GLIP:detection+grounding
Abstract
把目标检测和phrase grounding结合起来做预训练,这样的好处是 1)从detection和grounding数据中学习,以改进任务;2)可以通过以自我训练的方式生成grouding boxes来利用大量的图像-文本对,使学习到的表示语义丰富。在COCO和LVIS里面不看图片直接zero-shot也能达到很高的精度
Introduction

做推理时给标签,然后变成一句话,这句话通过GLIP模型就能检测出来,或者和grounding一样给一句话
Grounded Language Image Pre-training
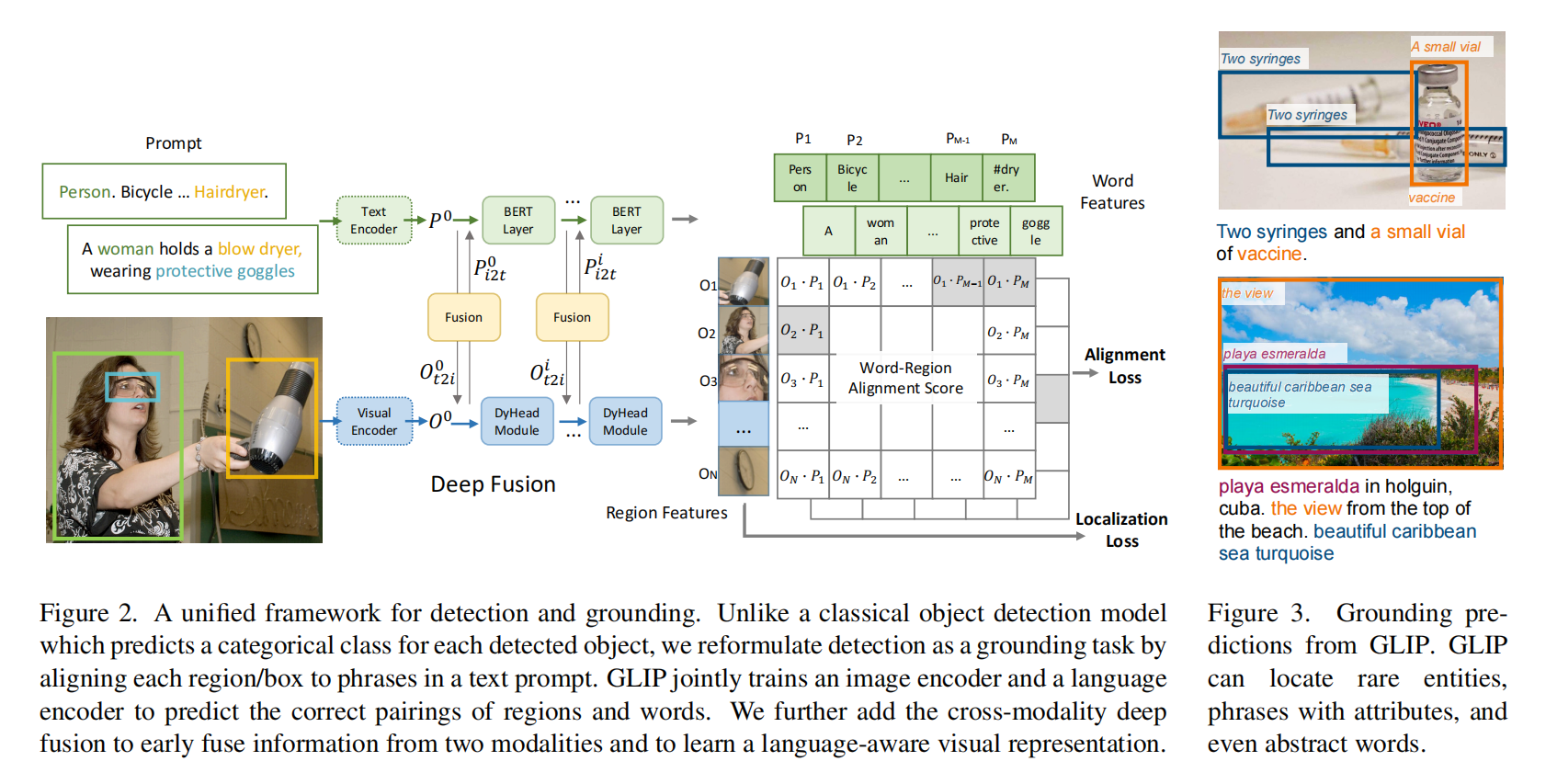
和CLIP两个分支算相似度,中间做了fusion
Unifified Formulation
object detection
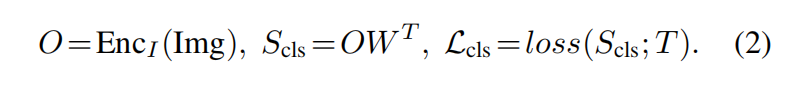
用图像的backbone得到region embedding,然后接一个分类头W,经过NMS把bounding box筛选再算loss
detection as phrase grounding
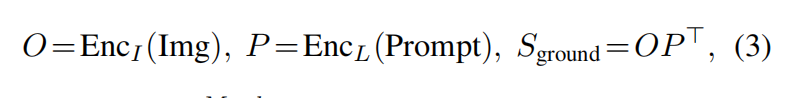
算匹配的分数,图像区域和句子里的单词怎么匹配上
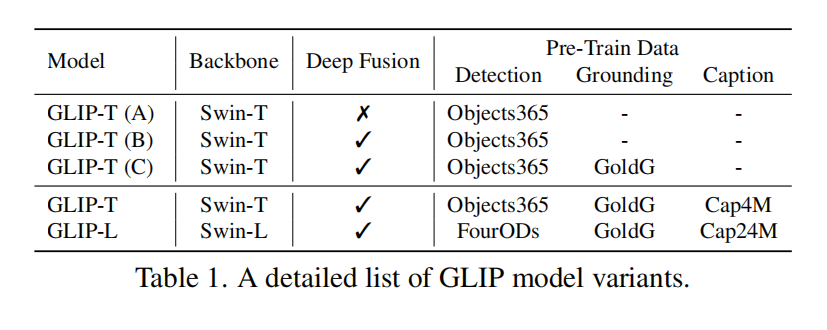
文本embedding和图片embedding算相似度,就能得到最终的region-word aligment scores即 $S_{ground}$
Equivalence between detection and grounding
做一点小改动把两种方法结合起来,公式2里的 $T\in {0,1}^{N\times c}$ 第二维扩展到和公式3里的 $S_{ground}\in R^{N\times M}$ 第二维一样大小,因为M作为词元数总是大于类别数c的,然后算postive match和negative match
Experiment
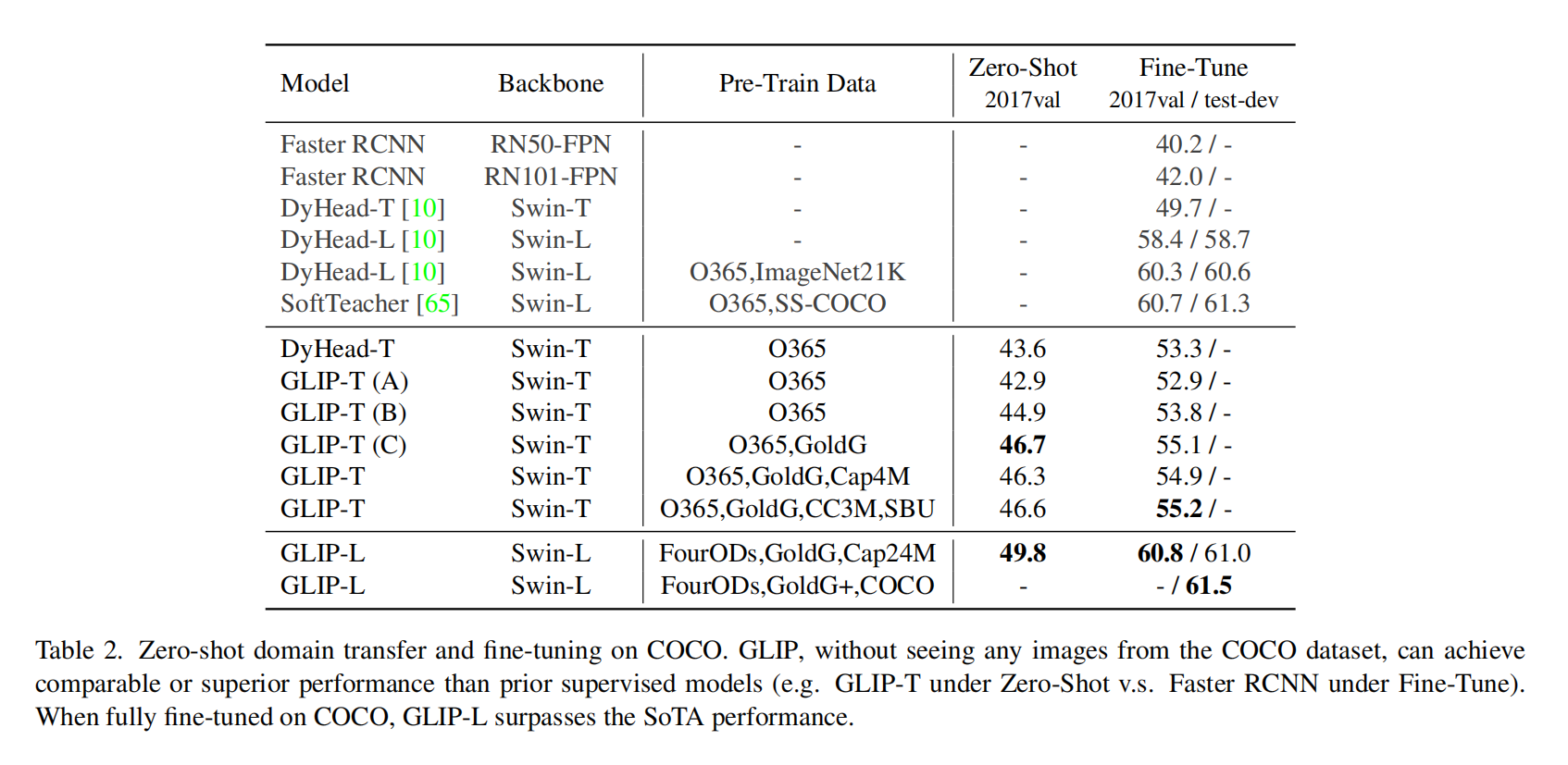
虽然预训练数据集不一样,比较不算公平,但是能看出来GLIP工作效果很不错

