CodeT5:完整transformer+标识符+双模态
Abstract
目前的预训练方法大多是只有编码器或解码器,本文提出统一的编码器-解码器的transformer模型CodeT5,可以支持代码理解和生成任务,此外还提出了一个标识符感知的预训练任务
Introduction
预训练模型在语言任务上取得了很大的成功,但是大多数要么依赖于只有编码器像BERT,要么只有解码器像GPT,这对于生成理解任务而言不是最优的,比如CodeBERT在代码摘要生成上需要额外得到解码器,这个解码器还不能从预训练当中获益
此外目前传统的NLP方法把原代码视作像自然语言一样的token序列。很大程度上忽视了代码的丰富的结构化语义信息
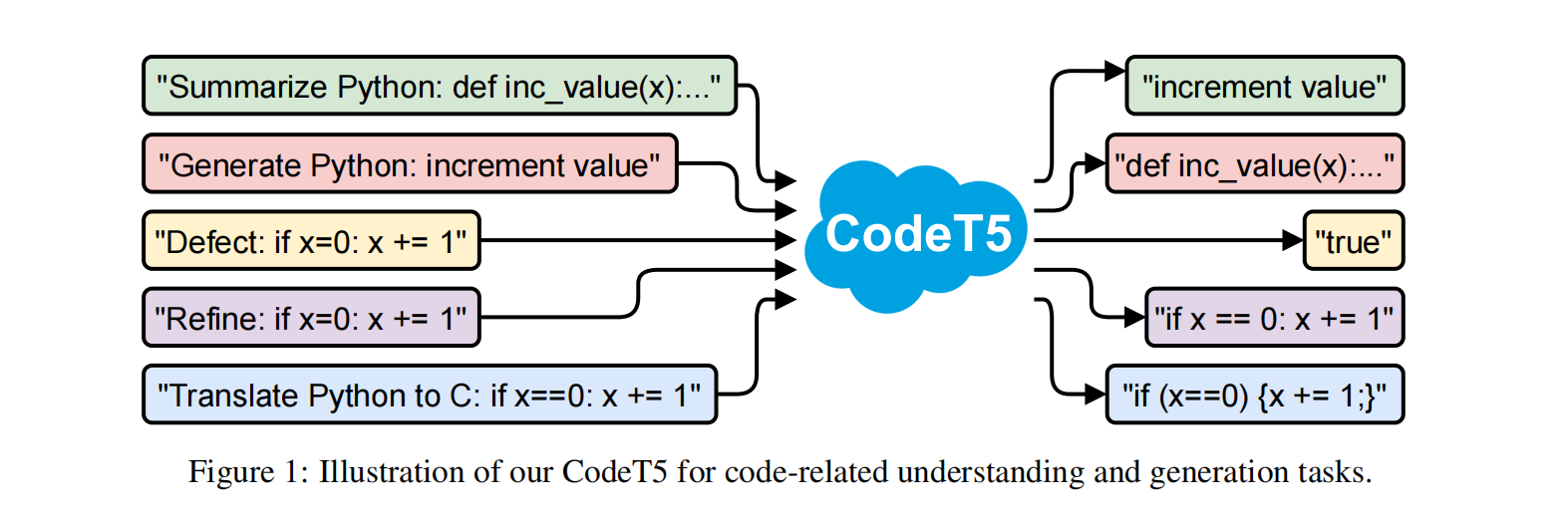
CodeT5使用降噪seq2seq预训练方法,同时利用了开发者赋值的标识符,利用代码和注释来学习更好的NL-PL对齐,使用CodeSearchNet数据集
CodeT5
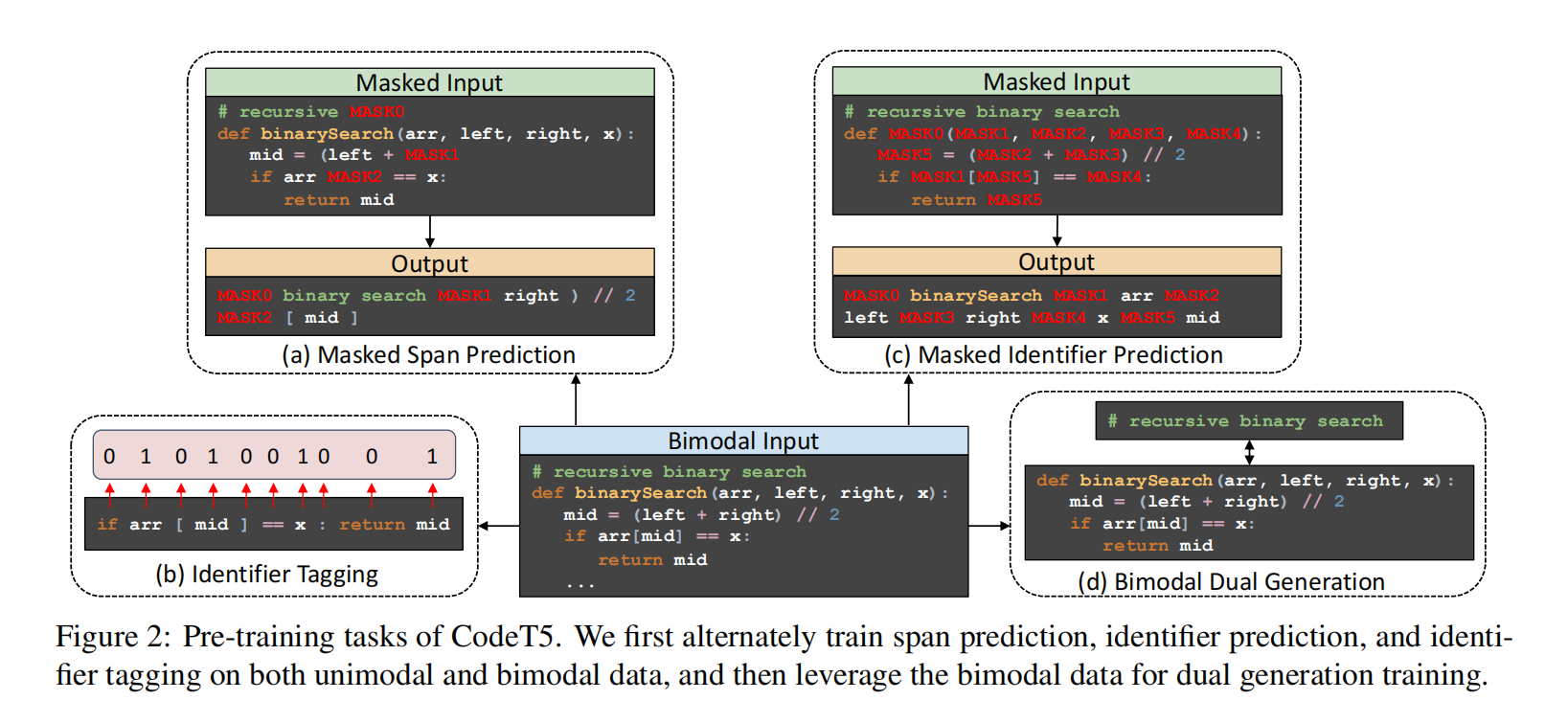
Pre-training Tasks
Identififier-aware Denoising Pre-training
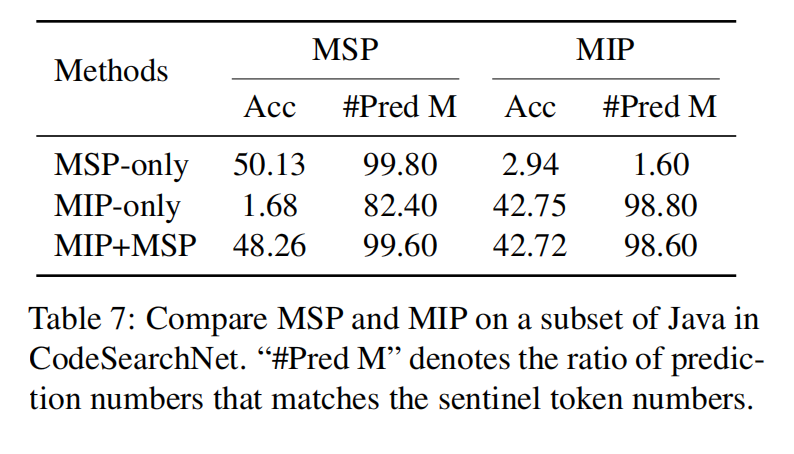
首先用一些噪声函数破坏源序列,然后需要解码器恢复原始文本,就是MSP
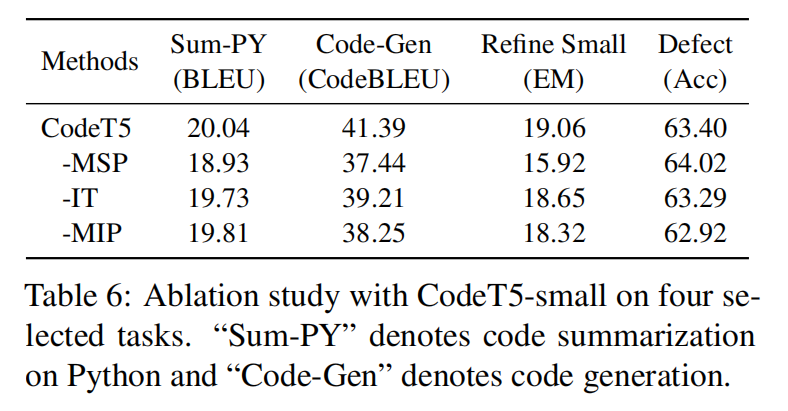
为了将更多特定于代码的结构信息(AST中的标识符节点类型)融合到模型中,提出了两个额外的任务:标识符标记(IT)和屏蔽标识符预测(MIP)来补充去噪预训练
- Identififier Tagging (IT) :告知模型这个词元是否是标识符
- Masked Identififier Prediction (MIP) :与遮蔽一段不同,MIP遮蔽代码片段中所有标识符
Bimodal Dual Generation
将NL→PL生成和PL→NL生成视为两项任务,对每对NL-PL双模态数据,构造两个方向相反的训练实例
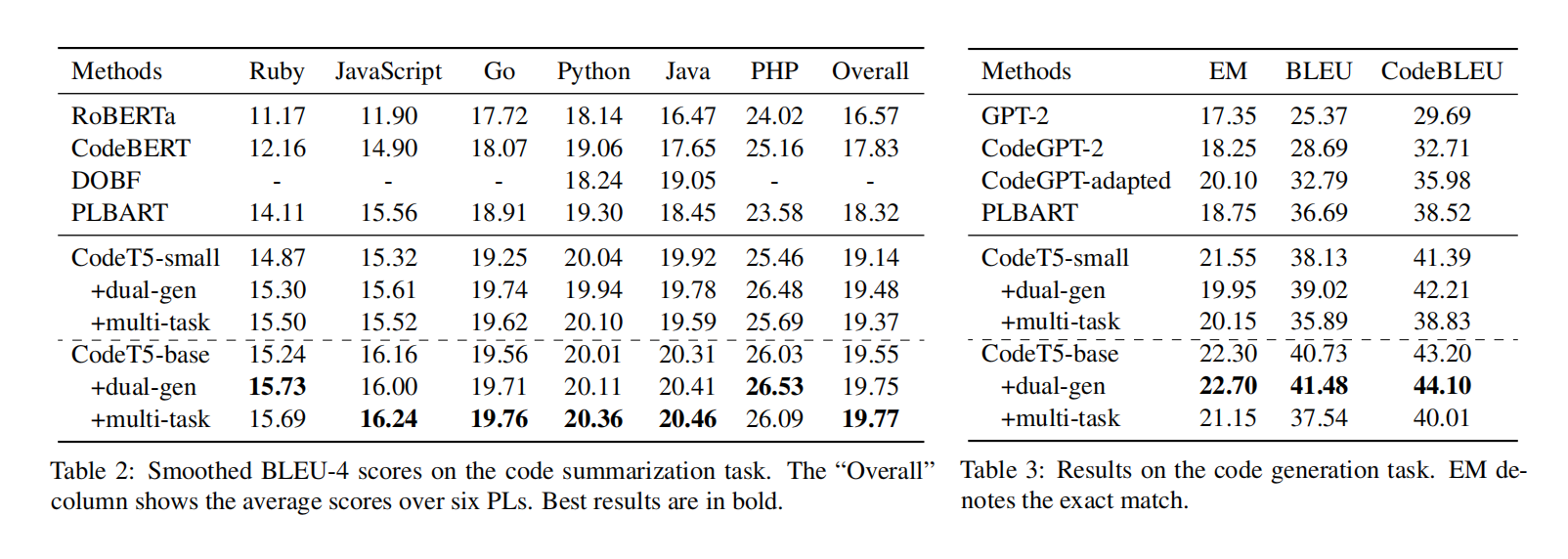
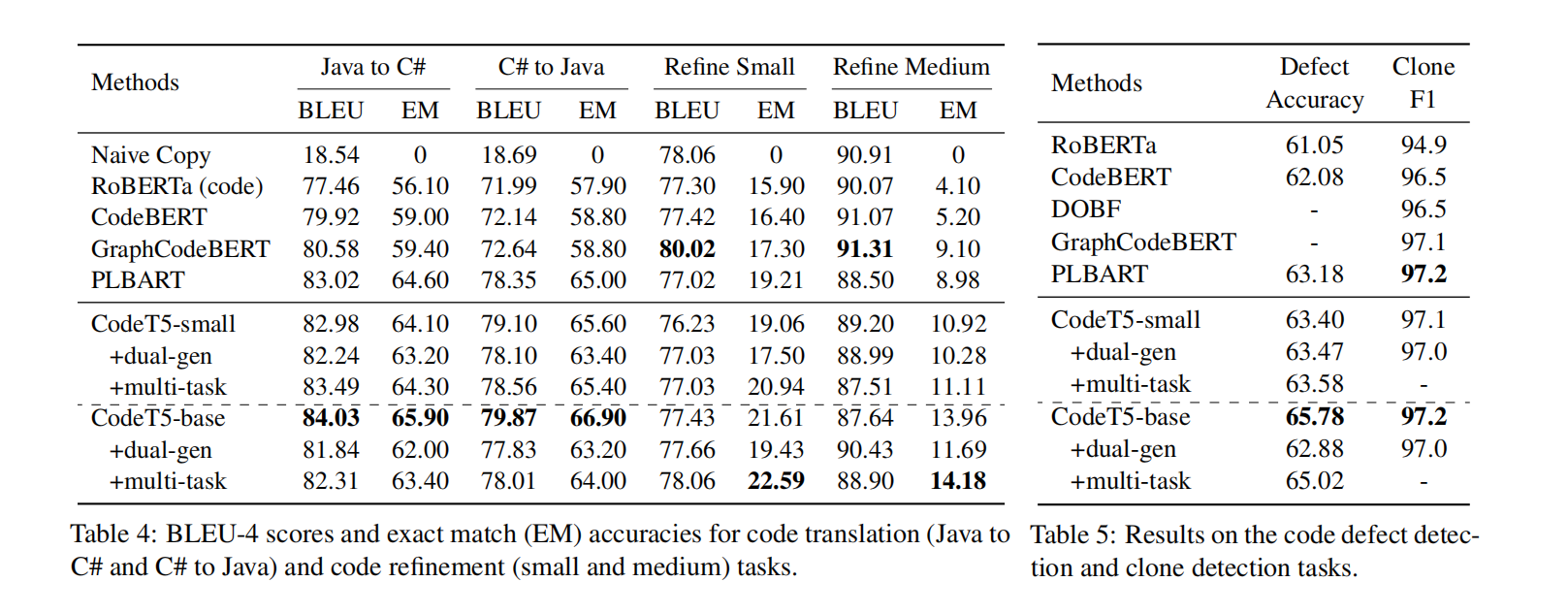
Experiment