LSeg:增加文本编码器做有监督语义分割
Abstract
把CLIP直接用在做语义分割上,使用文本编码器计算离散的输入标签嵌入表征,基于transformer的编码器计算图像嵌入表征。文本编码器可以把语义上相似的标签比如cat和furry嵌入到相近空间中,这样可以推广到没见过的样本
Introduction

从图1可以看出来分割的效果很好,以及增加了没有的标签情况下的容错能力也很好,主要是展示这种强大的zero-shot的能力,甚至可以实现dog,pet这种子类父类分割
Language-Driven Semantic Segmentation
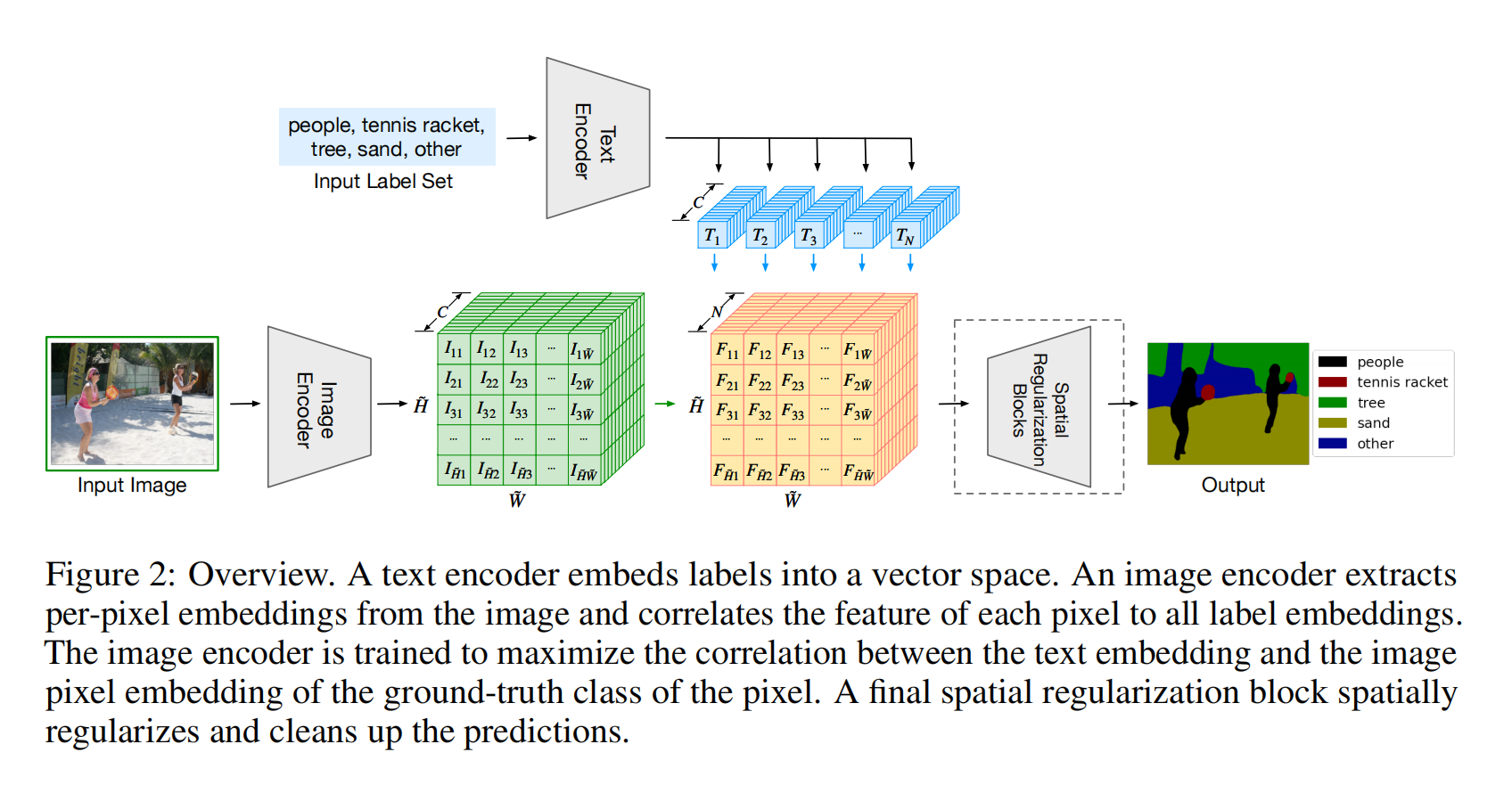
虽说是用了CLIP,但是实际上是做得有监督的训练,有ground truth做cross entropy loss,而不是用的对比学习的NCE loss。主要意义是将文本加入到分割的pipline里面,这样可以学习到一些language aware的特征
作者的text-encoder自始至终没有动,直接用的CLIP的文本编码器,训练也没动,因为语义分割的数据集很小,如果fine-tune可能就把模型带跑偏了而且训练困难
作者发现image-encoder用的是ViT的预训练参数,用CLIP的不太行
增加了一个spatial regularization blocks,在视觉和文本特征之后学习怎么进行融合交互达到更好的效果,比如加到2个效果好,但是加到4个就崩了,其实对性能没有多大影响
Experiment
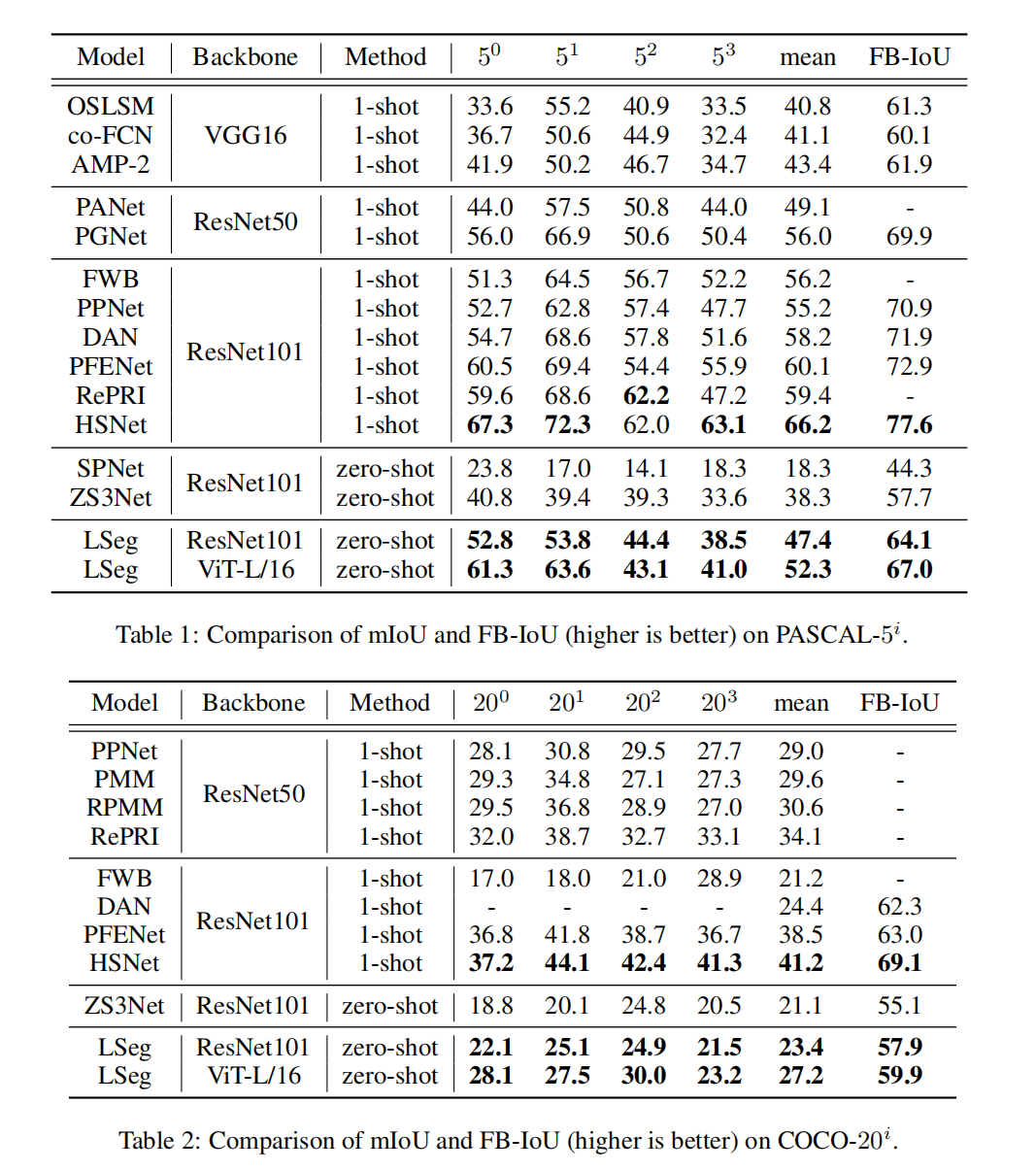
数据集用的PASCAL-5,COCO-20,SFF-1000,其实就是PASCAL有20个类,5个当作知道的类,剩下15个就是不知道的类,这样做zero-shot,COCO把80类分为20类
Failure Cases
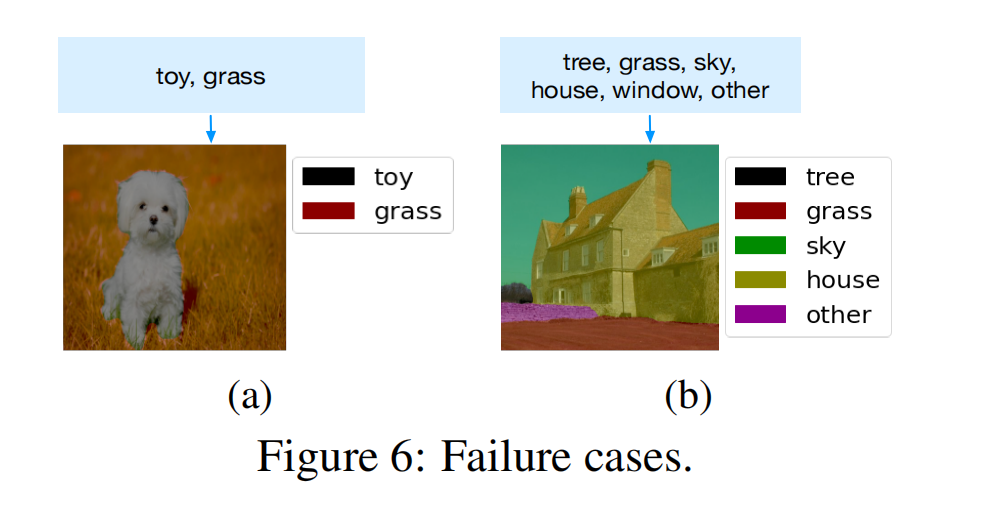
因为本质上还是算相似性不是做分类,所以谁相似就分成谁,就把狗分类成了玩具

