论文地址:GLIPv2:Unifying Localization and Vision-Language Understanding
GLIPv2:在GLIP上增加了更多任务和数据集
Abstratc
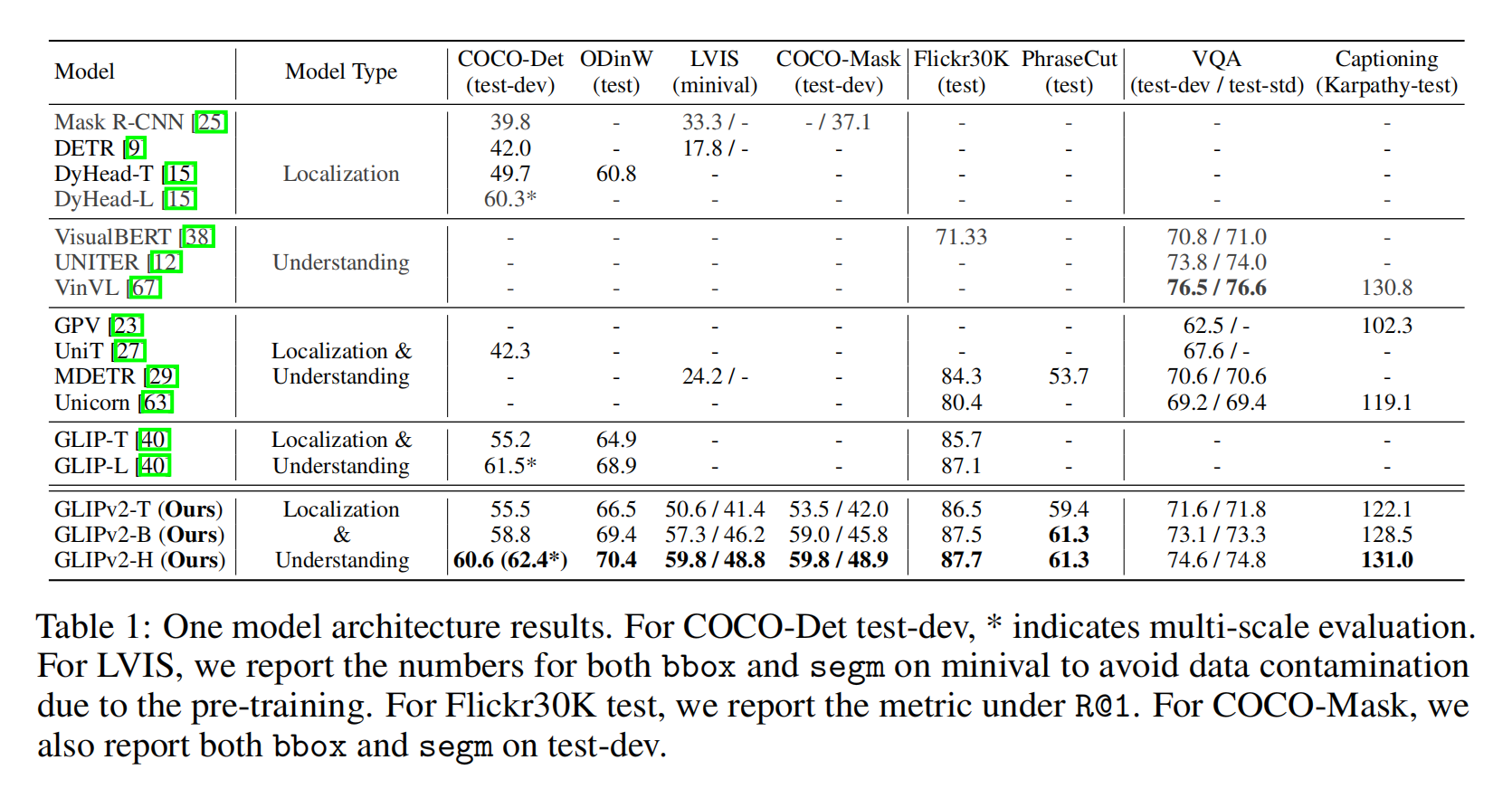
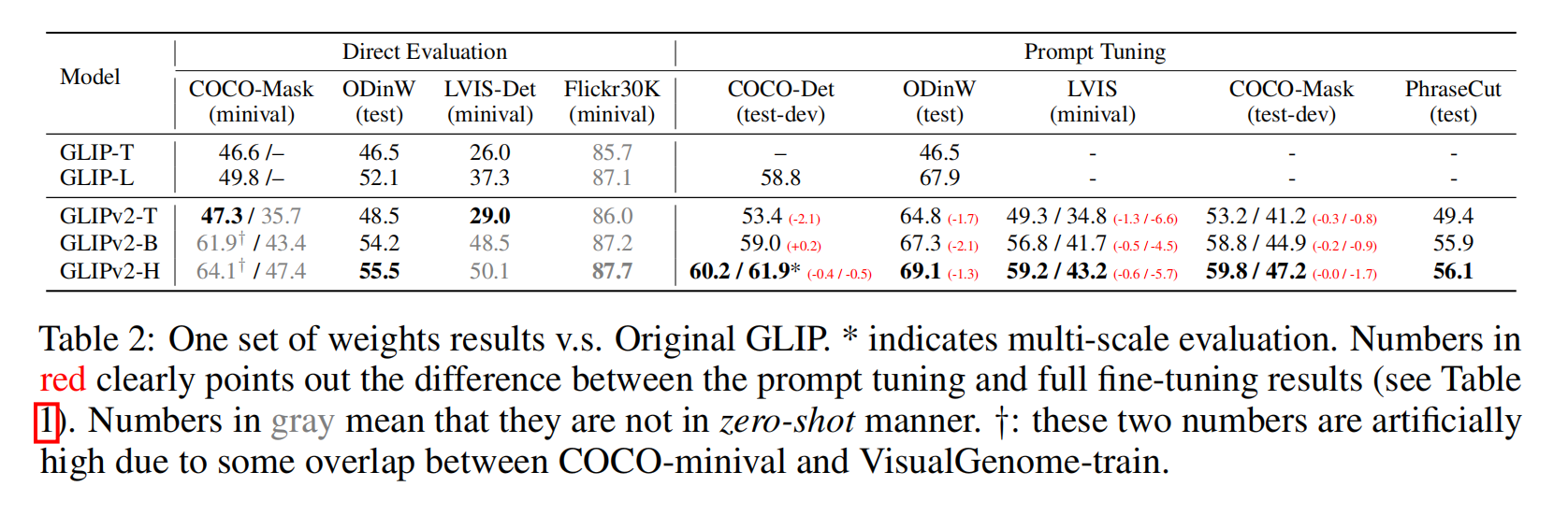
基本架构还是GLIP,只是把更多的任务,数据集融合进GLIP,比如分割,检测,VQA,image captioning
Introduction
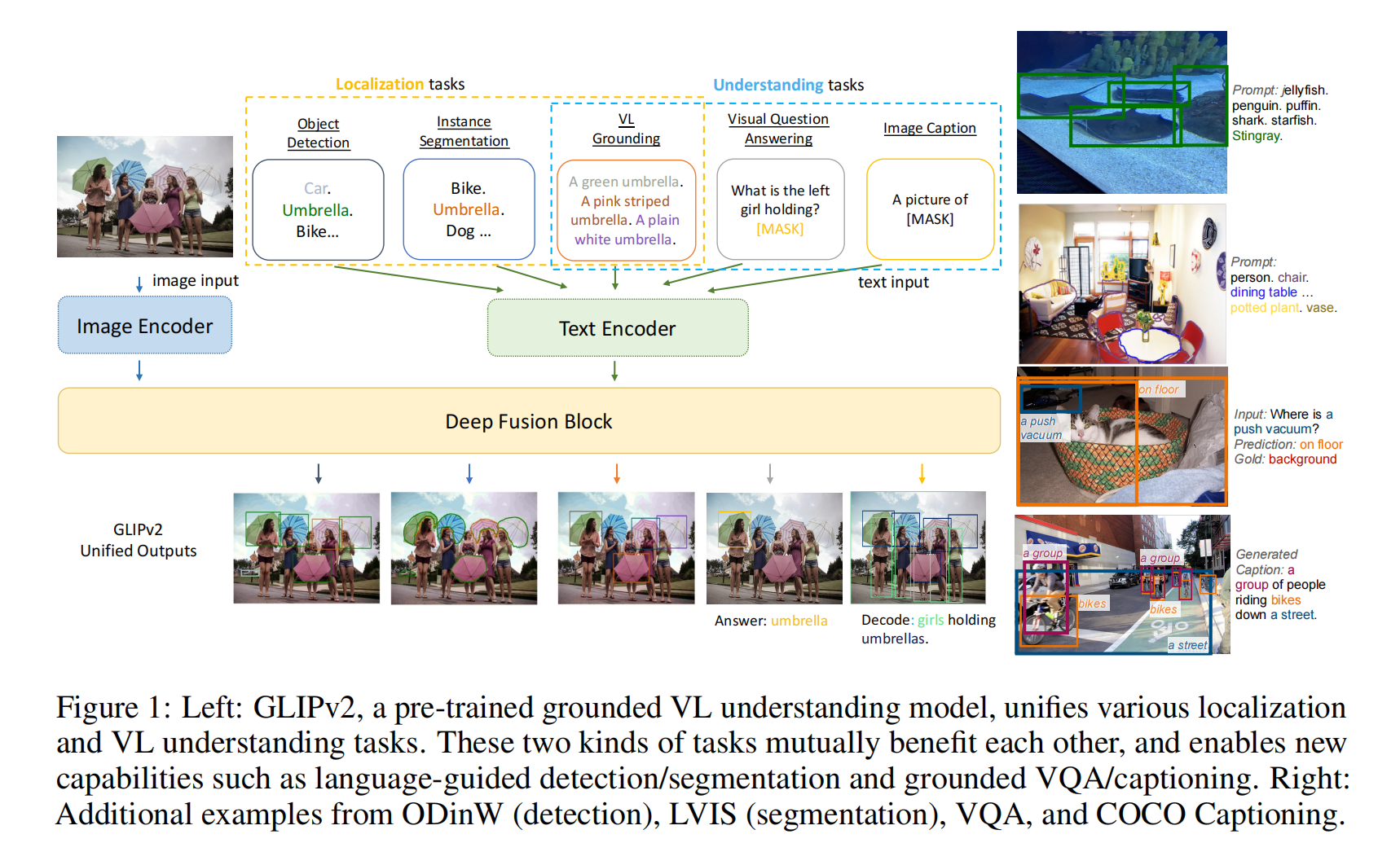
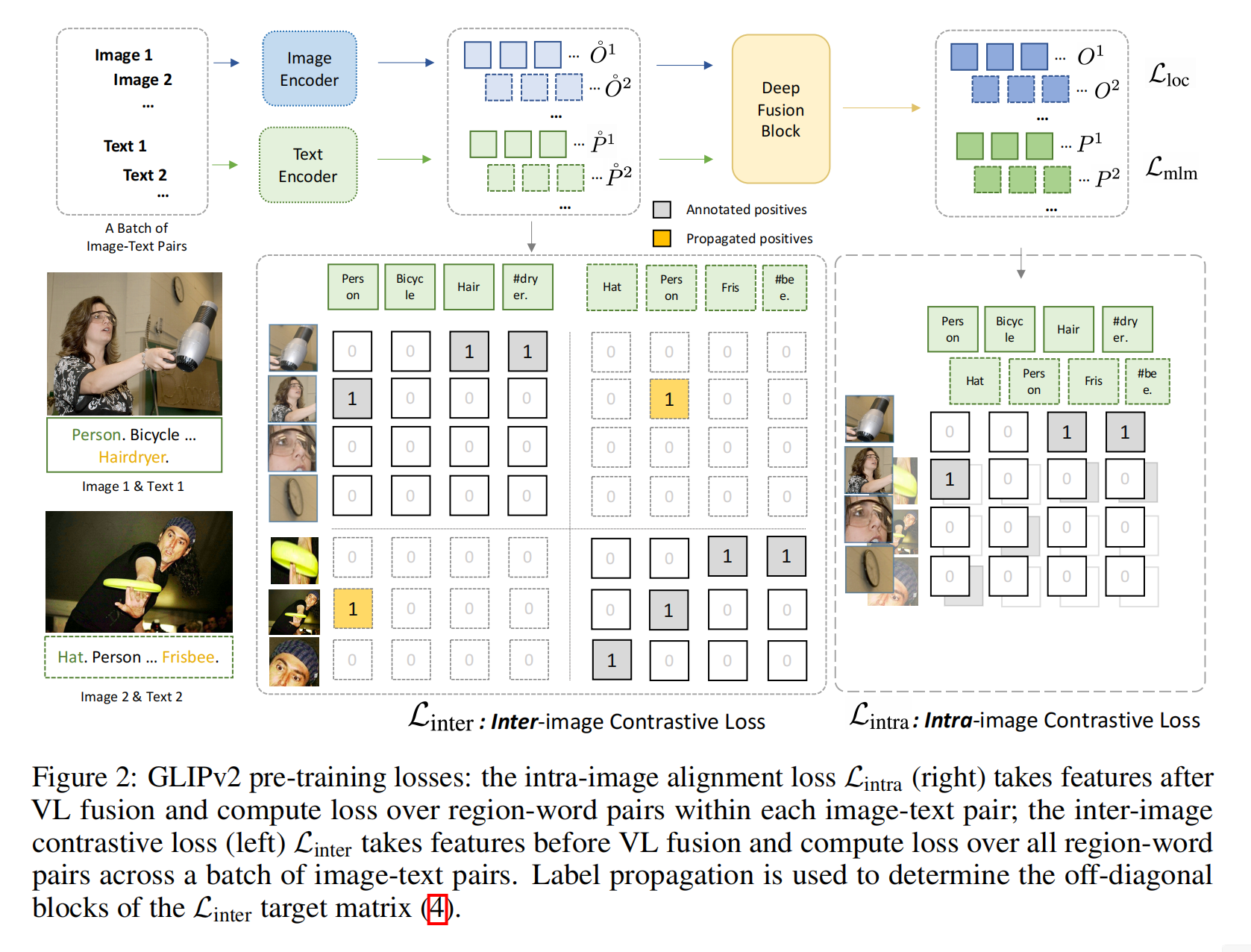
图像还是一个编码器,但是文本就多了很多理解任务,再做deep fusion
GLIPv2: Unifying Localization and VL Understanding
Experiment