论文地址:MSA Transformer
论文实现:https://github.com/facebookresearch/esm
facebook蛋白质esm系列工作,主线是利用蛋白质语言模型实现从蛋白序列预测蛋白质结构和功能,在ESM-1b的基础上作出改进,将模型的输入从单一蛋白质序列改为MSA矩阵,并在Transformer中加入行、列两种轴向注意力机制,对位点 $x_{mi}$ 分别计算第m个序列和第i个对齐位置的影响,充分利用二维输入的优势
ESM-MSA-1b:轴注意力蛋白质预训练
Abstract
迄今为止的蛋白质语言模型都是从独立的序列进行推理,而计算生物学长期存在的方法是分别拟合各个家族,从进化相关序列家族中进行推理,本文工作结合了这两种范式,将序列集合以多序列对齐的形式输入,使用行列注意力,跨蛋白质家族的掩码语言模型目标
Introduction
由于进化不能自由地在折叠的三维结构中接触的位点上独立选择氨基酸的身份,因此模式被印在进化选择的序列上,对蛋白质结构的限制可以从相关序列的模式中推断出来
目前蛋白质语言的新工作都是大规模的网络而不是分别拟合每个家族序列,在推理阶段用单条序列端到端的方法替换多阶段的计算生物学中传统的方法
模型结构使用了轴注意力,掩码语言模型目标函数
Methods
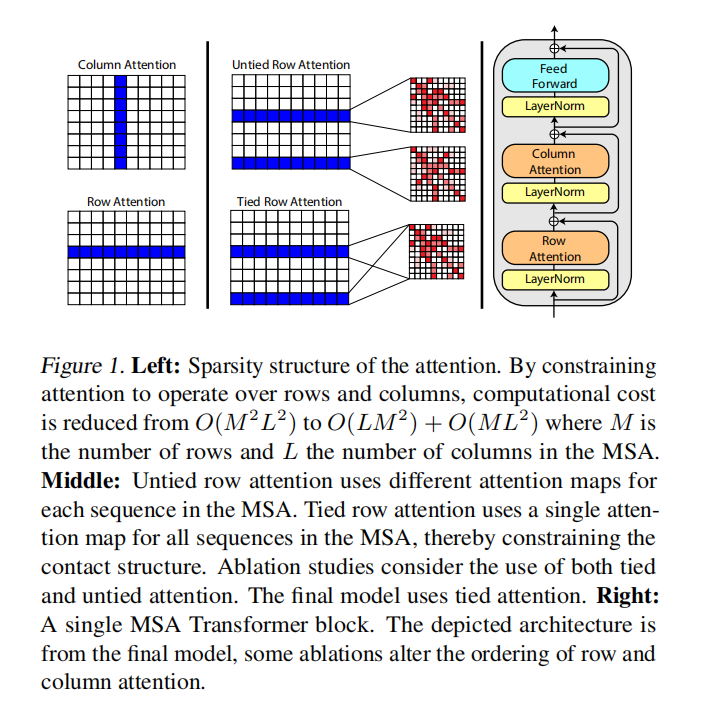
MSA Transformer的输入为一系列二维MSA矩阵,每个MSA是一组蛋白序列的多序列比对文件
MSA矩阵存储来自不同物种的同类蛋白序列。矩阵的每一行是一条来自特定物种的蛋白序列;每一列在该类蛋白中处于同一位置,记录不同物种在该位置的氨基酸取值
Token Embedding
将不同氨基酸用整数表示,形成一个整型向量。词库包括20中标准氨基酸、5种非标准氨基酸和4种特殊字符,共29个数字
Position Embedding
-
sequence embedding
- 为序列的每个位置,也就是每一列赋一个序号
-
position embedding
- 为每条序列,也就是每一行赋一个序号
- 位置嵌入使得MSA中的行和列有独一无二的序号,每一行或每一列将被识别为不同的。
Pre-training
模型使用masked training方法进行训练,直接输出的是每一个masked token处为各种氨基酸的概率。然而本文的主要目标并不是得到这些概率,而是要通过训练后的attention map预测蛋白质二、三级结构
-
二级结构预测(second structure prediction)
- 训练一个Netsurf模型,基于MSA Transformer的特征表示向量(representation)预测蛋白质的8种蛋白结构,准确率为72.9%
-
三级结构预测(contact prediction)
- 基于MSA Transformer各层、各注意力头的attention map,训练logistic回归模型,对蛋白质三级结构进行预测
Axial Attention
针对二维输入数据的特征,提出两种轴向注意力机制:行注意力(row attention)和列注意力(column attention)
为了降低算法的时间复杂度,轴向注意力将来自二维平面的注意力分解为纵、横两个方向。轴向注意力认为MSA中某位点受到其他位点的影响主要来自于其所在的行和列,而矩阵中其他位置的影响可以忽略不计,对位点只需计算第行和第列对它的attention权重
行注意力计算位点所在行的注意力权重,本质是提取该点所在蛋白序列的信息,计算同一蛋白序列中不同氨基酸之间的相互影响权值,能够反应这些氨基酸在蛋白二、三级结构中的相互作用,进而推测蛋白结构
列注意力计算位点所在列的注意力权重,本质是提取该位置上氨基酸的共变信息
Result
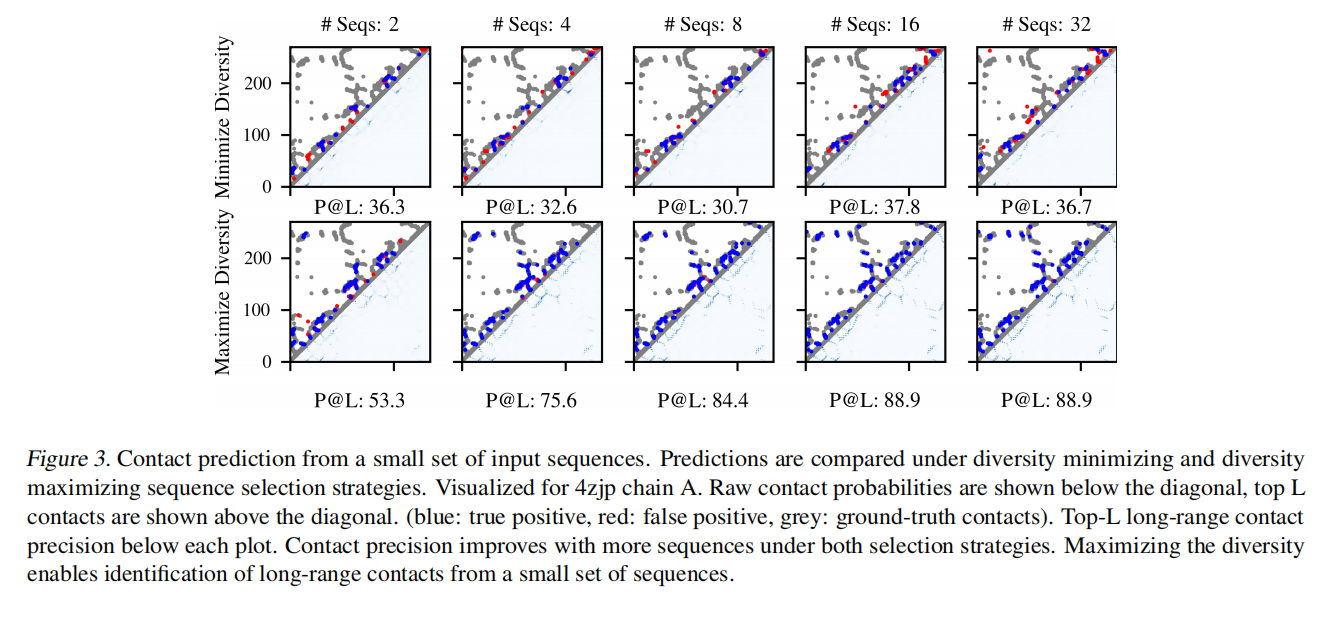
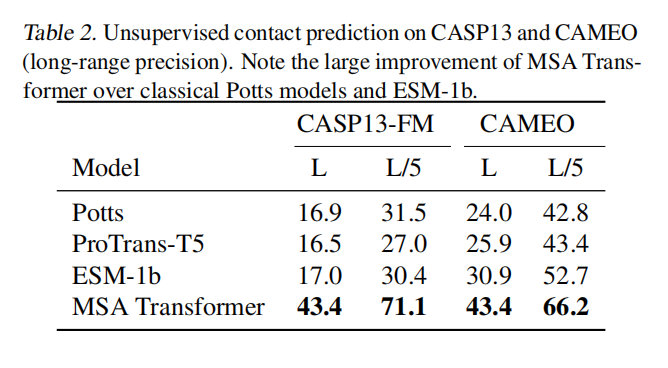
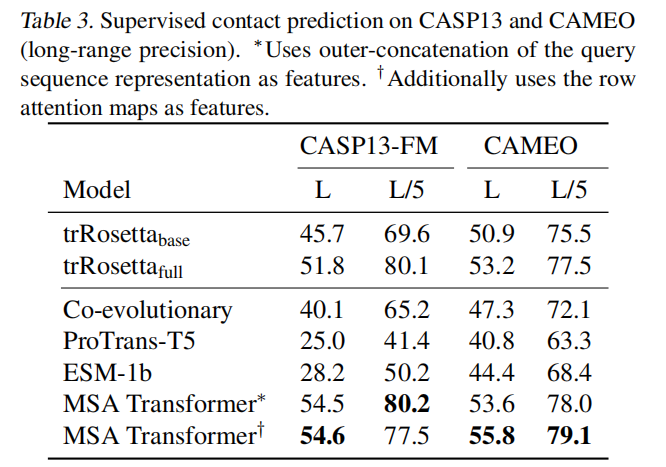
- 与其他模型对比的表现
- 氨基酸的接触模式(contact pattern)能够直接被行注意力头学习,蕴含在行注意力的attention map中
- 基于训练发现的接触模式,MSA Transformer能够对蛋白质的接触情况进行预测(contact prediction),预测准确率显著优于Potts等其他模型(不论输入MSA的深度如何),尤其是在MSA深度较小时,优势更加明显
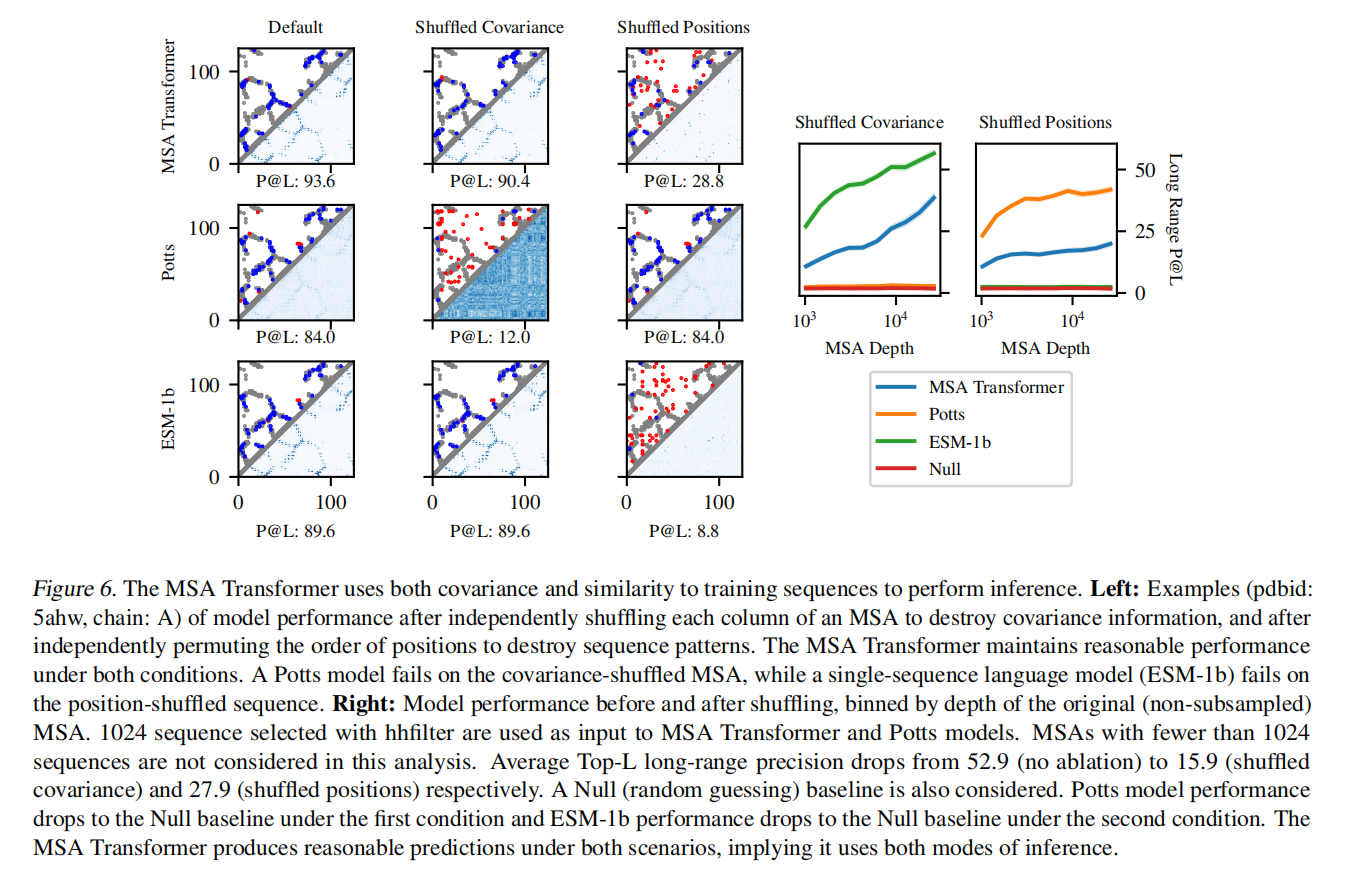
- 探究MSA Transformer预测蛋白结构的机制
- 学习协方差(与Potts模型一致)
- 随机打乱MSA每一列氨基酸的排列,破坏该列的协方差特性,发现Potts模型预测准确率降到随机预测(random guess)级别,ESM-1b预测结果不受影响,MSA Tansformer预测准确率下降,但仍有有效预测能力。说明MSA Transformer能够学习协方差特性,但不唯一依赖于协方差特性
- 学习序列规律(与ESM-1b一致)
- 随机打乱MSA中列的排列顺序而保持每一列内部不变,破坏每条序列的规律,发现ESM-1b模型预测准确率降到随机预测(random guess)级别,Potts模型预测结果不受影响,MSA Tansformer预测准确率下降,但仍有有效预测能力。说明MSA Transformer能够学习序列规律,但不唯一依赖于序列规律
- 学习协方差(与Potts模型一致)

