论文地址:On the Evaluation of Neural Code Summarization
论文实现:https://github.com/DeepSoftwareAnalytics/CodeSumEvaluation
比较实在的一篇文章,实验内容很详尽
CodeSumEvaluation:不同指标对模型结果影响
Abstract
本文系统性地在5个SOTA模型上,用6个广泛使用的BLEU变种,4种预处理操作和组合,3种广泛使用的数据集上进行了实验,评估结果表明一些因素对模型性能和模型之间的排名有很大影响。特别是1. BLEU指标的不同变种对模型结果有很大影响,此外本文还解决了在常用的包里面BLEU计算的未知bug,最终进行人工评估发现BLEU-DC是最适合人类的观念;2. 代码预处理选择有很大(-18%到+25%)的影响;3. 重要数据集的特征(语料大小,数据切分方法和重复率)对模型评估有很大影响。本文对不同场景下选择最佳方法提出了建议,并且分享了一个工具包
Introduction
本文聚焦一个问题:怎么更准确和全面的评估代码摘要模型
-
五个模型:CodeNN,Deepcom,Astattgru,Rencos,NCS
-
六个BLEU变体
-
四个常见的预处理操作
-
三个常用数据集:TL-Codesum,Funcom,CodeSearchNet
-
六个BLEU变体和四个处理操作涵盖了2010年来大部分的研究,每个数据集都至少有五项工作
第一个主要发现是BLEU指标不同导致评估结果不同:
-
有一些包计算BLEU有bug:
-
算出来分数高了100%,甚至700%,极大的夸大了模型性能
-
不同版本的包的分数也不同,不同论文直接没法比
-
-
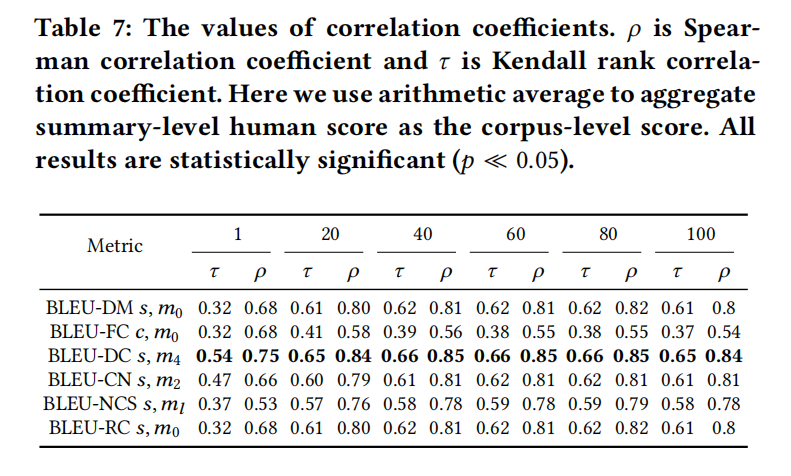
本文发现BLEU-DC是和人类关联最贴近的
第二个主要发现是预处理有-18%到+25%的影响
第三个主要发现是不同数据集有影响
Background
Bleu
- BLEU-CN:它通过在 $n≥2$的 $p_n$ 的分子和分母上加1,应用了类似拉普拉斯的平滑
- BLEU-DM:NLTK3.2.4的smooth method=0
- BLEU-DC:NLTK3.2.4的smooth method=4
- BLEU-FC:NLTK的未平滑的Corpus BLEU
- BLEU-NCS:NCS文章里,它通过对所有 $p_n$ 的分子和分母都加上1来应用类似拉普拉斯的平滑
- BLEU-RC:未平滑的Sentence BLEU,为了避免除零的误差,它在分子中加一个小数字10−15,在 $p_n$ 的分母中加一个小数字10−9
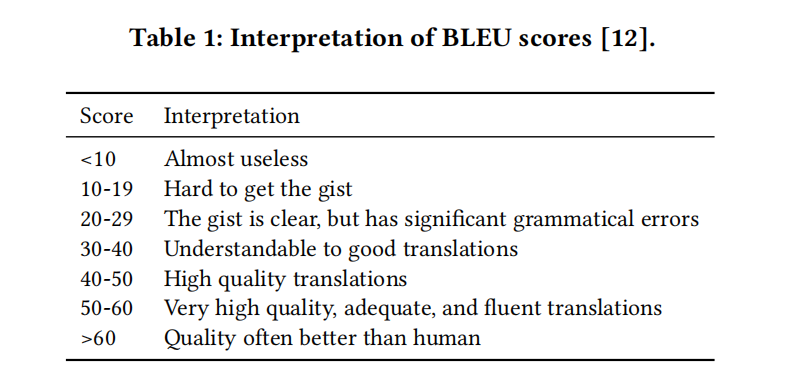
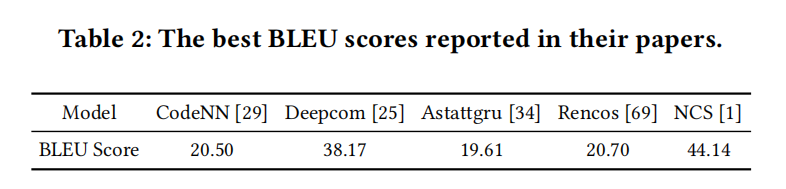
表1是谷歌对BLEU分数的解释
表2是现有方法在文章里汇报的分数,虽然astattgru只有19.61,Deepcom有38.17,但实际上astattgru比Deepcom还相对好一些
Experiment
Experimental Settings
实验在252GB主内存的机器和4张v100 32G,最大200个epoch,patience=20,每个实验进行了3次
Analysis of Different Evaluation Metrics
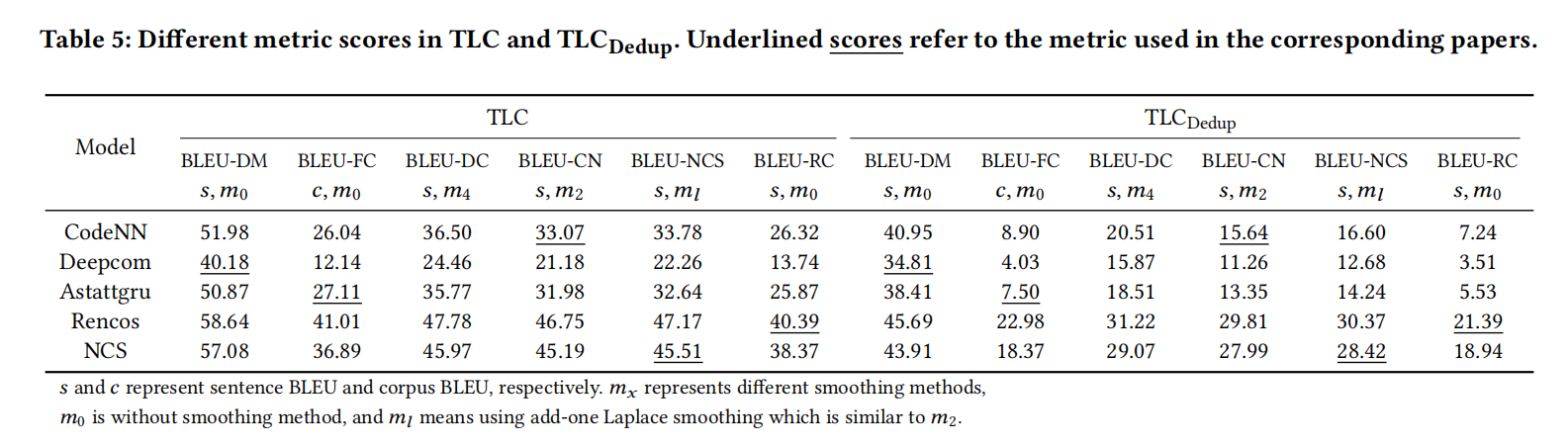
Sentence v.s. corpus BLEU
sentence BLEU对每个句子的贡献的相等,而对于sorpus,每个句子的贡献与句子的长度呈正相关
Smoothing methods
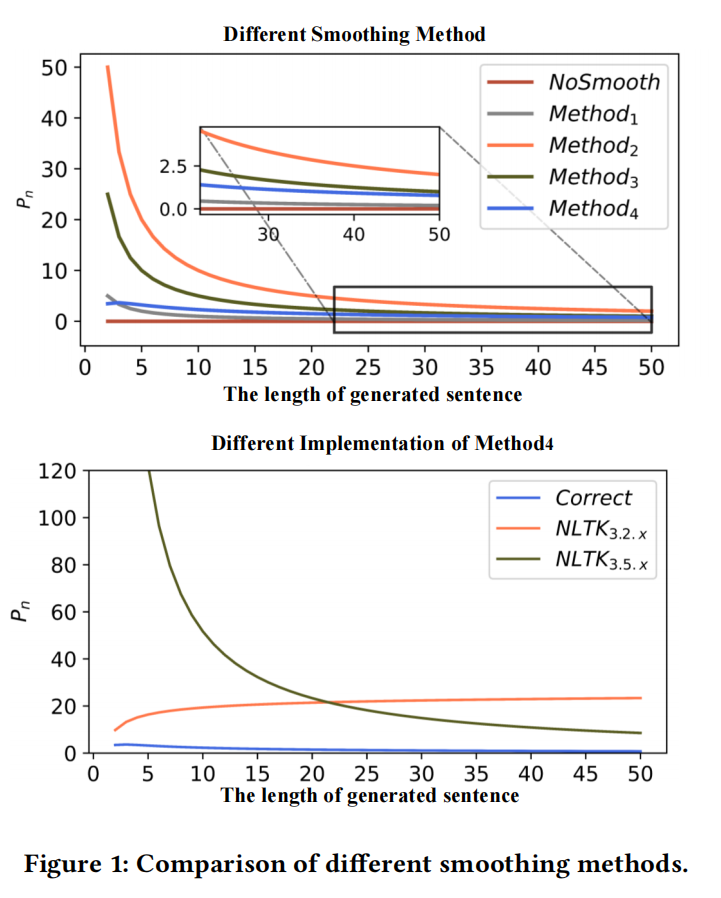
采用什么平滑方法处理匹配的n-gram为0的情况
Bugs in software packages
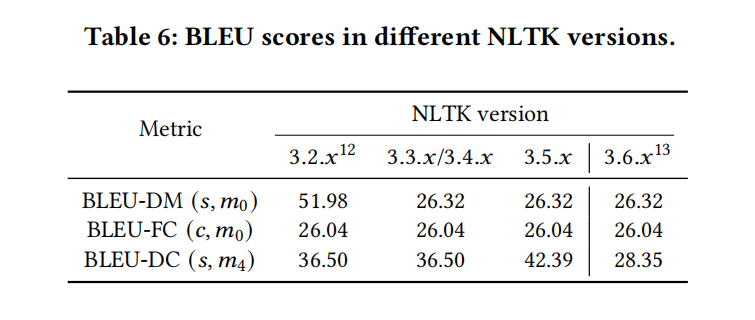
表6可以看出不同版本的NLTK即使在同一个参数设置下差距还是非常大
Human evaluation
The Impact of Different Pre-processing Operations
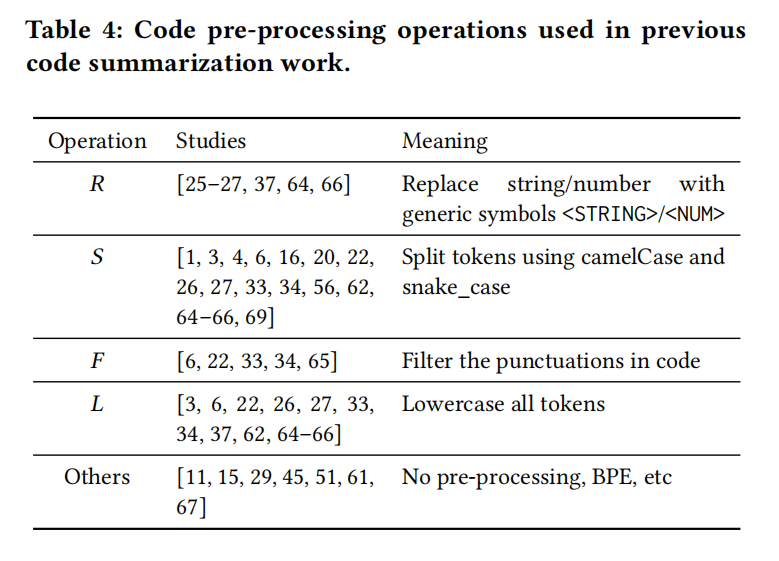
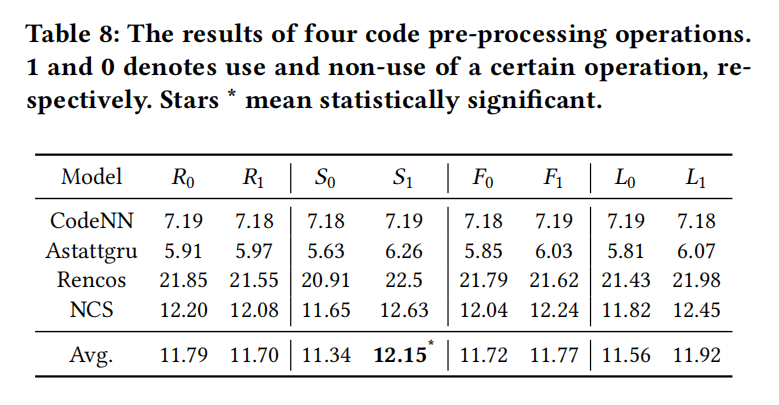
从表8可以看出执行分词操作的效果几乎是肯定更好的
How Do Different Characteristics of Datasets Affect the Performance?
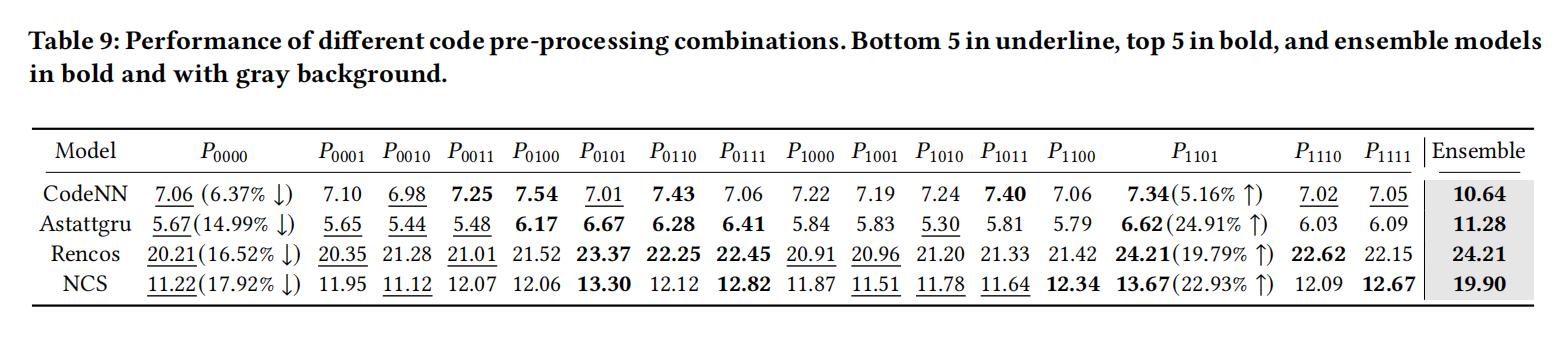
P中的0和1表示是否执行某种预处理操作