ActionCLIP:文本提示视频动作识别
Abstract
本文提供了一个新的动作识别视角,通过重视标签文本的语义信息,而不是简单地将它们映射成数字,在多模态学习框架内将此任务建模为视频-文本匹配问题,通过语言加强视频表征能做zero-shot。首先从大量的网络图像文本或视频文本数据的预训练中学习表征,然后通过prompt engineering使动作识别任务更像是预训练问题,最后,它对目标数据集进行端到端微调
Introduction
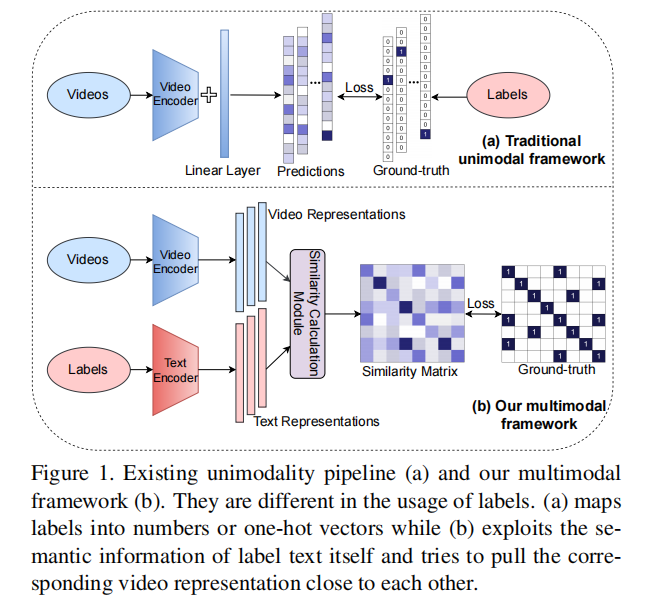
图1上半部分之前的方法在视频动作理解的做法是:有一些视频,给一个视频编码器,得到向量过分类头得到输出,与标号的数据做Loss
这里面最大的局限性有监督学习是需要标签的,但是对于视频理解而言怎么定义标签,怎么标记更多带标签的数据都是非常困难的问题,比如imagenet里面每个物体都是很清晰的,苹果是苹果,香蕉是香蕉,但是视频的动作理解里面有无穷多的组合,开门的开也可以是开瓶盖,开窗户等等,不可能标注很多很多类别,所以必须要拜托这种标注数据
图1下半部分作者的做法是视频输入编码器得到特征,把标签当作文本得到文本特征,之后算相似度,和ground truth算loss。这里有个问题是文本用的是标好的标签,当batch size比较大的时候,同一行或者同一列里面就可能出现多个正样本,比如多个样本都属于跑步这个标签,不再是一个one-hot问题,ground truth不一定是对角线才是正样本。作者把cross entropy loss换成了KL散度
Method
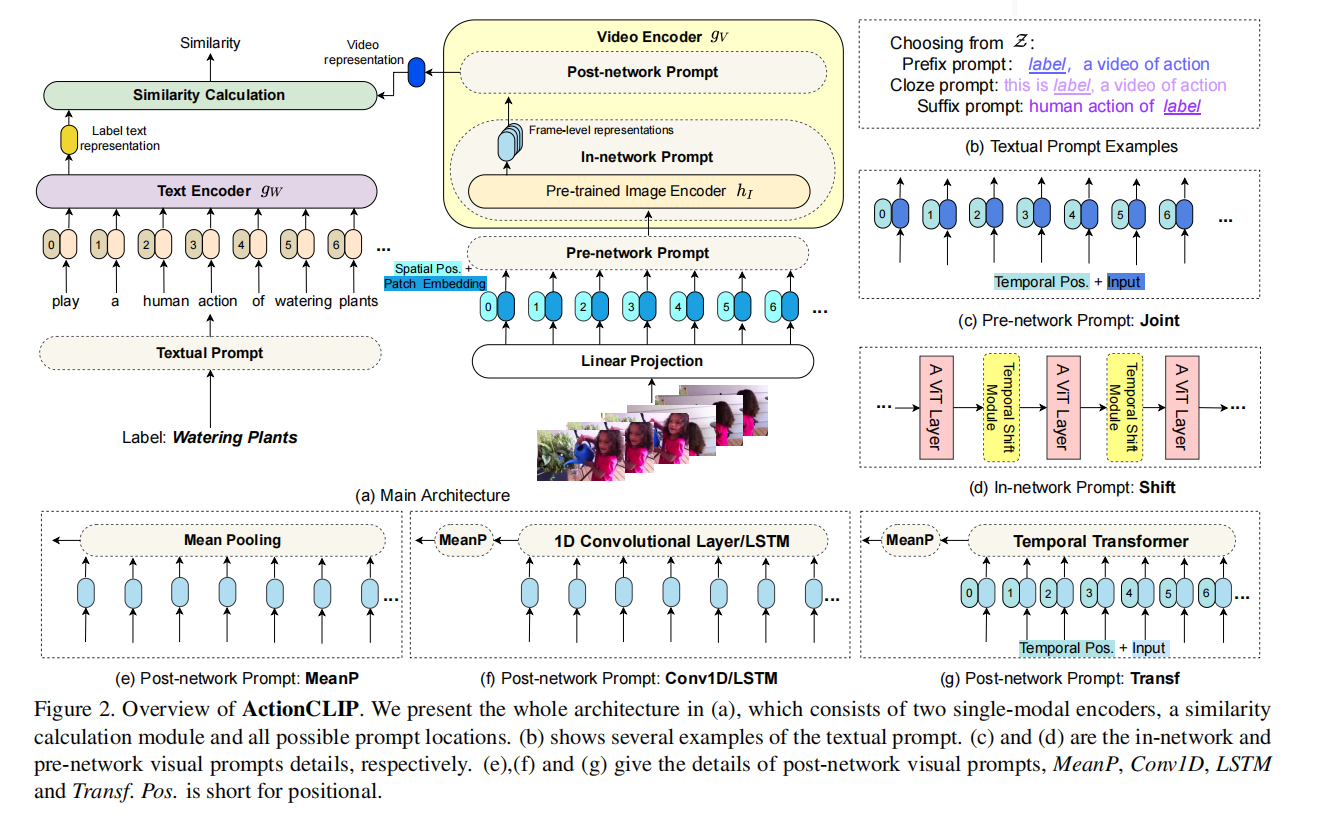
和CLIP几乎大差不差
- 图2b主要是文本的提示模板,在前面,中间和末尾加上一个句子
- 图2c把时间的embedding和空间的token放一起给网络来学习
- 图2d是shift概念,简单高效放在每个block中间
- 图2efg是把视频时间维度多个特征变成1个特征
Experiments
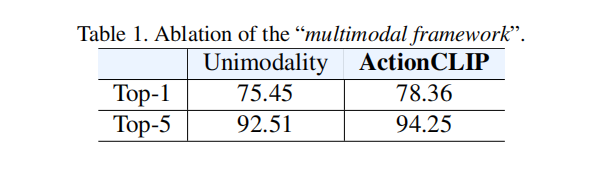
multimodal framework到底有没有用呢?就是把one-hot标签换成language guided的目标函数有没有用
从表1看出来还是提升了3个点的
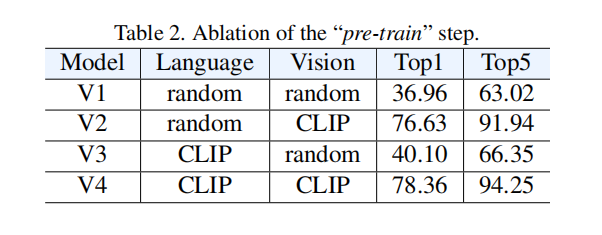
pre-train这个阶段到底重不重要?
可以看到都用了CLIP性能很高的,但是文本的初始化问题不是很大,基本多模态的注意力都会放在视觉这边,使用vit去初始化
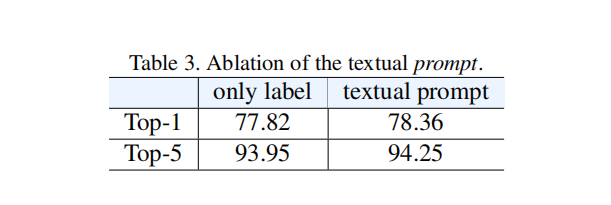
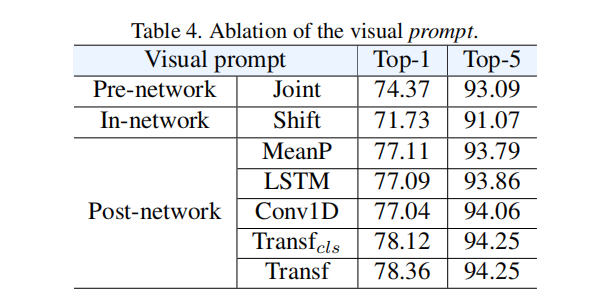
prompt到底有没有用呢?
文本这边不用prompt也就掉了零点几个点,视频这边发现post-network是很有用的
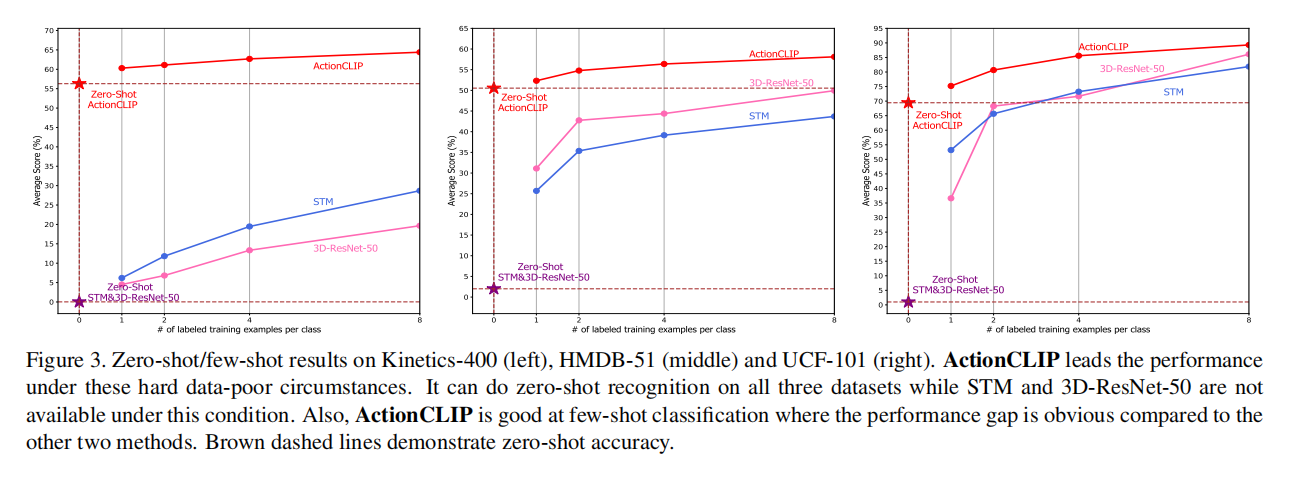
zero-shot能力很强

