论文地址:GroupViT:Semantic Segmentation Emerges from Text Supervision
GroupViT:聚类无监督语义分割
Abstract
语义分割有监督很依赖于标注好的segementation mask,本文将group机制带回网络,在只有文本做监督信号的情况下做训练进行简单的分割任务
Method
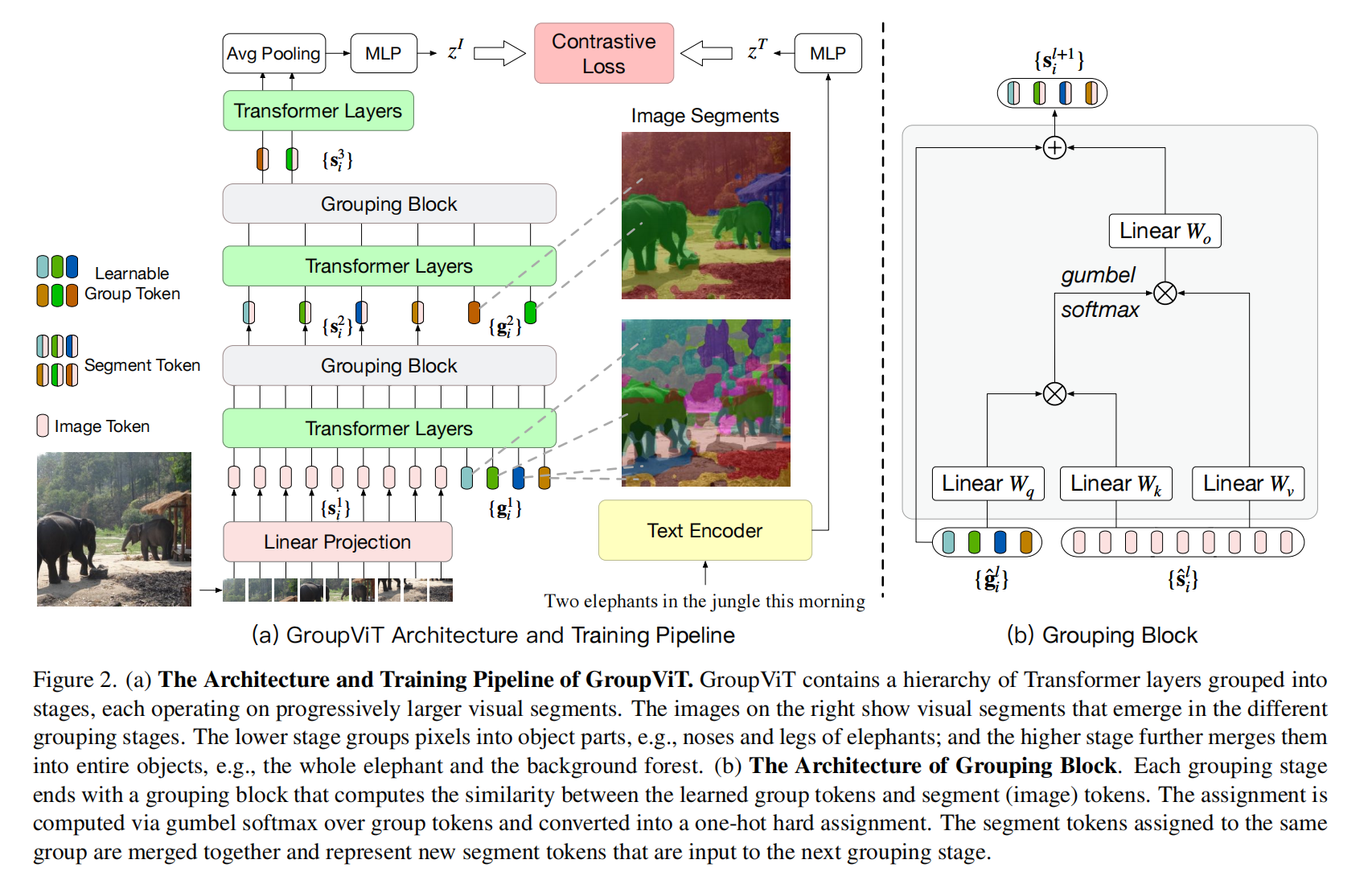
增加了grouping block和可学习的group token,将相邻的像素点做出segementation mask,学到后面越好
group token就类似CLS token,但是这里不是对整个图片抽出一个特征,而是做分割,每个小块有特征来表示,所以用64而不是1,把相似的点归结到61个cluster里面
图像打patch,和group token连接,经过transformer层后把patch分配到61个group token里面,然后作者希望再将一些小的类融合,增加了8个group token
Learning from Image-Text Pairs
Multi-Label Image-Text Contrastive Loss

使用了prompt learning做多标签对比学习,随机选择一些名词并且通过一些模板变成句子
Zero-Shot Transfer to Semantic Segmentation
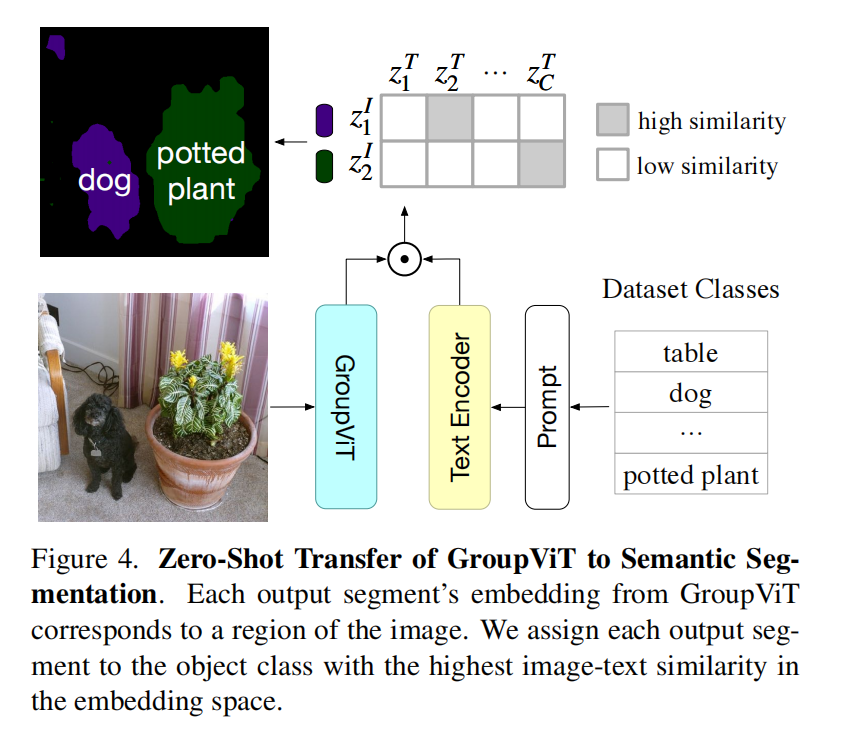
图像编码器得到8个group embedding,然后和文本特征算相似度就能得到属于什么类,但也意味着最多只能检测8类
Experiment
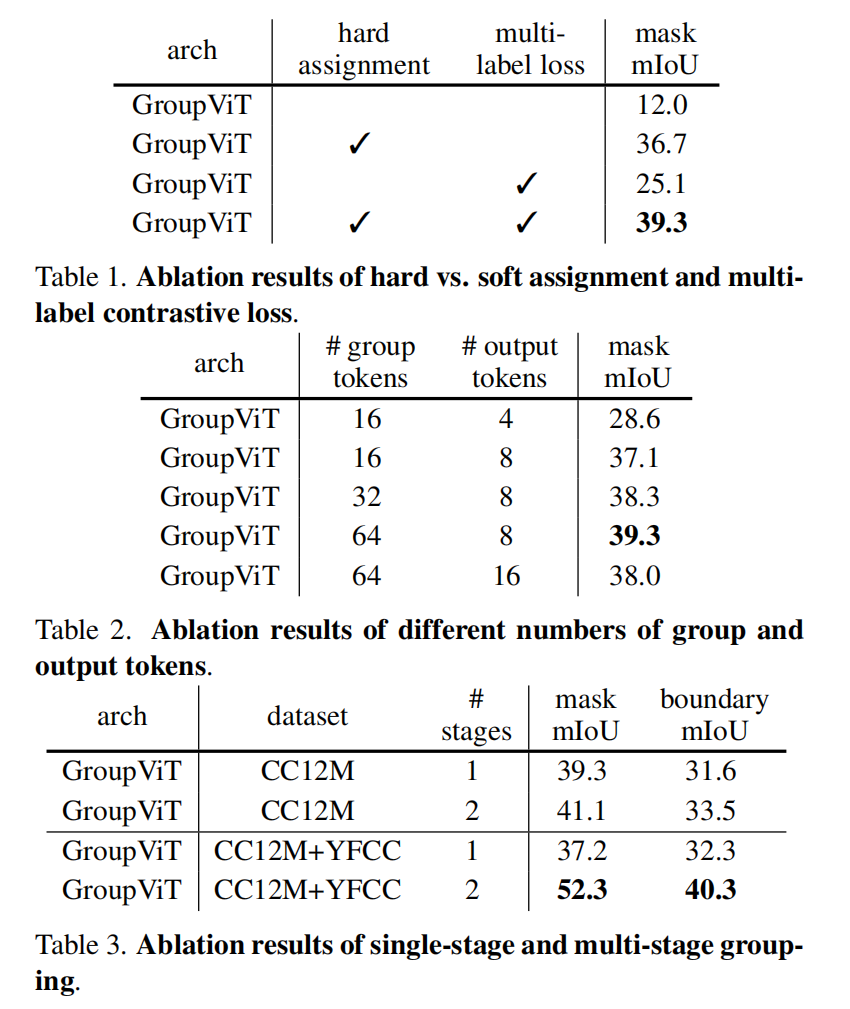
看起来选择8个token效果是最好的

看起来聚类中心确实起到了聚类的作用,完成了聚类分割
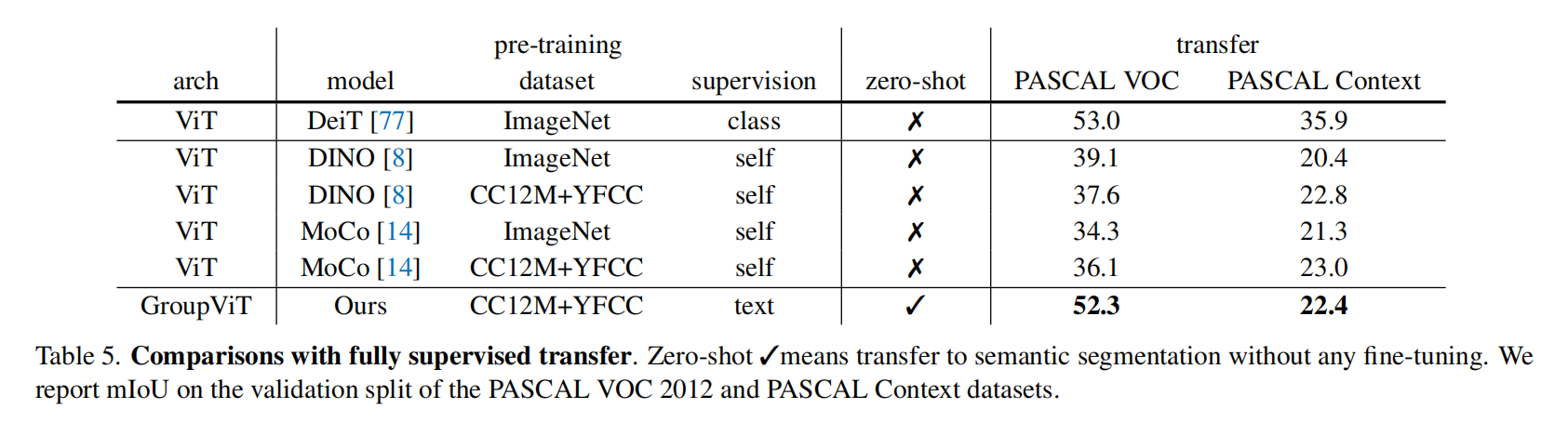
跟无监督的比效果有一定提升,但是有监督的方法已经到八十多和五十多了,差距还是很大的
Limitation and Futrue Work
- 现在GroupViT结构还是像一个图片编码器,没有很好利用dense prediction的特性,没有获得多尺度或者更多上下文信息
- 背景类问题,作者设置了阈值,比如相似度超过0.9才能说这个group embedding属于这一类,如果都没超过0.9就是背景类,但是如果前景物体和背景物体分数都差不多,就很难了。主要原因在于CLIP这种学习方式本来就难学习模糊的,可能是很多分类的背景问题,只能学语义非常明确的物体

