论文地址:MMF3:Neural Code Summarization Based on Multi-Modal Fine-Grained Feature Fusion
MMF3:token层次融合代码多模态
Abstract
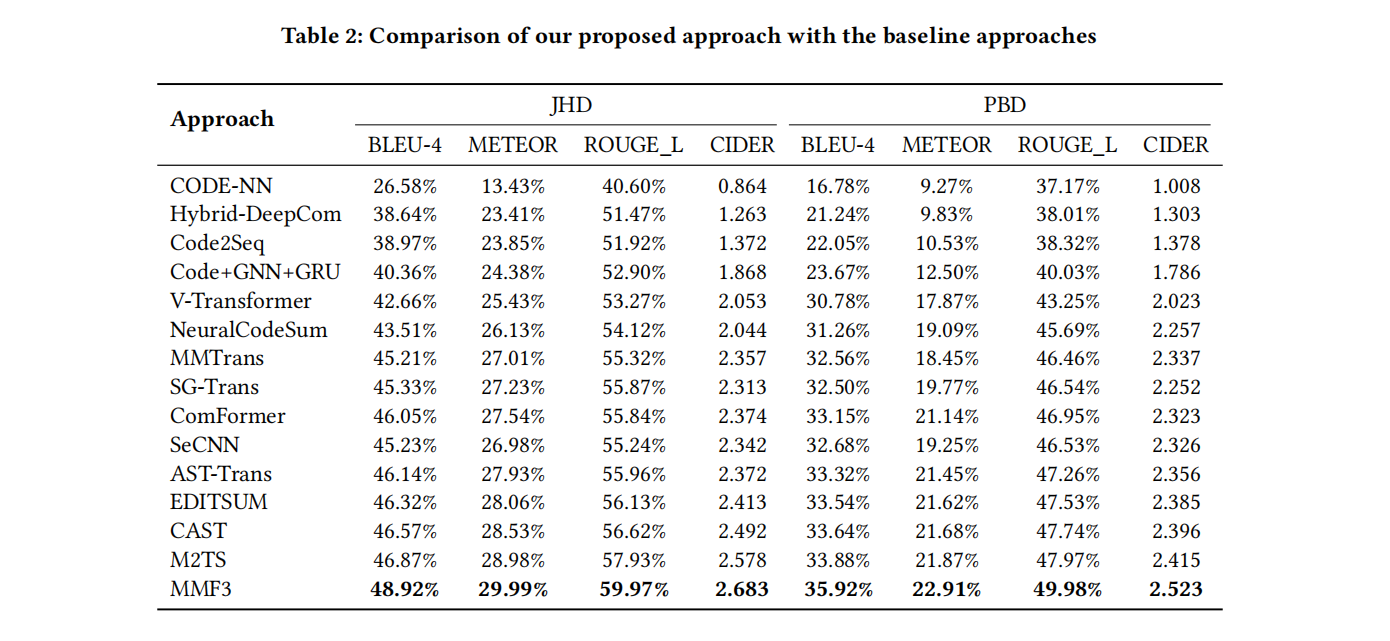
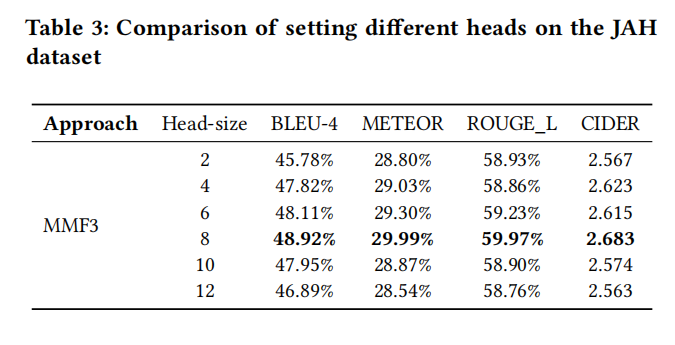
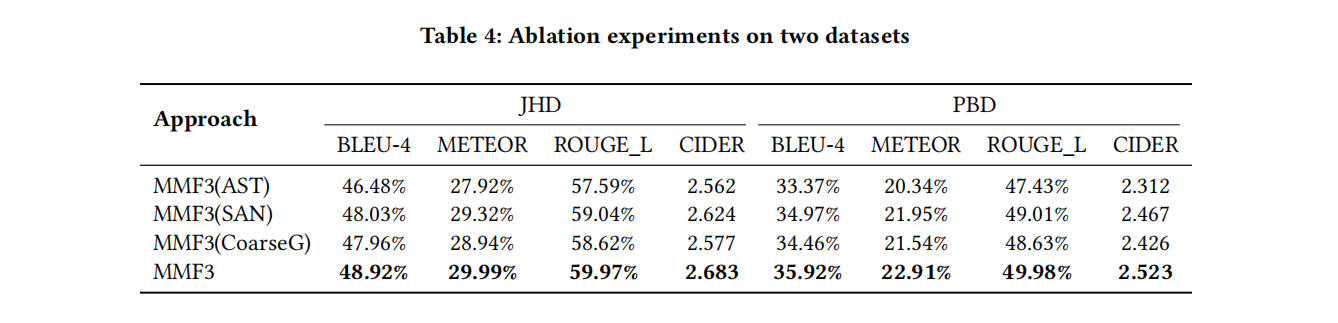
目前大多现有的方法都是把代码的多模态进行粗粒度的融合,比如code和AST在最高层次融合。这种融合很难在精细的不同模态的代码元素之间有效学习关系,本文旨在通过在node/token层次进行更准确地对齐和融合语义和句法结构信息,方法使用transformer架构,在python和java数据集上效果不错
Introduction
目前融合AST和code两种模态依旧是比较困难的,传统的融合方法还是做的向量拼接,比如MMTrans使用了SBT序列和图,通过分别做自注意力机制再拼接起来给decoder,这种方法仍然算粗粒度的,没有很好的挖掘不同模态之间的关系
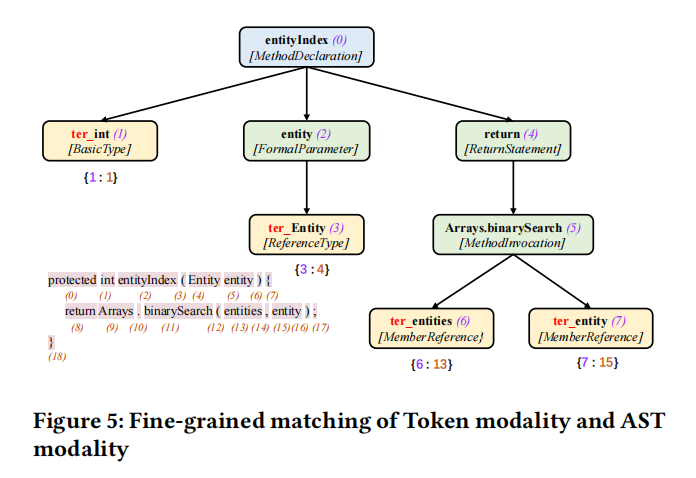
融合策略:
- 序列embedding和AST embedding分别通过编码器得到feature,通过自注意力机制得到combined feature
- 序列embedding,AST embedding和combined feature融合,code token和AST node一样就把node embedding加到token embedding上得到fine-grained fusion
Approach
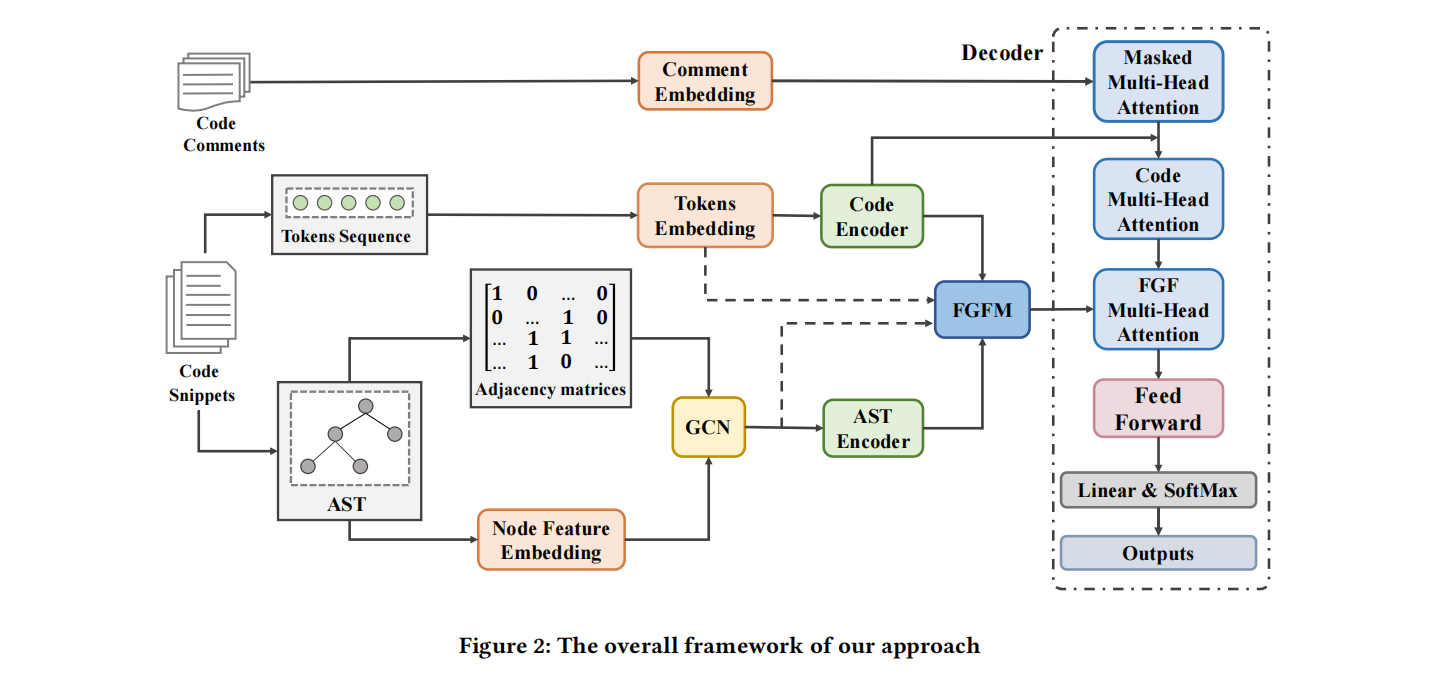
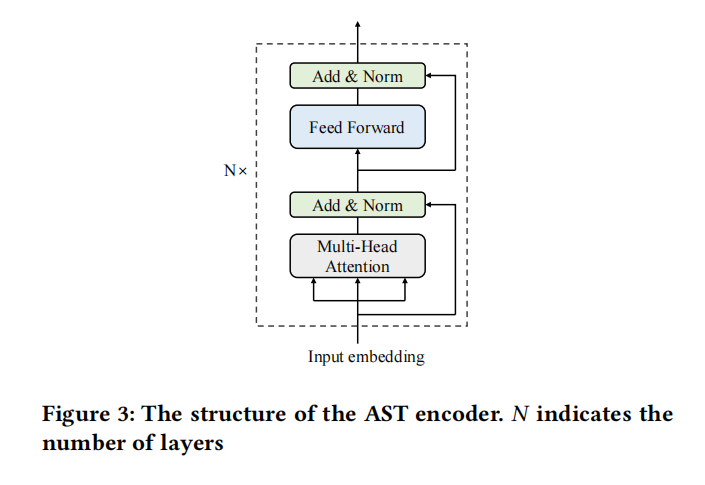
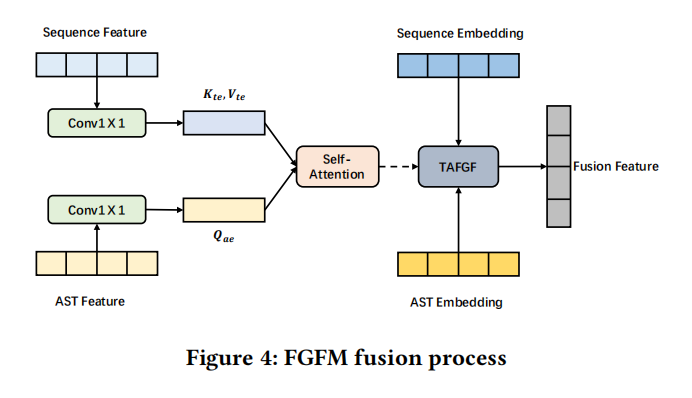
这里特征过了一个1x1的卷积核,经过自注意力机制得到第一个融合F1;两个embedding中token一样的相加得到第二个融合F2
Experiment