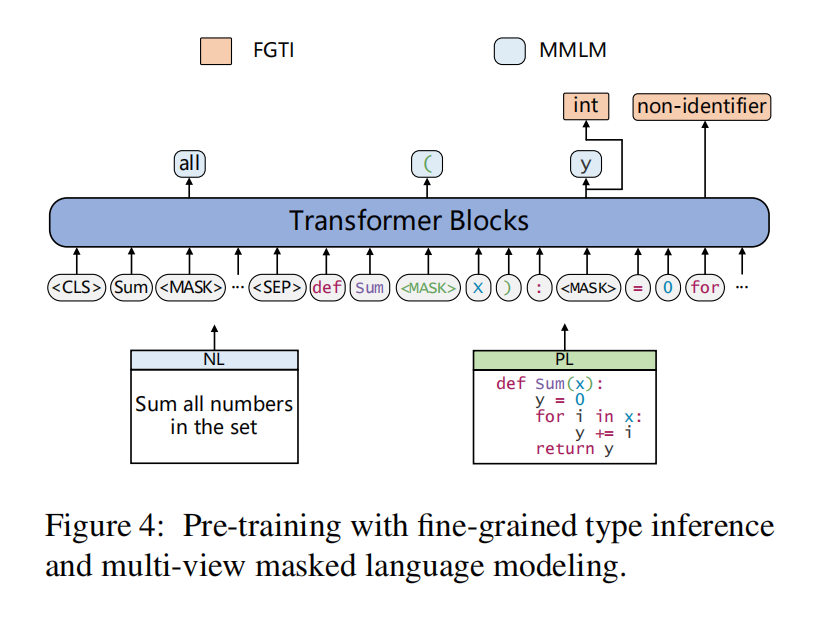
两阶段的预训练任务,类型推理和多视图掩码语言模型
Overall Training Objective
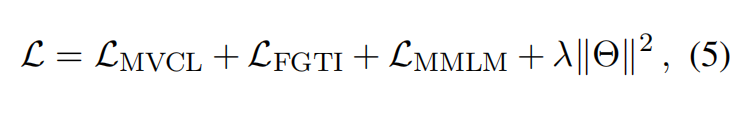
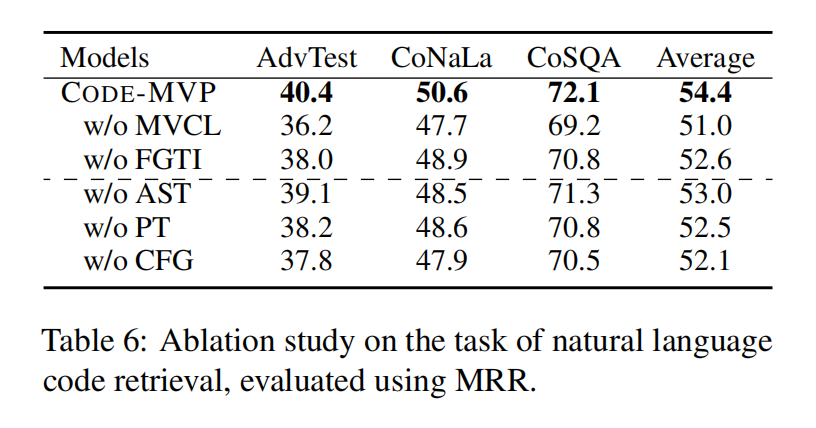
Experiment