论文地址:Open-vocabulary Object Detection via Vision and Language Knowledge Distillation
论文实现:https://github.com/tensorflow/tpu/tree/master/models/official/detection/projects/vild
ViLD:CLIP知识蒸馏做开放词库的目标检测
Abstract
将从一个预先训练好的open-vocabulary图像分类模型(teacher)中提取的知识提取为一个两阶段的detector(student),用teacher模型编码文本和目标图像区域,训练一个student detector,其被检测到的box的区域嵌入与teacher推理的文本和图像嵌入对齐
Introduction
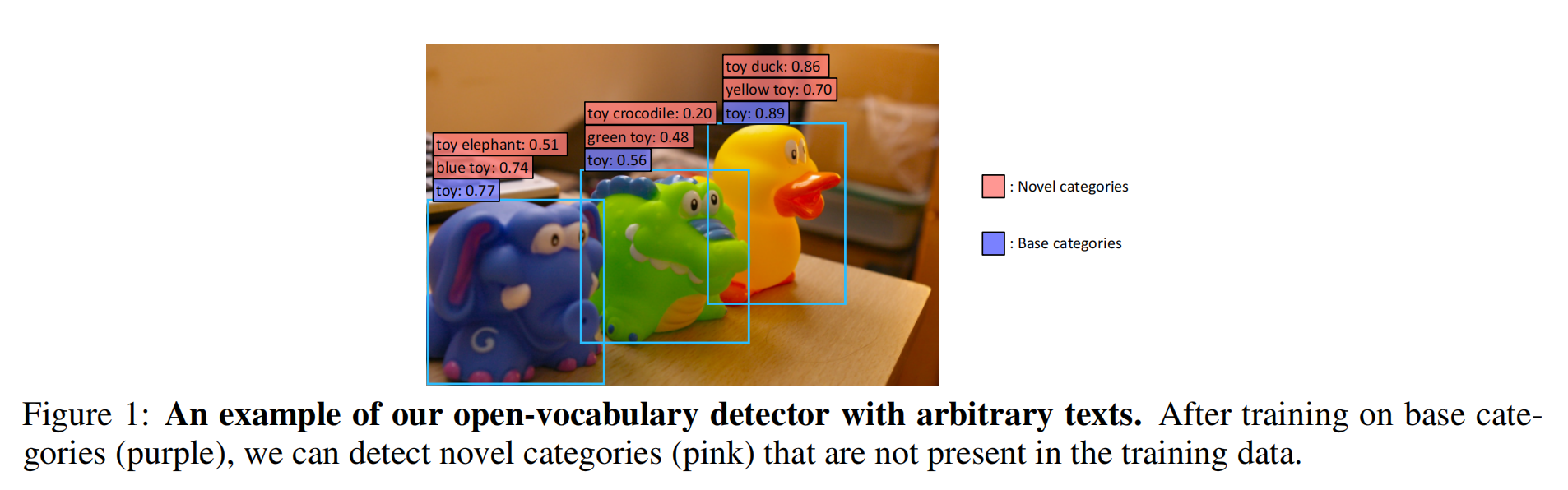
本文主要想做一个open-vocabulary的目标检测,在不增加类别的基础上(base categories)不去额外标注一些黄鸭子,但是能检测出来黄鸭子,也就是模型有检测novel category的能力
Method
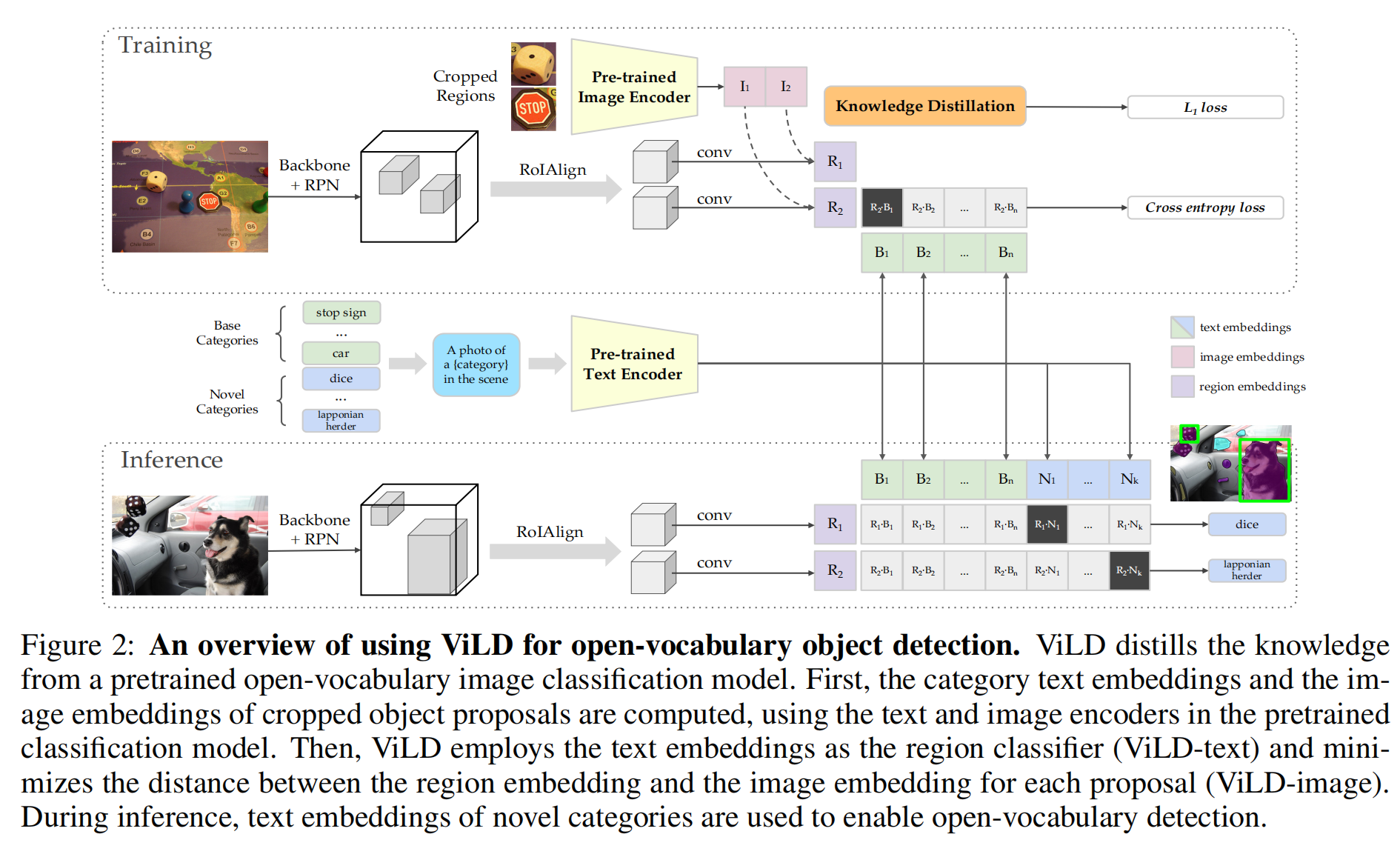
- 训练:
- ViLD-text:给定图片和基础类,通过RPN得到region proposal,再通过conv得到region embedding,绿色的基础类通过prompt再通过文本编码器,得到绿色的文本编码,再算cross entropy loss
- ViLD-imgae:把抽取好的region proposal(骰子,stop sign)通过CLIP得到CLIP的embedding,希望I和R尽可能接近,就做到了知识蒸馏
- 推理:
- 给定图片和基础类+蓝色新类别,图像得到region embedding,文本通过编码做点乘,得到zero-shot的目标检测
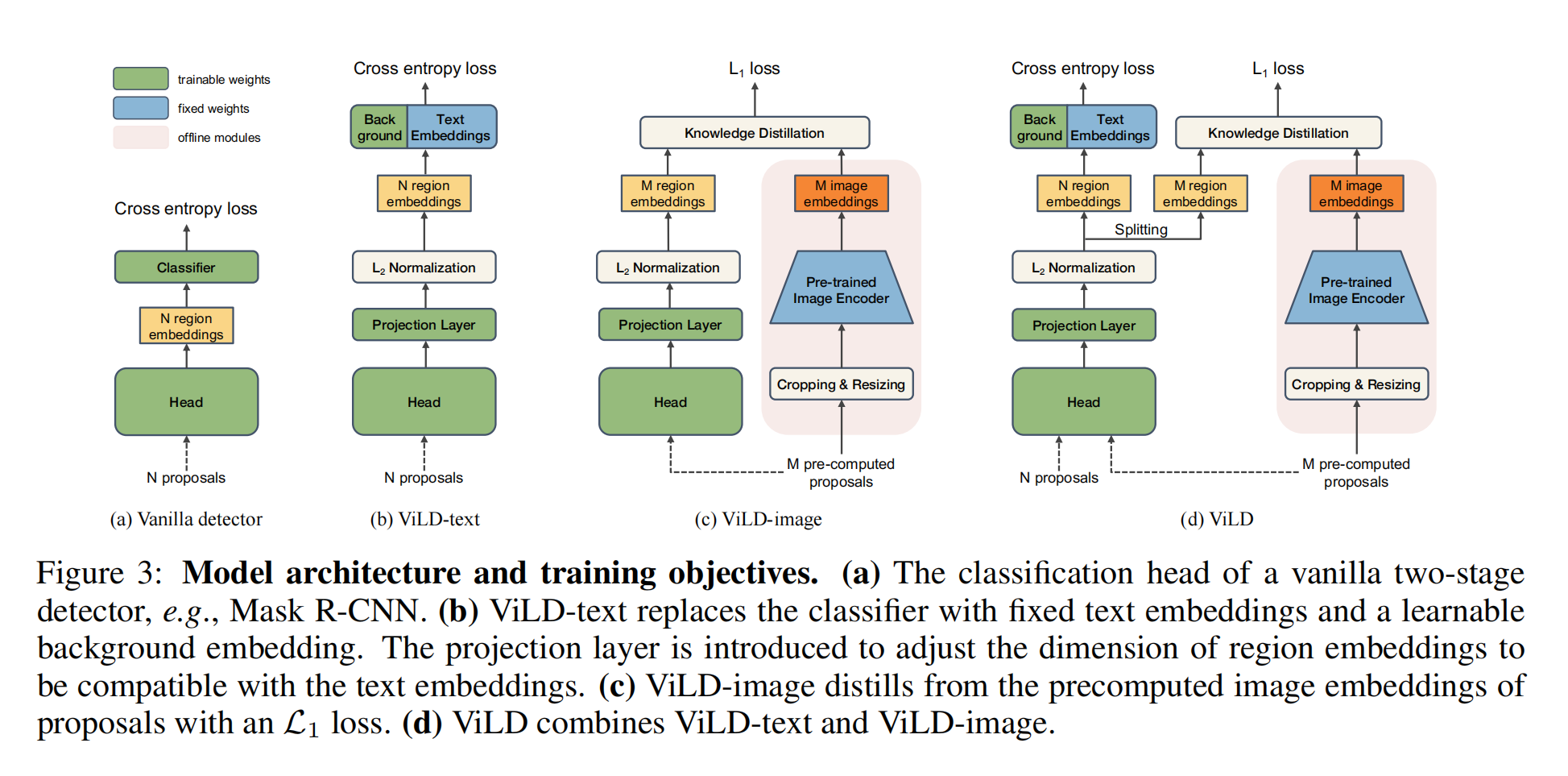
这些baseline都是mask RCNN,第一阶段出region proposal,也就是图里面的N proposals;第二阶段就是根据proposals过一个detection head得到region embedding,再通过分类头得到bonding box的类别
主要就是画box和分类
-
a方法是有监督的baseline
-
b方法就是像CLIP一样直接把text加进去通过prompt,embedding之后与图像点乘算相似度,还是有监督学习,类别还是base category,不在基础类的都塞到背景类,这个方法只是把图像和文本连接到一起
-
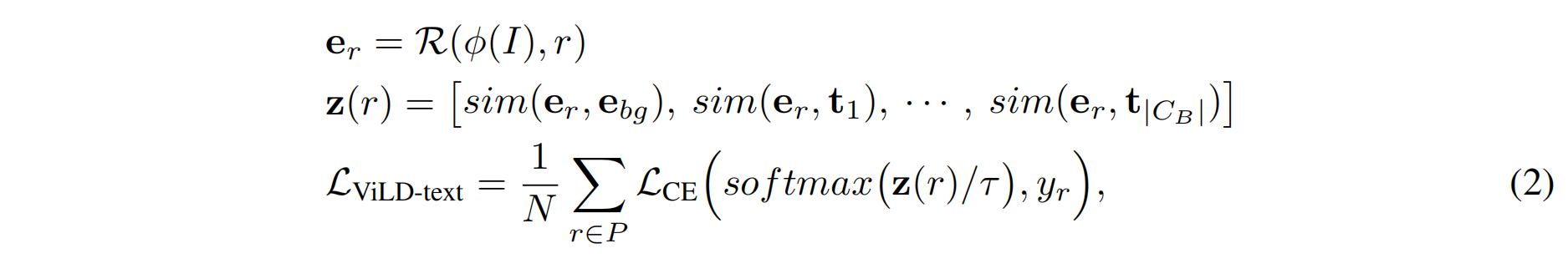
- 因为只在CB上做训练,所以zero-shot的效果仍然不是很好
-
-
c方法把图像做知识蒸馏,用CLIP预训练好的模型来训练student网络,这时候监督信号不再是人工标注了,而是CLIP带来的编码,就不受基础类的限制了,这就增强了CLIP的open-vocabulary的能力
- 如果每次都在训练的时候抽N proposals非常慢而且贵,所以作者先用region proposal network抽好了放磁盘里,也通过了CLIP得到了embedding放好了,这样训练就非常快
-
d方法是b和c的合体,N个推理得到的算cross entorpy loss,M个抽好的算L1 loss
Experiment
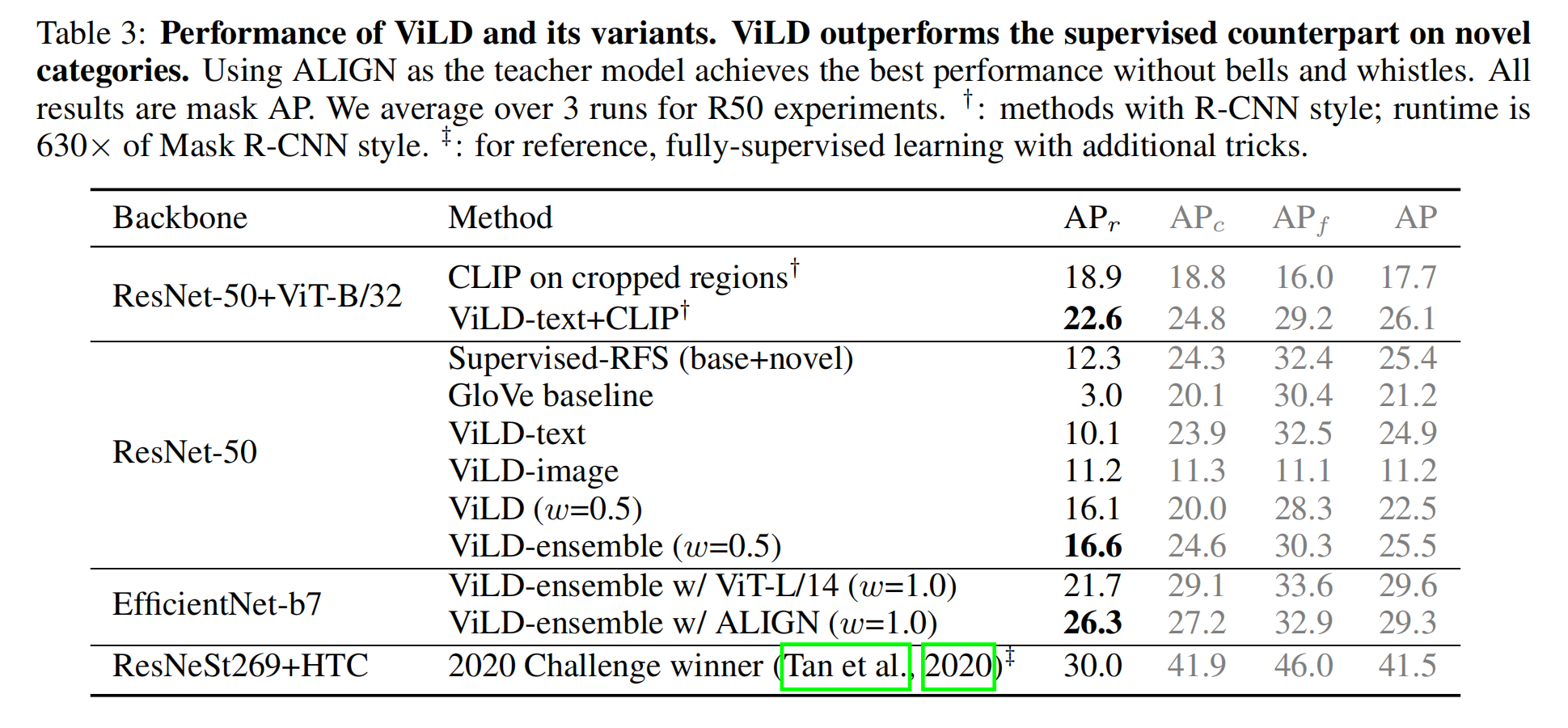
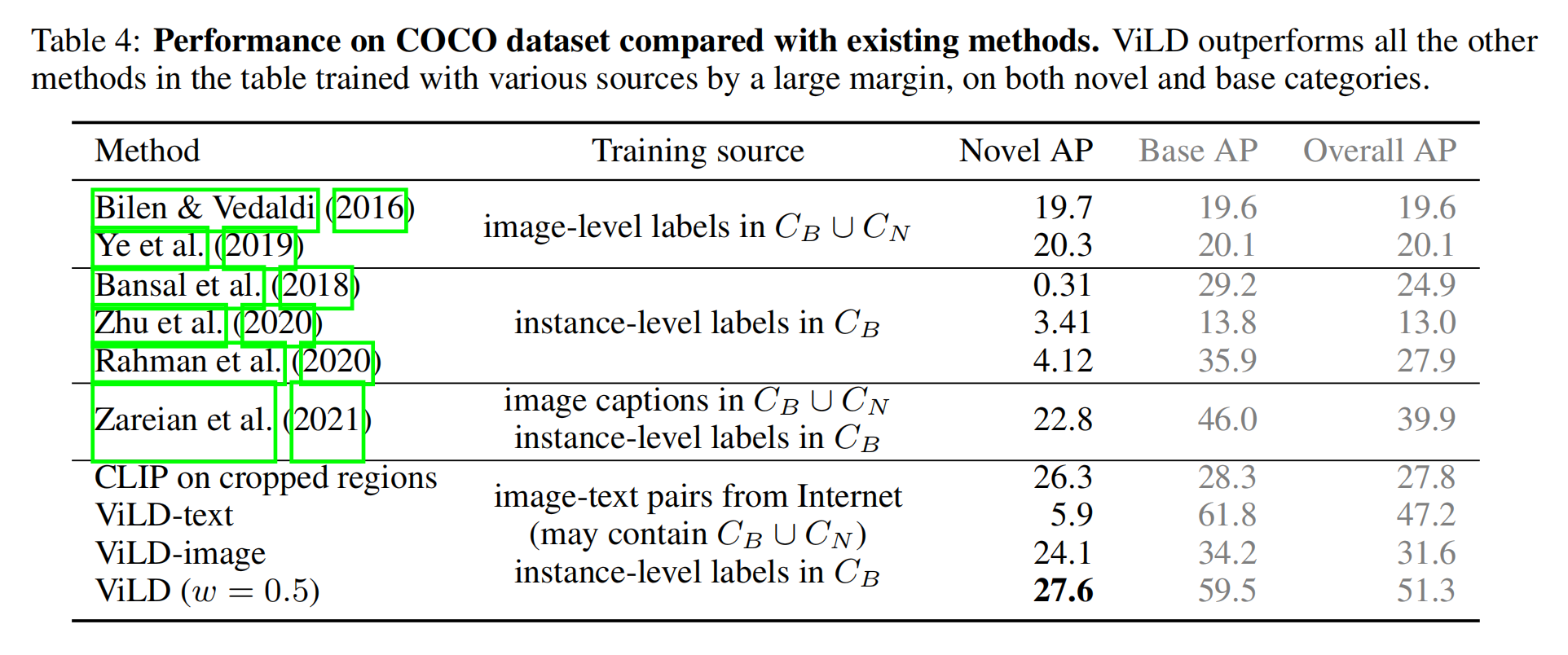
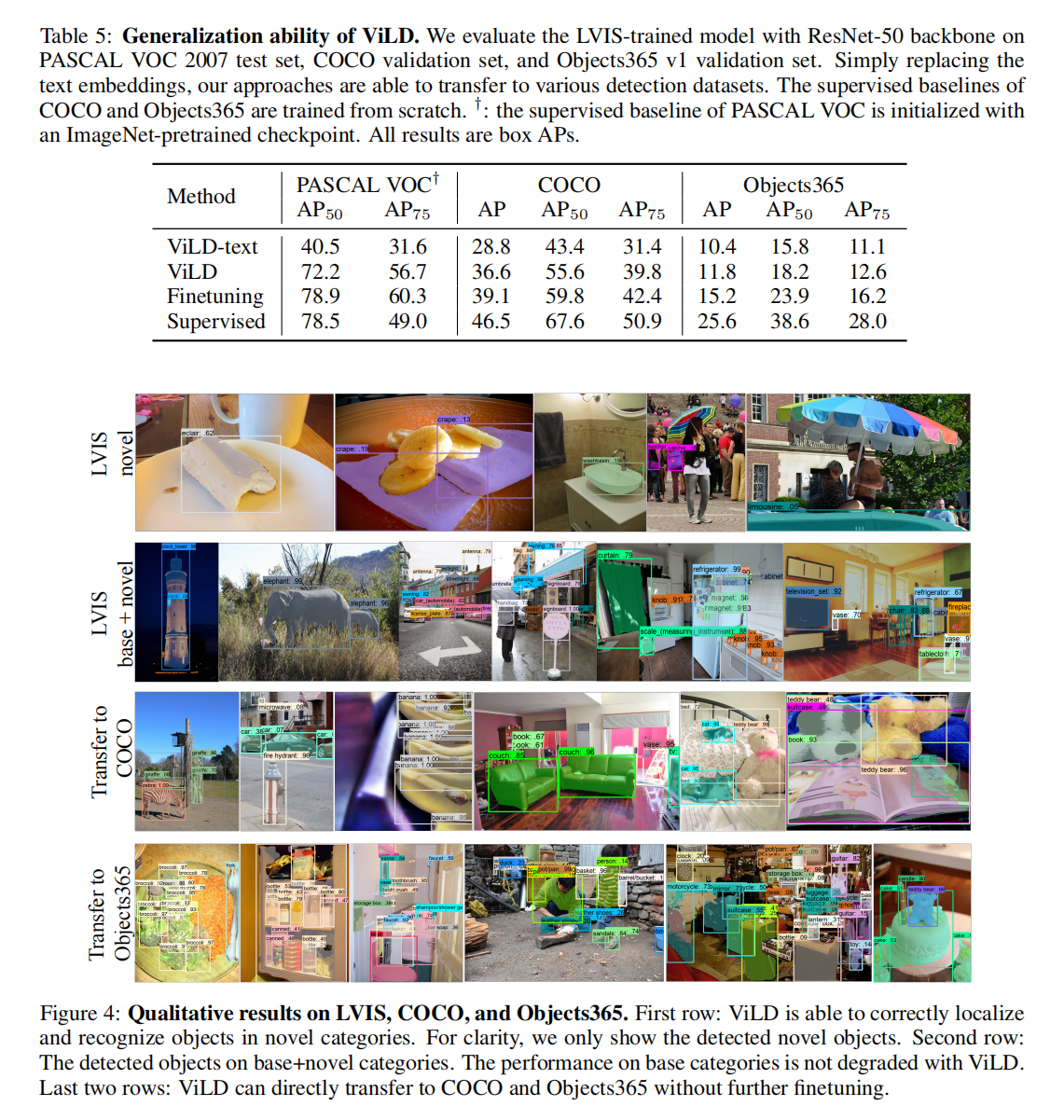
直接拓展到其他数据集上的效果

