论文地址:UniXcoder: Unifified Cross-Modal Pre-training for Code Representation
论文实现:https://github.com/microsoft/CodeBERT/tree/master/UniXcoder
UniXcoder:编码器-解码器预训练+对比学习表征
Abstract
为了支持代码相关的理解和生成任务,最近的工作都是在尝试训练一个联合的encoder-decoder模型,但这种架构对回归任务是次优的,特别是仅需要解码器来进行推理的时候。本文提出了UnixCoder,一个统一的跨模态预训练的编程语言模型,利用了AST和注释来增强代码表征;此外还使用这种多模态内容来对比学习得到代码片段表征。在五个任务九个数据上实验,还构建了zero-shot code-to-code search数据集来评估代码片段表征
Introduction
与目前的联合编码器解码器模型相比,UniXcoder可以更好地应用于自回归任务,比如需要解码器方式来执行高效推理的代码补全。除了只考虑代码视为输入外,还把代码注释和AST作为多模态来增强代码表征,注释保留了语音信息,AST保留了句法信息,作者把AST变成了一个序列
三个预训练任务来支持不同的下游任务:
- 掩码语言模型,单向语言模型,去噪目标
主要贡献:
- 提出了一个统一的跨模态预训练模型
- 提出了一个把AST转化为序列并保留所有信息的方法,使其可以和源码序列,注释并行训练
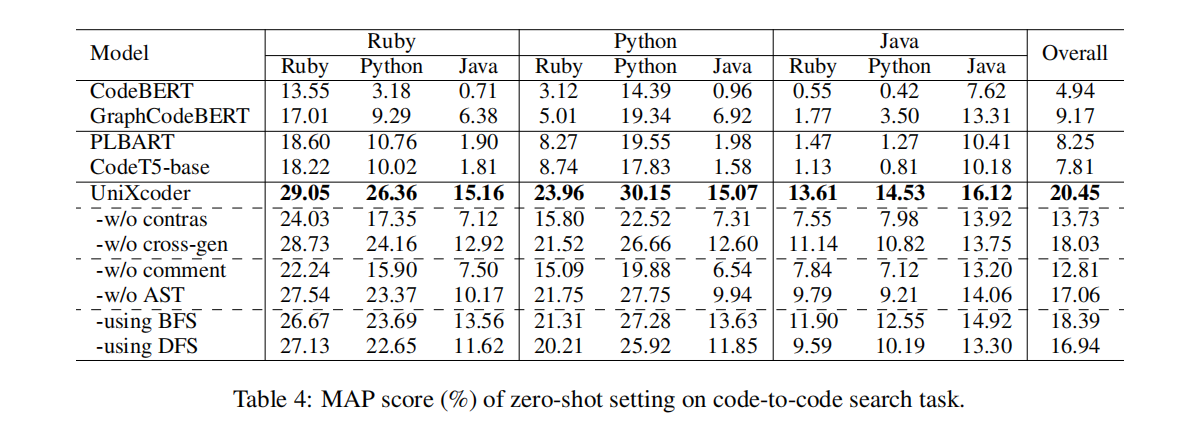
- 提出使用注释来学习代码片段表征和构建了zero-shot code-to-code search数据集
- 实验很多
UniXcoder
Input Representation
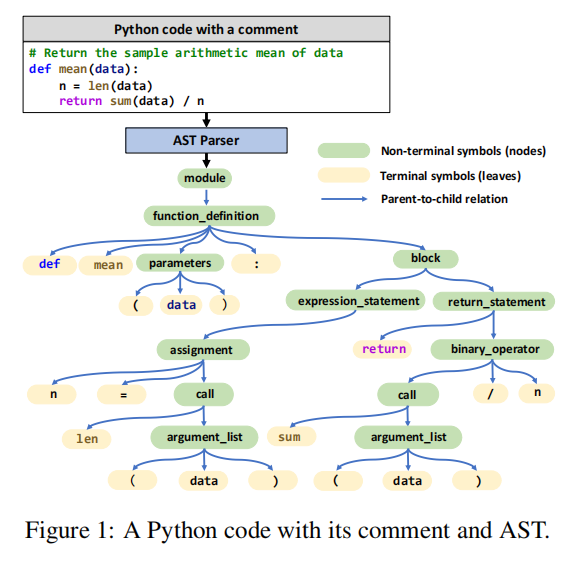

把AST变成序列方法如上,left和right是后缀,比如 “parameters → (data)”就变成“<parameters,left> ( data ) <parameters,right>”
Model Architecture
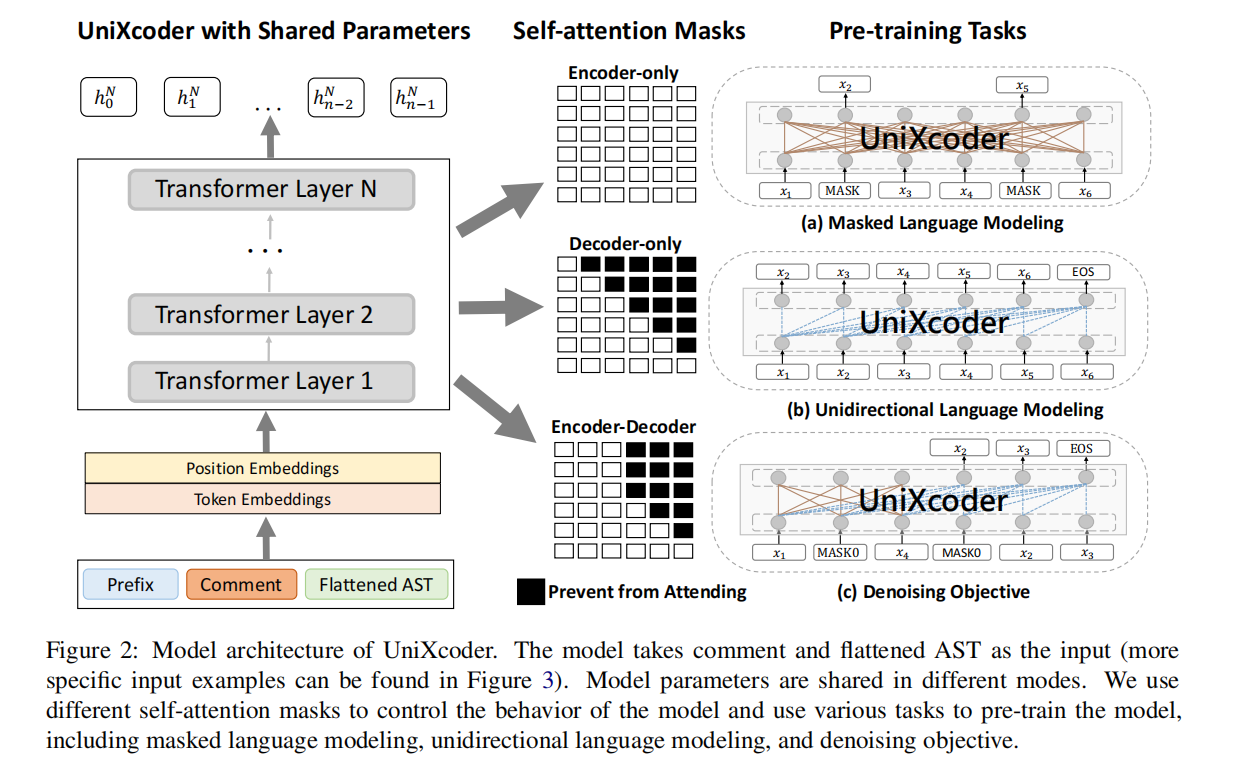
Pre-training Tasks
Masked Language Modeling
图2a,标准的掩码语言模型
Unidirectional Language Modeling
图2b,自回归任务
Denoising Objective
图2c,在BART和T5里面很有用,随机遮蔽任意长度的片段然后预测。使用和T5一样的去噪目标,把输入序列拆分为 $max([\frac{n\times r}{l}],1)$,n是序列长度,r是损坏率,l是遮蔽片段的平均长度
Code Fragment Representation Learning
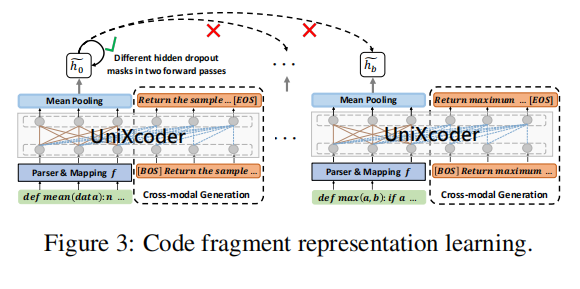
multi-modal contrastive learning:使用同一输入的不同hidden drop mask作为正样本,同一Batch的其他样本为负样本
cross-modal generation:用AST序列来生成注释
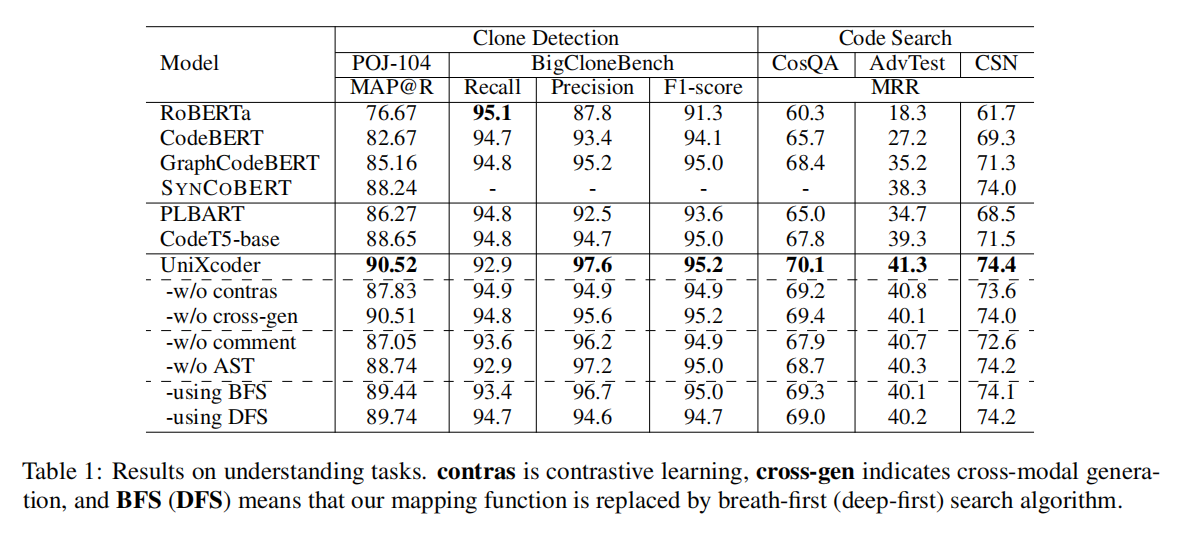
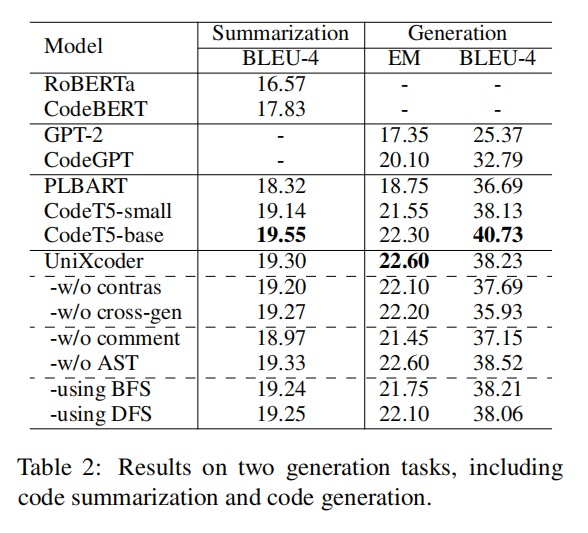
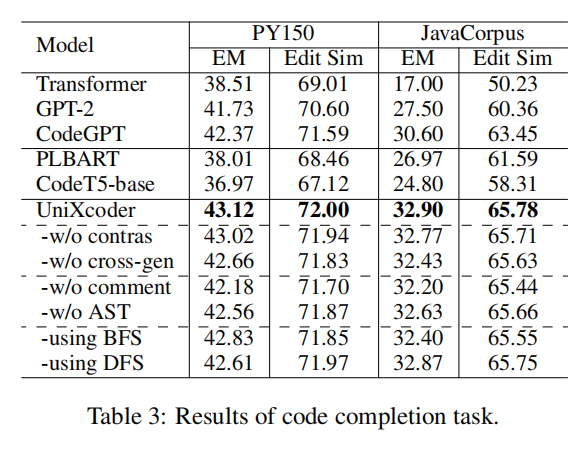
Experiments