AudioCLIP:视频数据三种模态对比学习
Abstract
在文本和图片的基础上加上了audio这个模态,使用音频集数据集将ESResNeXt音频模型合并到CLIP框架中
Model
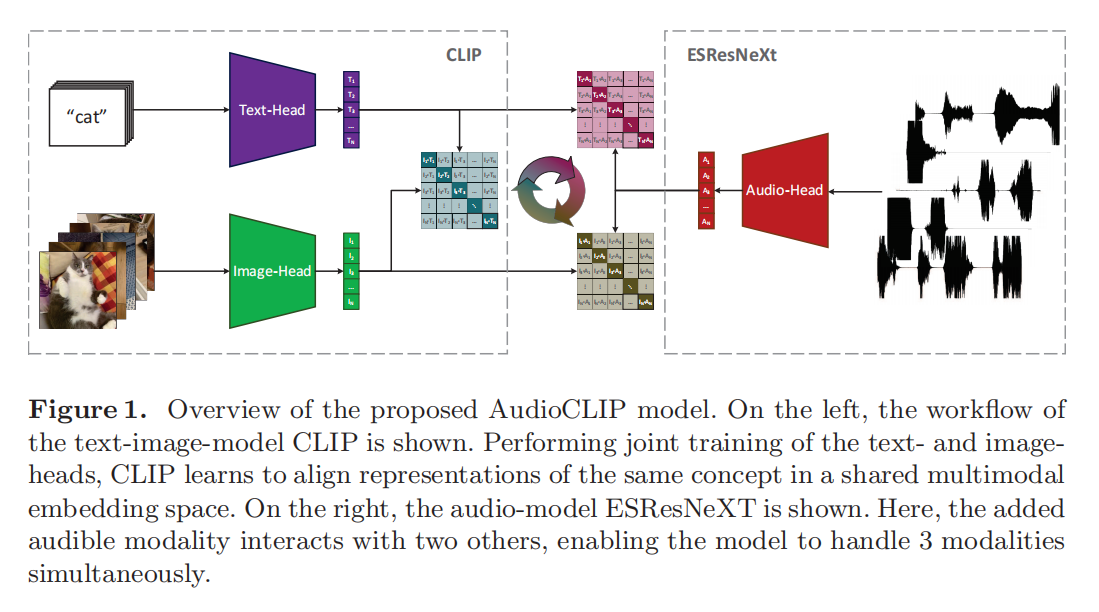
找了一些视频的数据集,视频里是存在文本,图片和音频三种模态的,就仿照CLIP的结构全加进来就行,这些数据都是成对出现的,所以很好做对比学习
Result
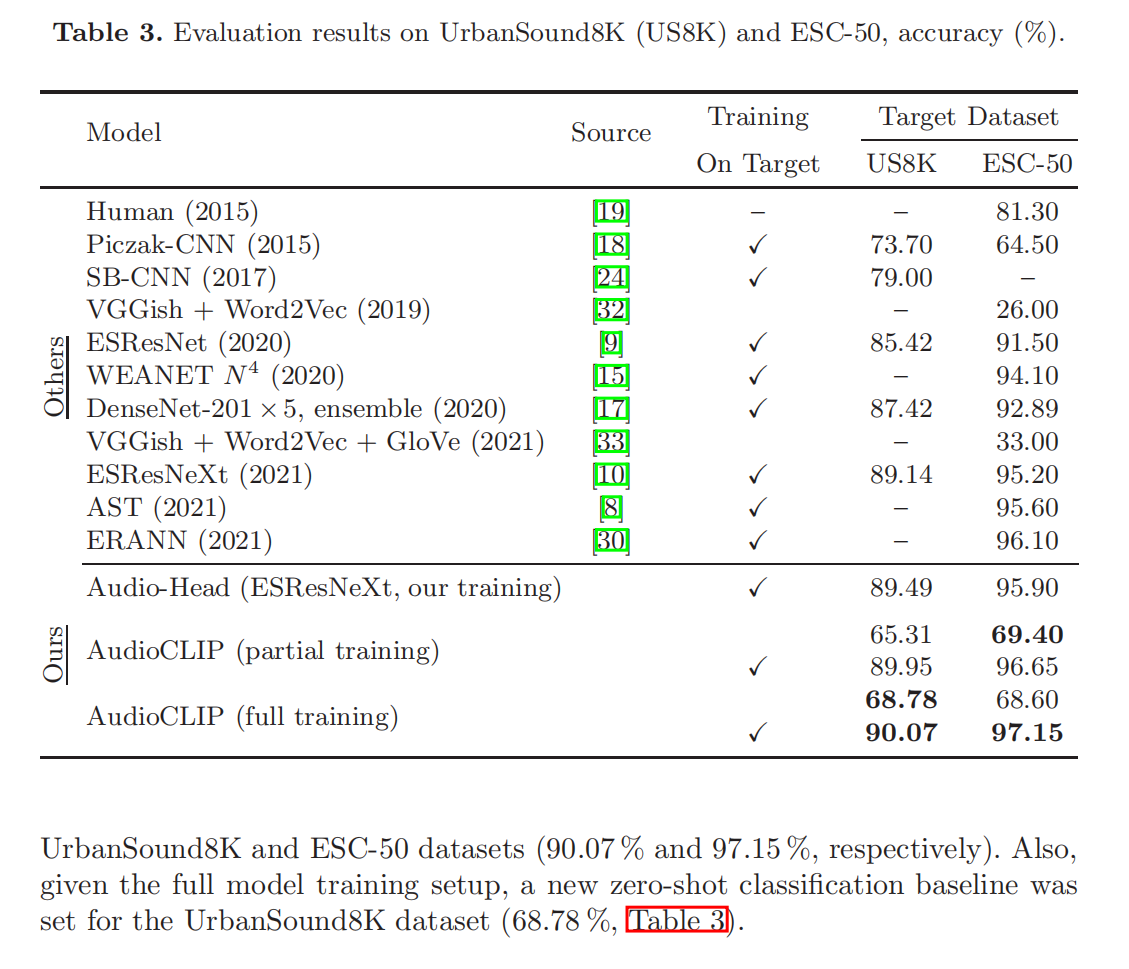
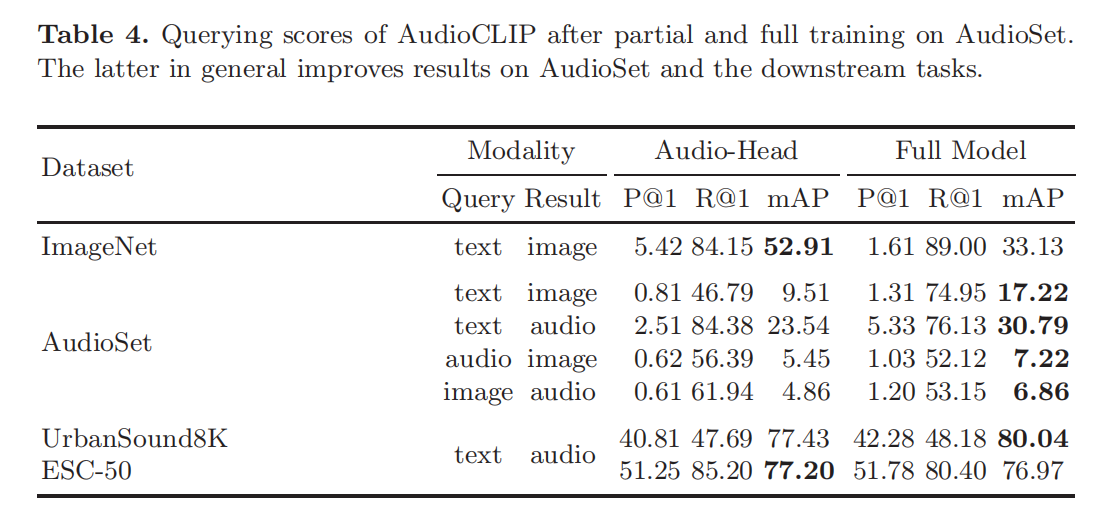
在文本和图片的基础上加上了audio这个模态,使用音频集数据集将ESResNeXt音频模型合并到CLIP框架中
找了一些视频的数据集,视频里是存在文本,图片和音频三种模态的,就仿照CLIP的结构全加进来就行,这些数据都是成对出现的,所以很好做对比学习
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY 4.0 CN协议 许可协议。转载请注明出处!
Maybe you could buy me a cup of coffee.

Scan this qrcode
Open alipay app scan this qrcode, buy me a coffee!

Scan this qrcode
Open wechat app scan this qrcode, buy me a coffee!