RoBERTa:BERT升级版
Abstract
BERT训练昂贵并且大多在不同大小的私有数据集上训练,超参数的选择对最后的结果有很大的影响。本文展示了一个BERT的重复性实验研究,衡量了不同关键参数和训练数据大小的影响,可以发现BERT是明显训练不足的,性能还能提升
Introdcution
作者发现BERT明显训练不足,并提出了一个训练BERT模型的改进配方,称之为RoBERTa,可以匹及或超越所有的BERT模型,主要包含以下修改:
- 训练模型更长的时间,更长的批次,超过更多的数据
- 去除下一个句子预测目标
- 对更长的序列进行训练
- 动态地改变应用于训练数据的掩蔽模式
Training Procedure Analysis
Static vs Dynamic Masking
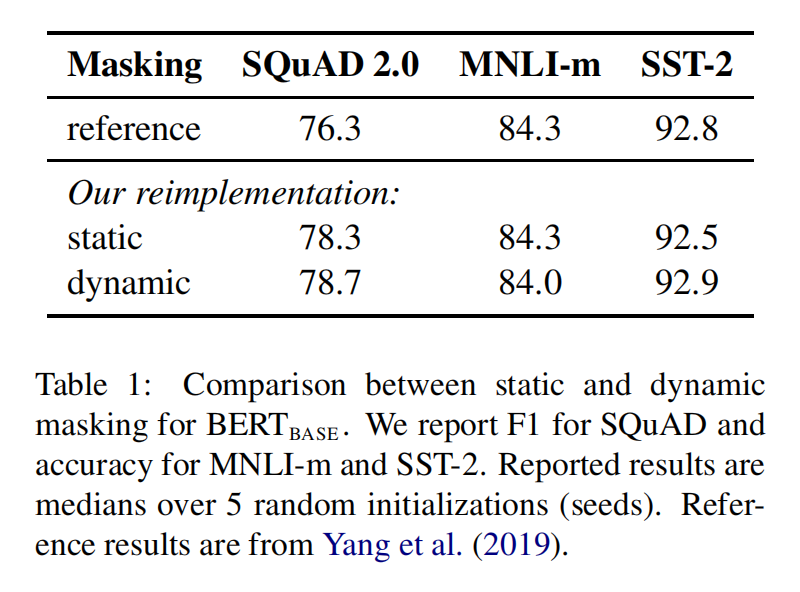
-
原始静态mask:
- BERT中是准备训练数据时,每个样本只会进行一次随机mask(因此每个epoch都是重复),后续的每个训练步都采用相同的mask,这是原始静态mask,即单个静态mask,这是原始 BERT 的做法
-
修改版静态mask:
- 在预处理的时候将数据集拷贝 10 次,每次拷贝采用不同的 mask(总共40 epochs,所以每一个mask对应的数据被训练4个epoch)。这等价于原始的数据集采用10种静态 mask 来训练 40个 epoch
-
动态mask:
- 并没有在预处理的时候执行 mask,而是在每次向模型提供输入时动态生成 mask,所以是时刻变化的
Model Input Format and NSP
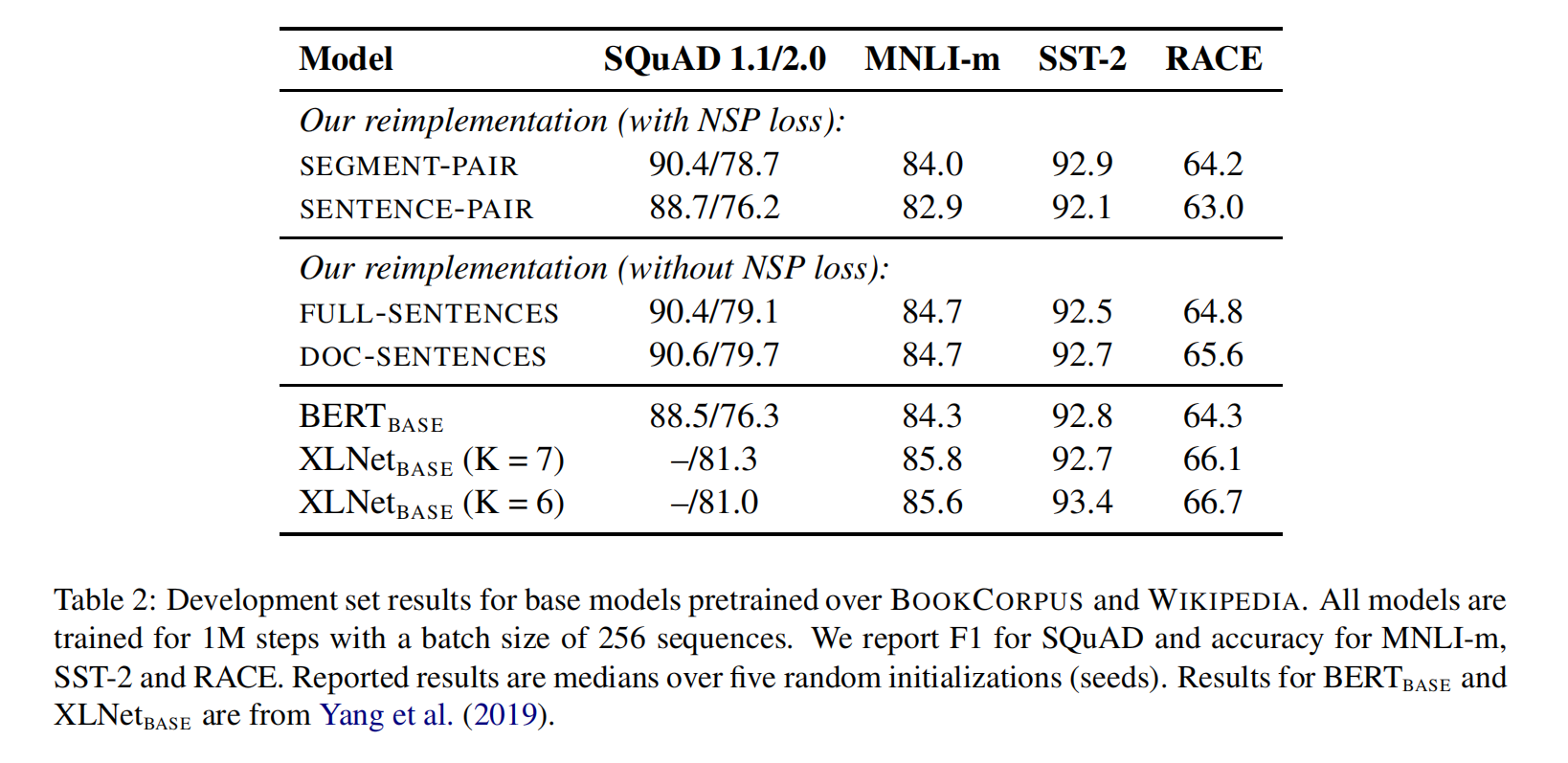
与原始BERT相比,去掉NSP损失能够使得下游任务的表现持平或略微升高。所以原始 BERT 实现采用仅仅是去掉NSP的损失项,但是仍然保持 SEGMENT-PARI的输入形式的训练方式是可能的
-
SEGMENT-PAIR + NSP:
- 输入包含两部分,每个部分是来自同一文档或者不同文档的 segment (segment 是连续的多个句子),这两个segment 的token总数少于 512 。预训练包含 MLM 任务和 NSP 任务。这是原始 BERT 的做法。
-
SENTENCE-PAIR + NSP:
- 输入也是包含两部分,每个部分是来自同一个文档或者不同文档的单个句子,这两个句子的token 总数少于 512 。由于这些输入明显少于512 个tokens,因此增加batch size的大小,以使 tokens 总数保持与SEGMENT-PAIR + NSP 相似。预训练包含 MLM 任务和 NSP 任务。
-
FULL-SENTENCES:
- 输入只有一部分(而不是两部分),来自同一个文档或者不同文档的连续多个句子,token 总数不超过 512 。输入可能跨越文档边界,如果跨文档,则在上一个文档末尾添加文档边界token 。预训练不包含 NSP 任务。
-
DOC-SENTENCES:
- 输入只有一部分(而不是两部分),输入的构造类似于FULL-SENTENCES,只是不需要跨越文档边界,其输入来自同一个文档的连续句子,token 总数不超过 512 。在文档末尾附近采样的输入可以短于 512个tokens, 因此在这些情况下动态增加batch size大小以达到与 FULL-SENTENCES 相同的tokens总数。预训练不包含 NSP 任务。
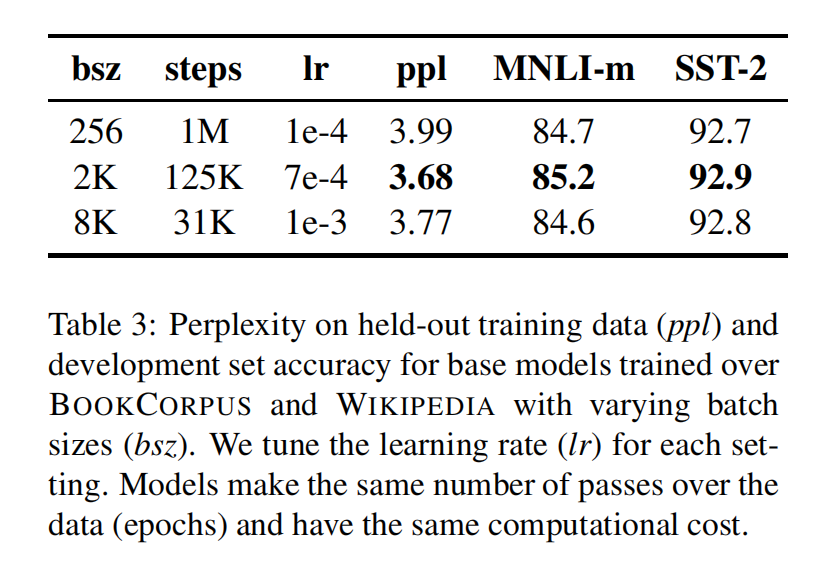
Training with large batches
Text Encoding
- 基于 char-level :原始 BERT 的方式,它通过对输入文本进行启发式的词干化之后处理得到。
- 基于 bytes-level:与 char-level 的区别在于bytes-level 使用 bytes 而不是 unicode 字符作为 sub-word 的基本单位,因此可以编码任何输入文本而不会引入 UNKOWN 标记
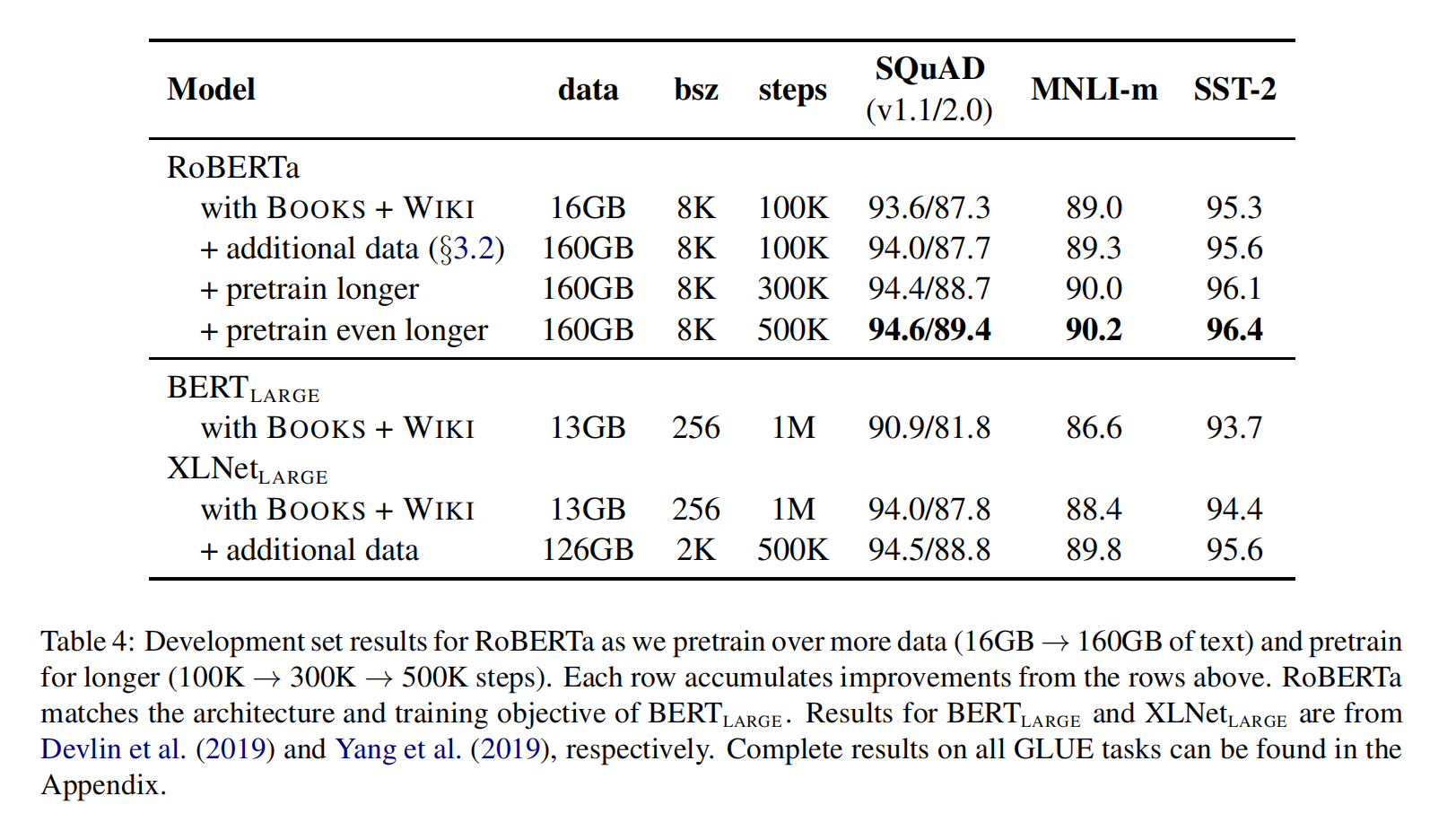
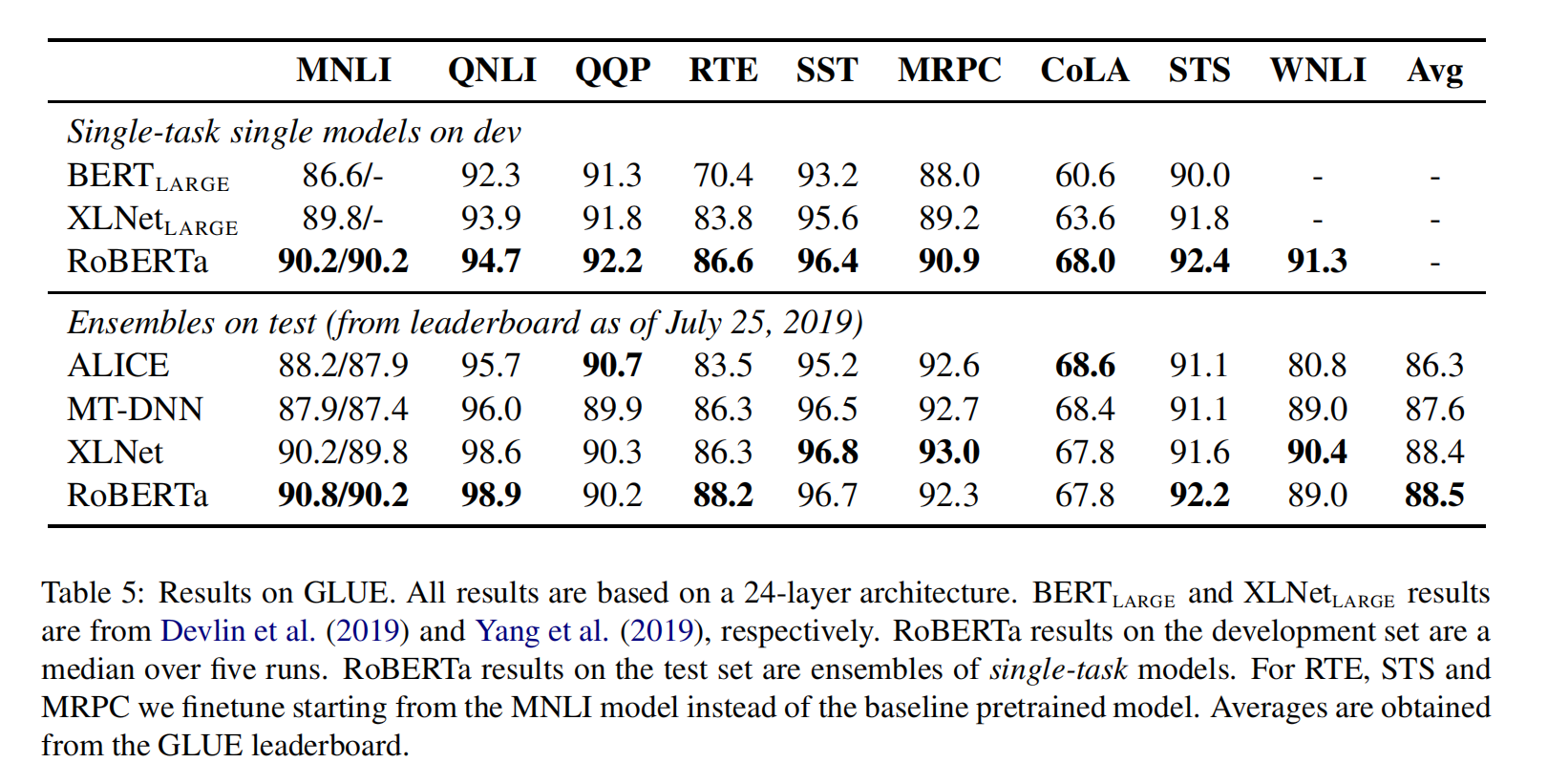
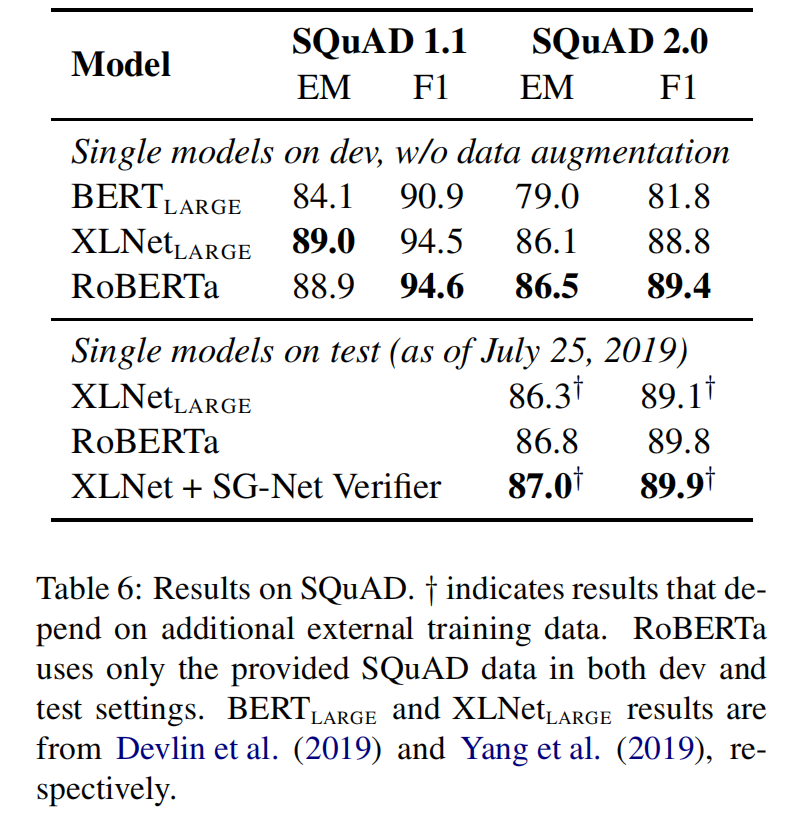
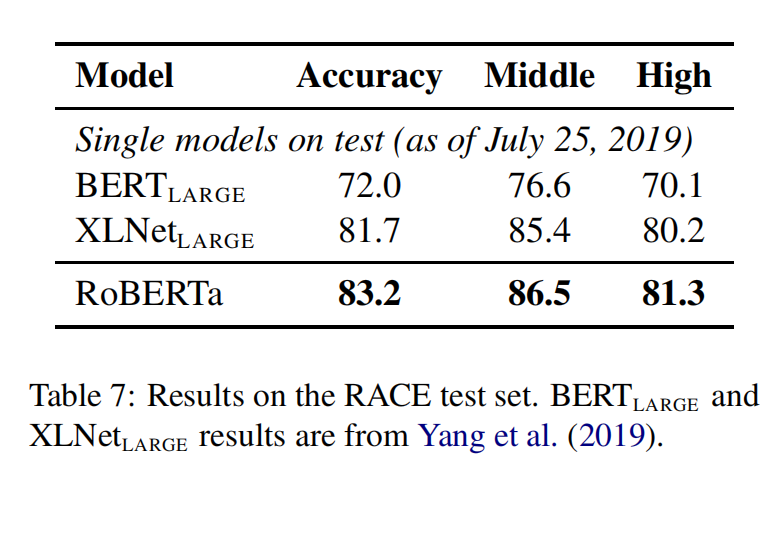
RoBERTa
RoBERTa使用dynamic masking,FULL-SENTENCES without NSP loss,larger mini-batches和larger byte-level BPE(这个文本编码方法GPT-2也用过,BERT之前用的是character粒度的)进行训练。除此之外还包括一些细节,包括:更大的预训练数据、更多的训练步数