CLIPasso:几何和语义损失函数生成简笔画
Abstract
提出了CLIPasso,一种可以通过几何和语义简化,实现不同抽象层次的对象绘制方法。因为简笔画的生成很依赖简笔画数据集来训练,所以使用了CLLIP来从简笔画和图像中提取语义信息
Introduction
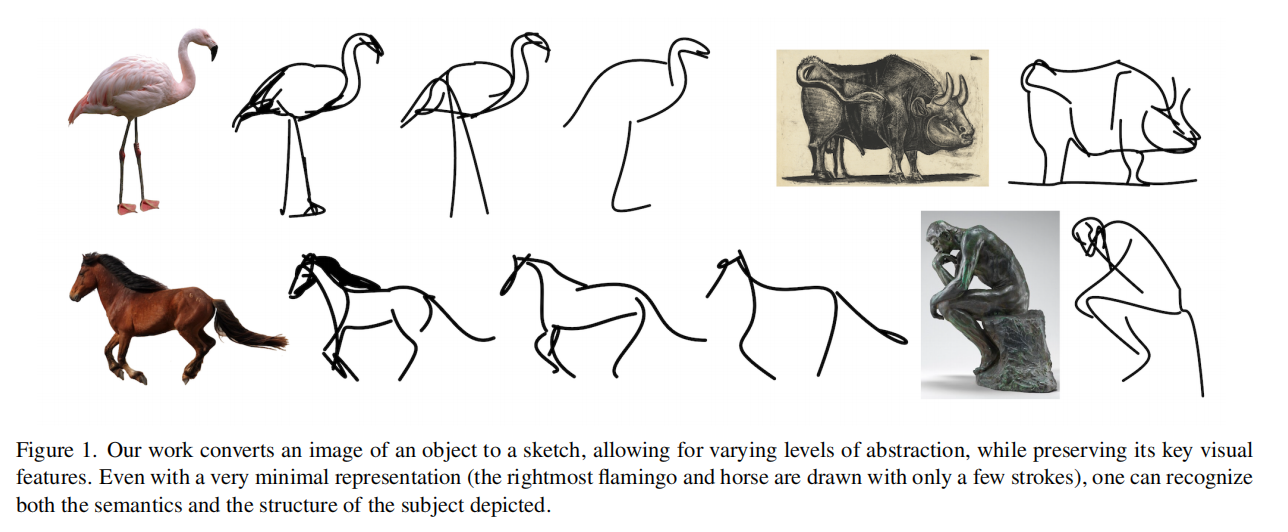

将图片变成简笔画,对计算机是非常难的一项任务,需要理解重点特征在哪里,抽象是非常难以做到的

先前的工作抽象都是事先定义好的,笔画多抽象小,笔画少抽象多,有什么素描数据就学出什么模型,属于data-driven的方式,形式风格非常受限,违背了图像处理的初衷,且种类有限不够丰富
摆脱有监督的依赖和需要一个语义学习很好的模型就是CLIP,通过文本和图片的配对对语义信息抓取的很好,对物体非常敏感,不受图像风格影响,也有出色的zero-shot能力,能够直接用
Method

每个笔画用了4个点控制, $s_i={p_i^j}^4_j=1={(x_i,y_i)^j}^4_{j=1}$ ,通过模型控制4个点的位置,就能控制曲线,通过贝兹曲线的计算就能改变曲线形状最后变成简笔画形式
把CLIP当作teacher,蒸馏自己的模型
Loss Function
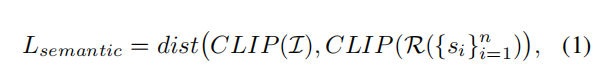
比如这里描述的是马,那么得到的特征应该和原始特征都是马的意思,就得到了 $L_s$
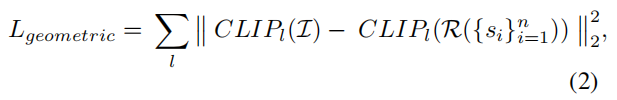
简笔画特征与原始特征尽可能接近,但是仅有语义匹配也是不行的,比如都是马,但是简笔画马头在右边就和原本图片不匹配了,因此除了语义限制上在几何形状上也有限制,就得到了 $L_g$ ,比如用res50的4个阶段抽特征,用里面的234阶段拿出来算loss而不是最后的2048维特征去算,用前几层算能最大保证几何形状和朝向
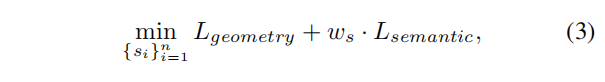
Optimization
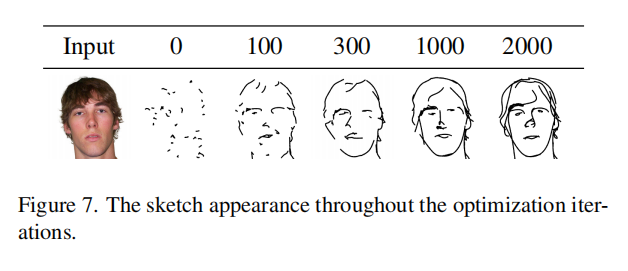
训练需要2000个iteration但是训练很快,在100个iteration就能看出来模型训练的好不好了
Stroke Initialization

此外贝兹曲线的初始化,最开始的点放在哪也是很重要的,需要一个比较稳定的初始化方式,这里是saliency guided,一个预训练好的vision transformer,把最后一层的多头自注意力取个加权平均,去在更显著的区域采点
Result

可以对不常见的物体也生成简笔画

可以达到任意程度的抽象,只需要控制初始化的笔画数量
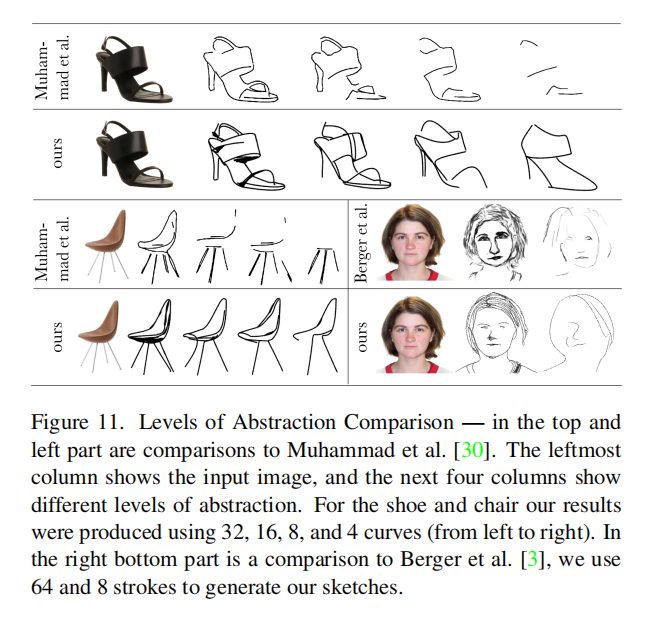
对比其他方法能达到比较好的抽象结果
Limitations
当图像有背景的时候模型效果大打折扣,一个物体是最好的,作者选了一个方法把物体抠出来变成前景再做的,但可能不是最优结构,因为这变成了two-stage
人画简笔画是序列性的,可能一笔画出了,但是CLIPasso是同时生成的
控制简笔画来控制抽象程度是优点也是局限,需要事先定义好,达到同等程度抽象化也需要不同笔画很难定义,让模型自己定义用两三划还是更多来抽象

