CLIP-ViL:CLIP在视觉下游任务的实验性文章
Abstract
实验性文章,把CLIP拿到多模态来初始化还能继续提高下游vision language task的准确度
Introduction
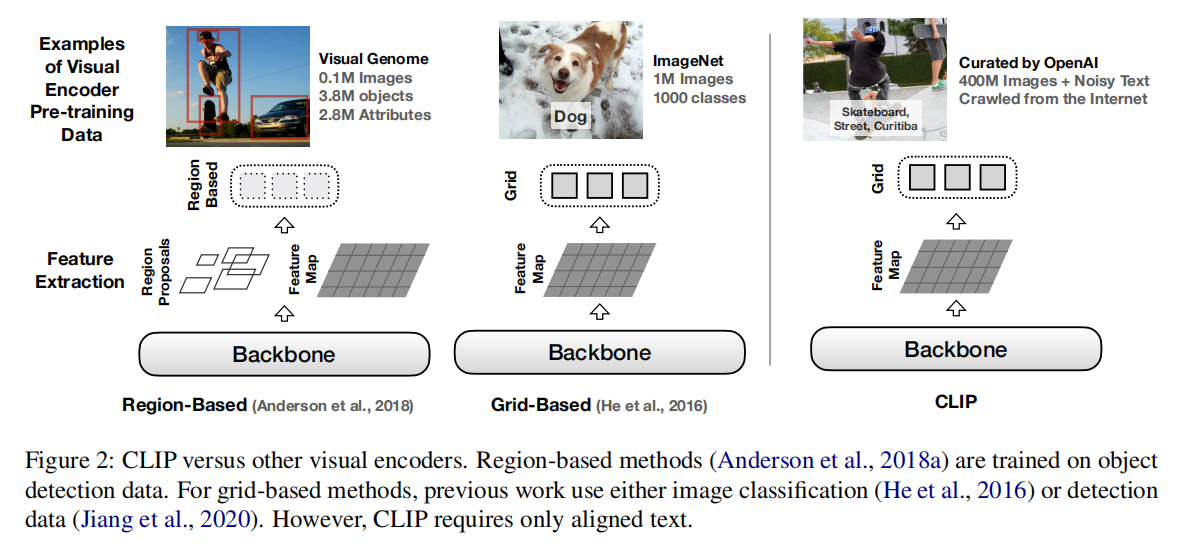
主要贡献:第一个大规模的用CLIP预训练好的模型当作视觉编码器的初始化参数,在各种下游任务上做empirical study
Experiments
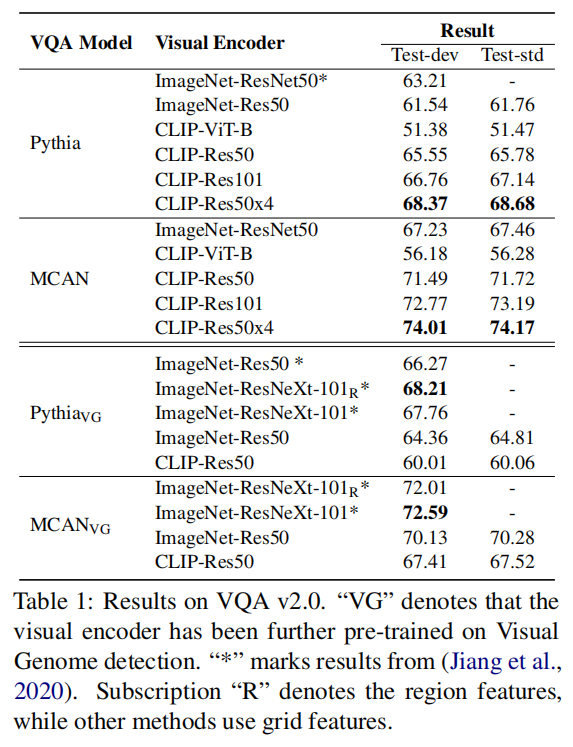
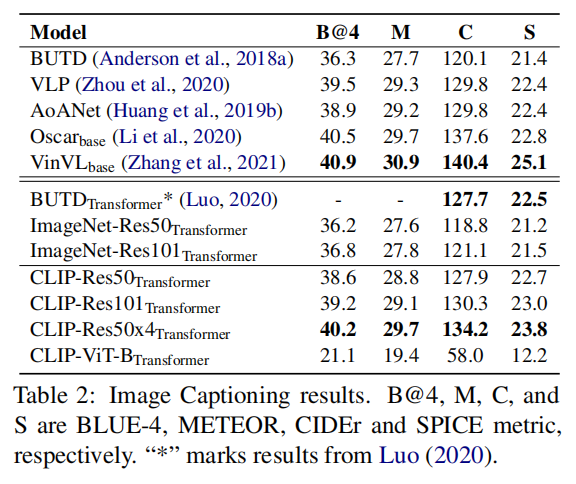
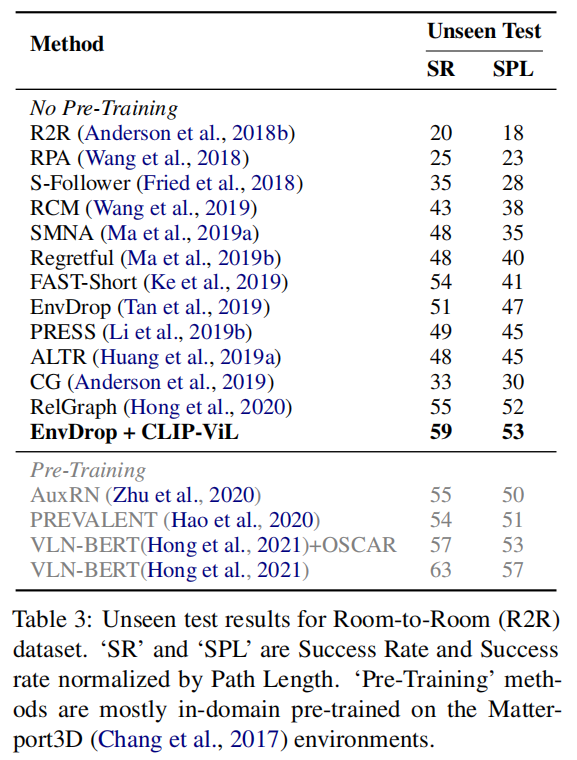
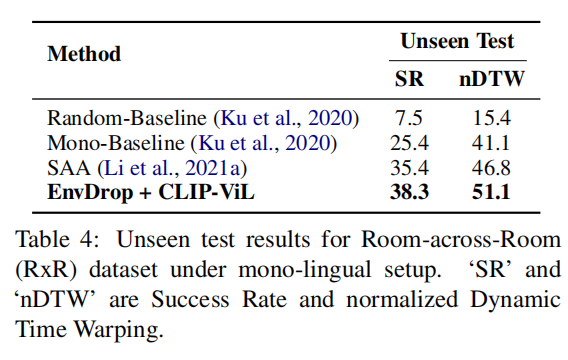
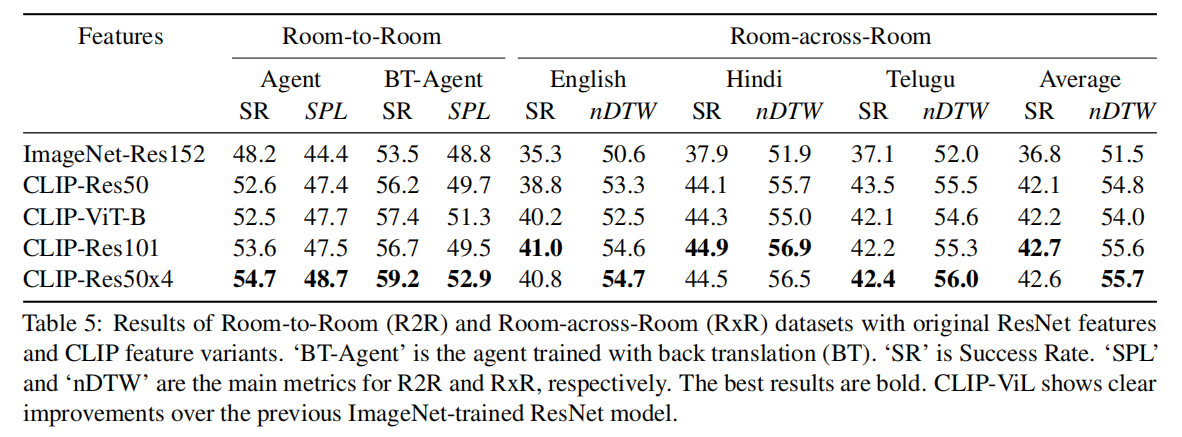
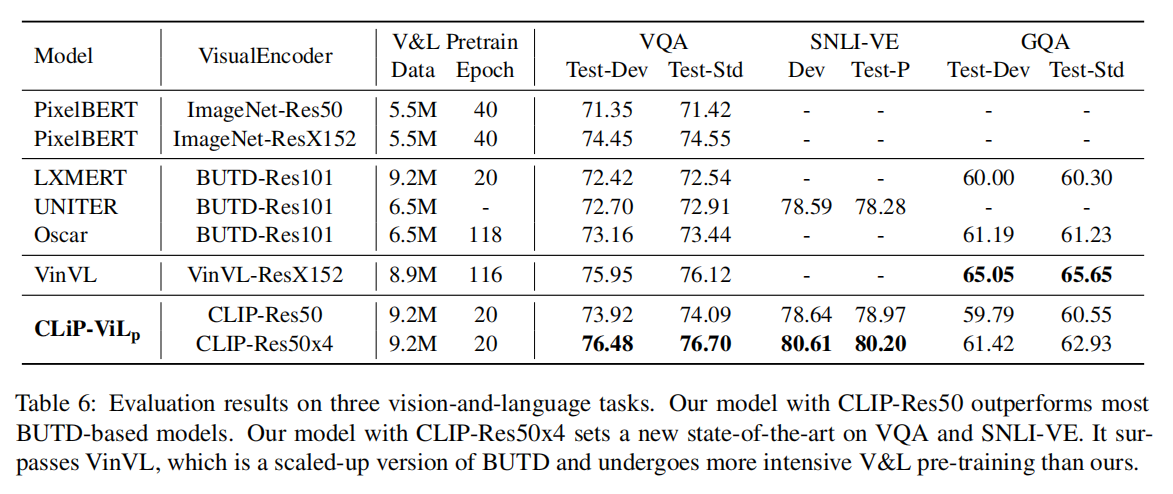
实验性文章,把CLIP拿到多模态来初始化还能继续提高下游vision language task的准确度
主要贡献:第一个大规模的用CLIP预训练好的模型当作视觉编码器的初始化参数,在各种下游任务上做empirical study
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY 4.0 CN协议 许可协议。转载请注明出处!
Maybe you could buy me a cup of coffee.

Scan this qrcode
Open alipay app scan this qrcode, buy me a coffee!

Scan this qrcode
Open wechat app scan this qrcode, buy me a coffee!