论文地址:CLIP4Clip:An Empirical Study of CLIP for End to End Video Clip Retrieval
CLIP4Clip:实验不同多帧图片融合方法做视频文本检索
Abstract
提出了一个CLIP4Clip模型,以端到端的方式将CLIP模型的知识转移到视频语言检索中,并调查了一些问题:1. 图像特征对视频-文本检索是否够用?2. 在基于CLIP的大规模视频文本数据集上进行后预训练如何影响性能?3. 视频帧之间的时间依赖性的实际机制是什么?4. 模型在视频文本检索任务中的超参数敏感性
Introduction
CLIP本身是双塔结构,图像文本编码器是分开的,只需要点乘就能得到相似度,还可以提前抽特征,非常适合做搜索和检索,在视频领域多一个时间维度
Framework
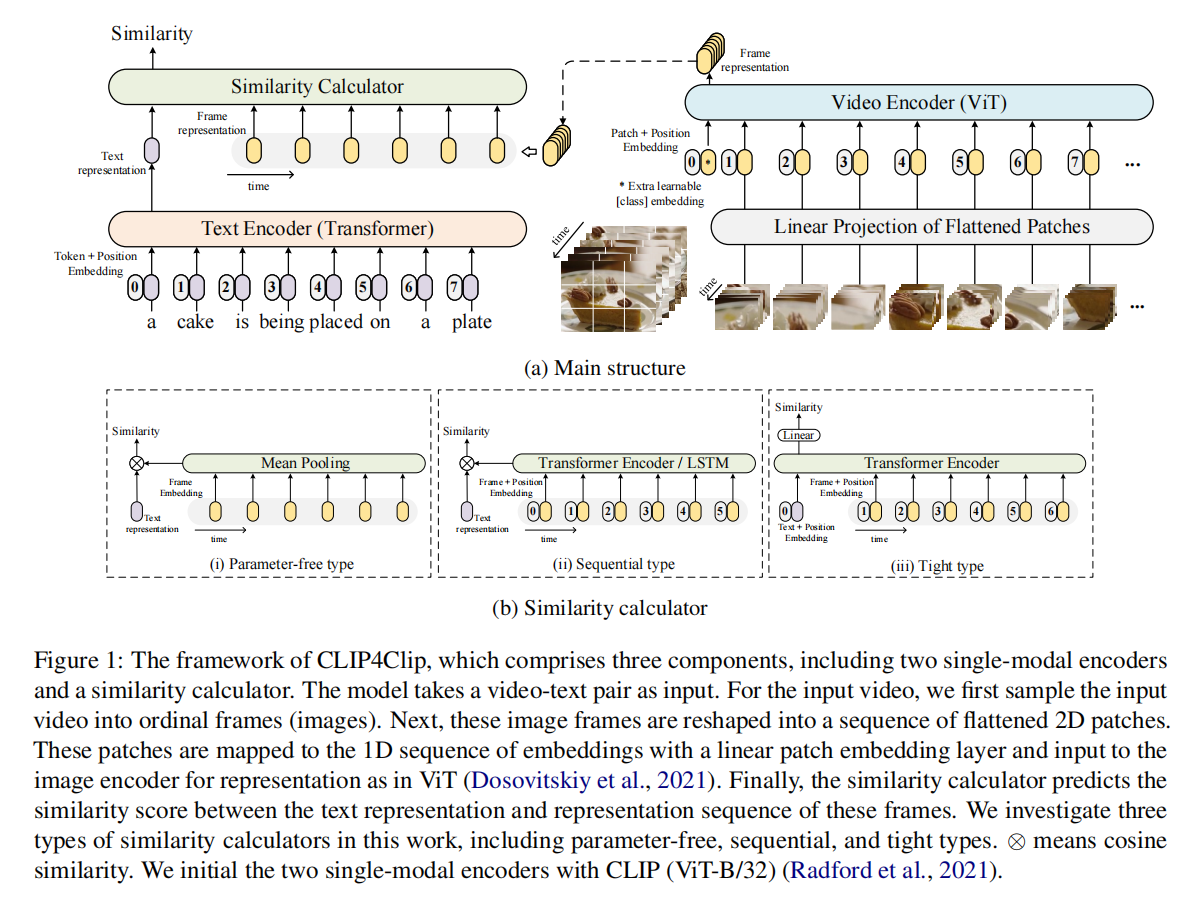
视频多时间维度,假设10帧打成patch后经过vit就会得到10个CLS token,10个图片的global的整体表征,原本是一个文本特征对应一个图片特征直接算点乘就好,现在是一个文本特征对应10个图像特征
作者尝试了上图三种方法:
- 不学,10个图片直接平均,不考虑时序特性,比如人在坐下的过程,这是学不到的
- 时序建模,10个特征丢给LSTM或transformer
- 做early fusion,文本和图像帧一起丢给transformer学习,通过MLP得到相似度
Experiments
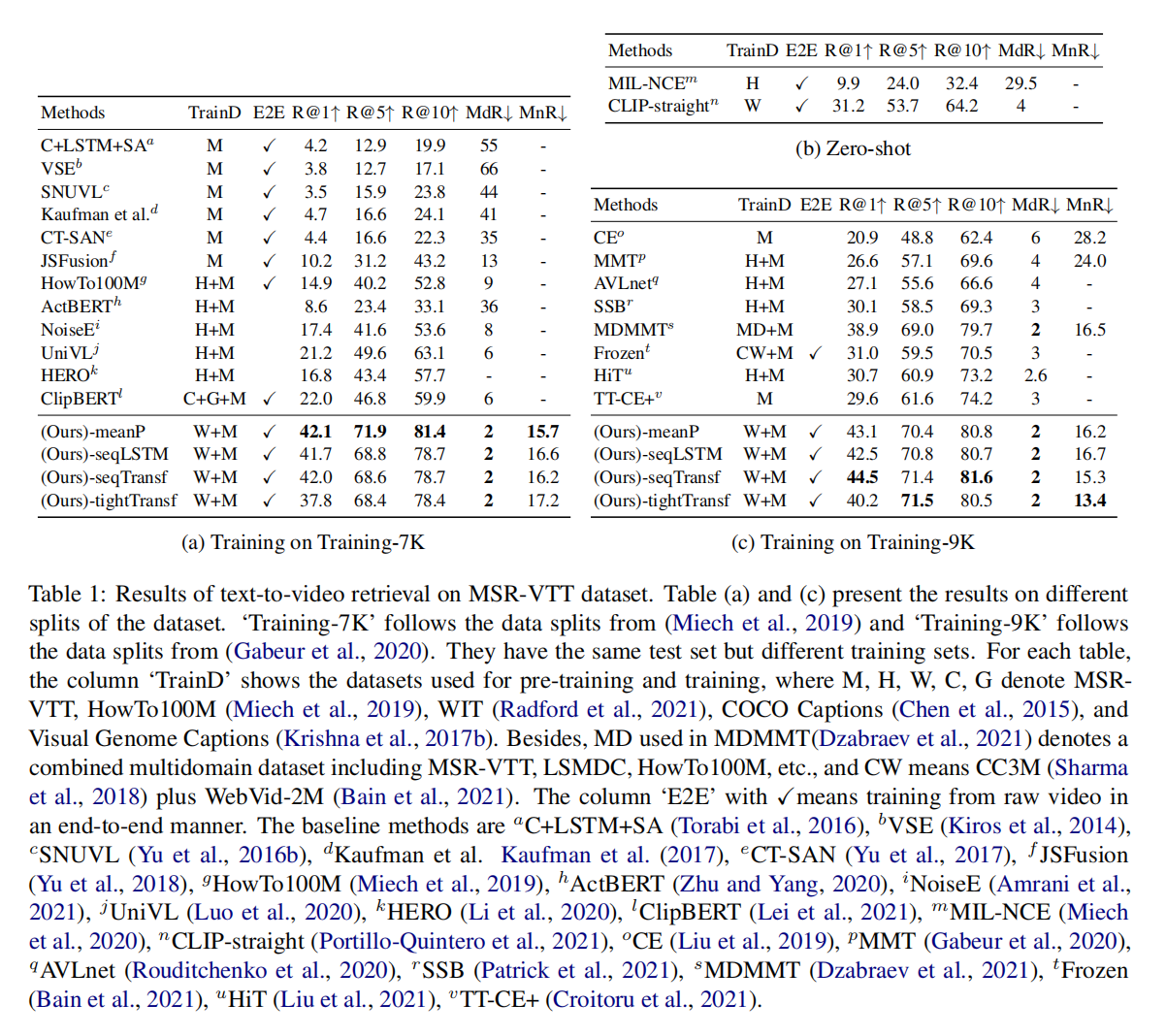
召回率提升了一大截,但是更多助力来源于CLIP,迁移性很好,直接做zero-shot都能秒杀前面的方法
少量数据的时候直接取平均是最好的,数据量大的时候带参的效果会更好一些,但也就比mean pooling好一点点
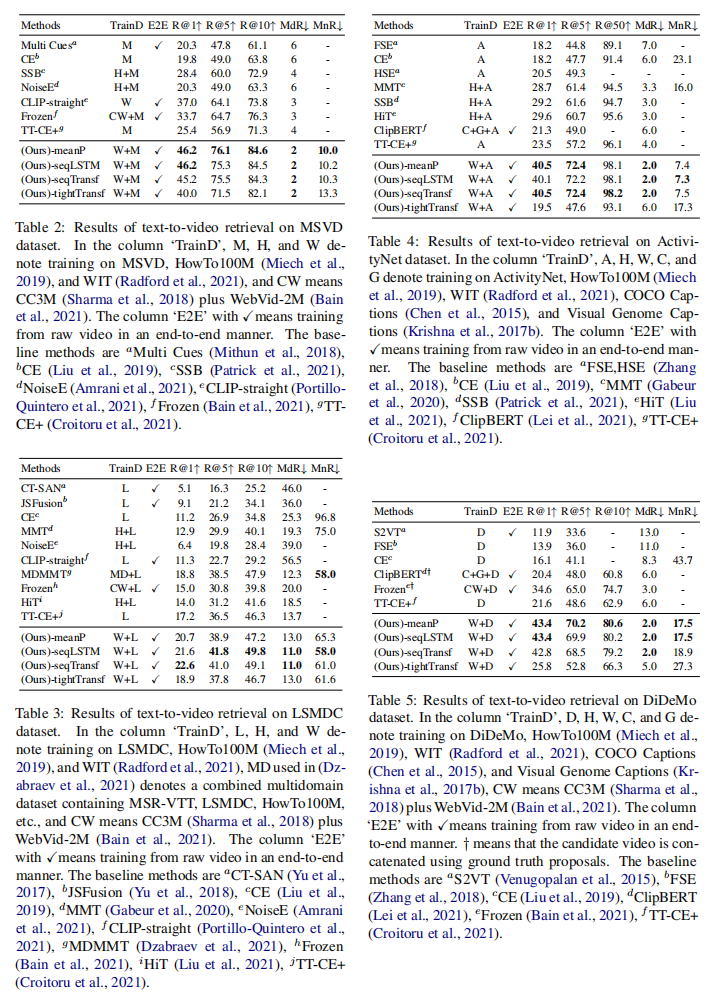
mean pooling效果经常是最好的,虽然理论上不能建模时序信息,但是现实中已经工作的很好了,有时候sequenial会好一点点,可能是下游任务数据不够造成的
Conclusion
-
图像特性也可以促进视频文本检索
-
CLIP训练完后在视频数据集再训练一次可以进一步提高性能,因为有domin gap
-
3D patch linear projection和sequential type simlarity会好一些
-
CLIP用于视频文本检索是学习率非常敏感的

