论文地址:Switch Transformers:Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
论文实现:https://github.com/google-research/t5x
博文参考:https://www.linkresearcher.com/theses/90dd50dd-a0fa-4779-bb43-74b4f9cdee47
Switch Transformers:混合专家网络稀疏大参数
Abstract
通过MoE机制对每个输入样本选择参数,这种稀疏激活的模型有着非常粗暴的参数量,但可以接受的计算开销
Introduction
MoE可以为不同的输入选择性地激活模型中的一部分参数参与计算,这样在增大模型参数量的同时,计算量可以维持相对不变
一种典型的MoE框架由一个门控子网络(Gating network)和多个专家子网络(Expert odel)构成,门控网络为输入x计算各个专家网络输出所占的比重,然后采取加权求和的方式得到最终的输出
本文就基于MoE的思想,将Transformer中的前馈全连接子层(Feed-Forward Network,FFN)视为Expert,使用多个FFN代替原来单一的FFN,并且使用了最简单的路由选择策略,将K设置为1,即不同的输入只会选择一个FFN进行计算。这样相比较于原来的结构,计算量只增加了路由选择的计算量,而新增的计算量相比较于原来的计算量而言可以忽略,这样就实现了增大模型参数的同时维持相对不变的计算量
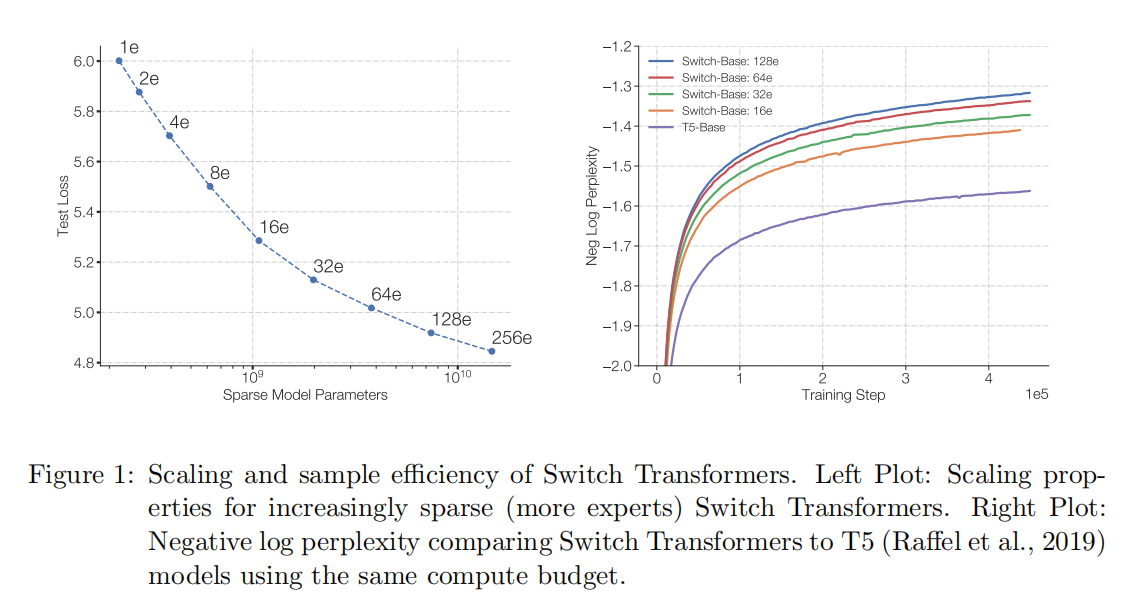
Switch Transformer
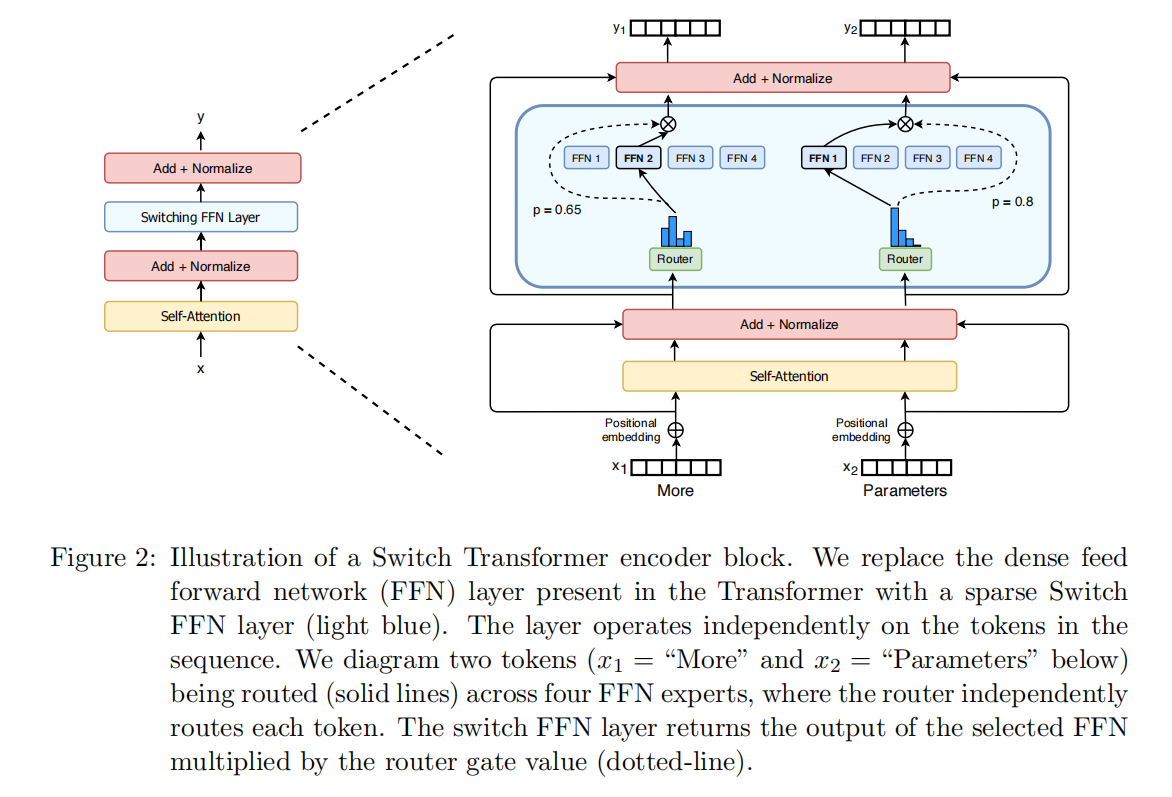
Switch使用了一组FFN(最多使用了2048个,即Switch-C),下方输入的token首先经过一个名叫Router路由的可学习的权重矩阵,Router得到每个token的概率值,概率最大的那一个(对应于Router中的直方图),被映射到第几个FFN。图中,Router直方图的第二列概率值最大,因此下层的输入被路由到第二个FFN中
Simplifying Sparse Routing
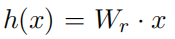
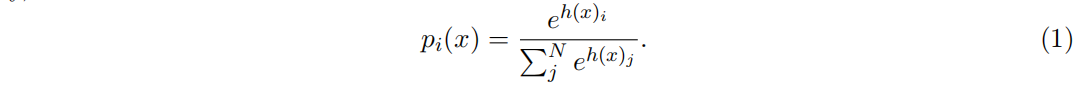
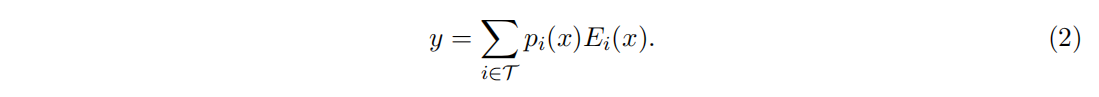
路由选择的数学形式如上
本文中使用了一个创新的路由策略,即每次只发给一个专家,这样可以简化路由的计算量的同时保证模型的性能。这样做的优势:
(1)路由计算量减少,只有一个expert激活;
(2)expert中的batch_size(专家容量)至少减半;
(3)简化路由的实现,减少传统MOE方法中通信的代价。
Efficient Sparse Routing
用的Mesh-Tensorflow (MTF)
Distributed Switch Implementation
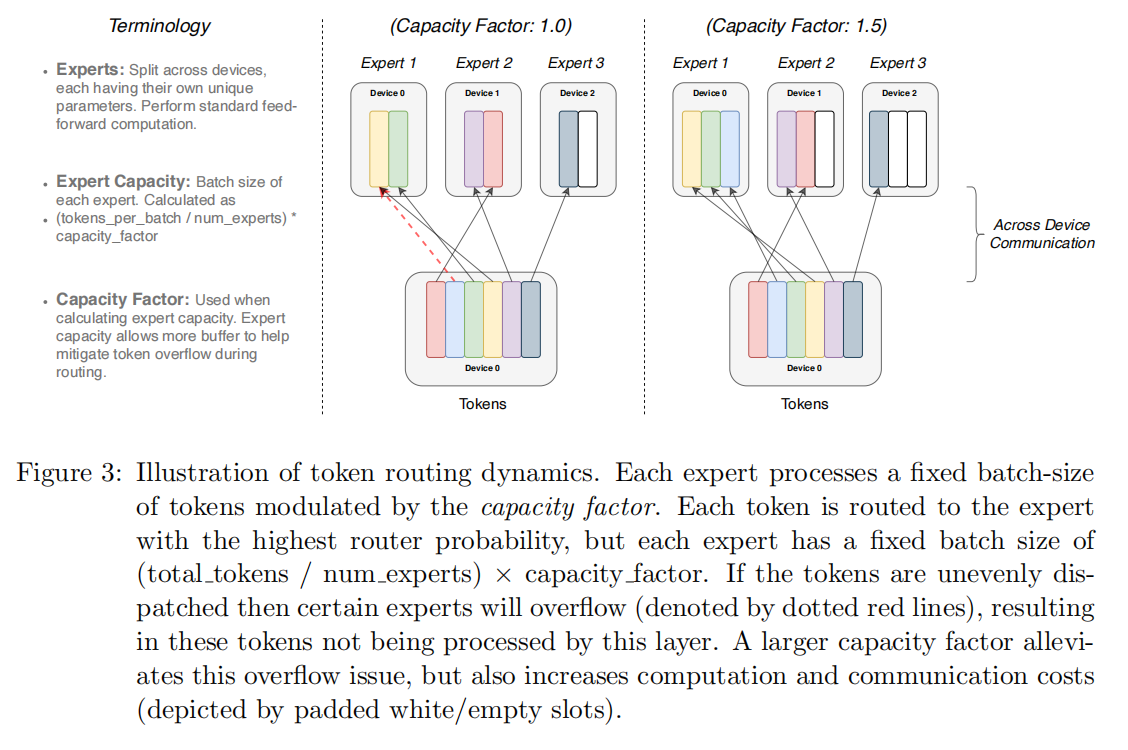
(1)问题:模型编译是静态确定的,计算是动态的,如何确定每一个expert维度;
(2)方法:使用capacity factor扩展,太多的容量导致计算和内存消耗增加,太小的容量导致token被放弃计算传到下一层,结论是经验性的根据“model quality and speed”的权衡来选择较低比例“dropped tokens”
A differentiable Load Balancing Loss
为了促使每个expert都可以拿到近似均匀分布的样本,这里引入负载均衡损失。当 $f_i= p_i= 1/N$ 的时候损失是最小的,给定N个专家,B是batch_size,T是token数,auxiliary loss是f和p的点乘
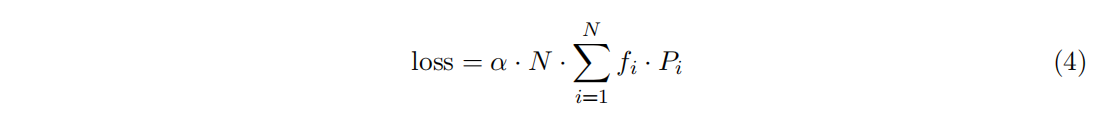
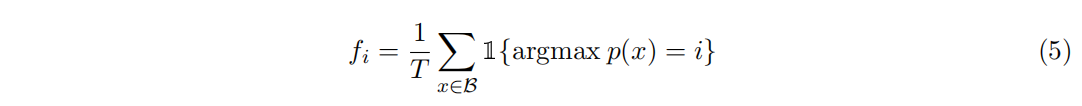
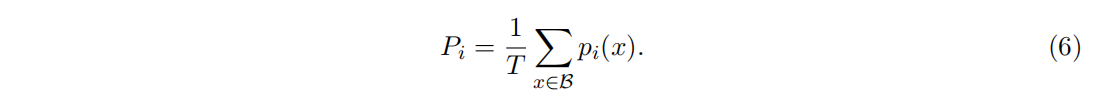
Putting It All Together: The Switch Transformer
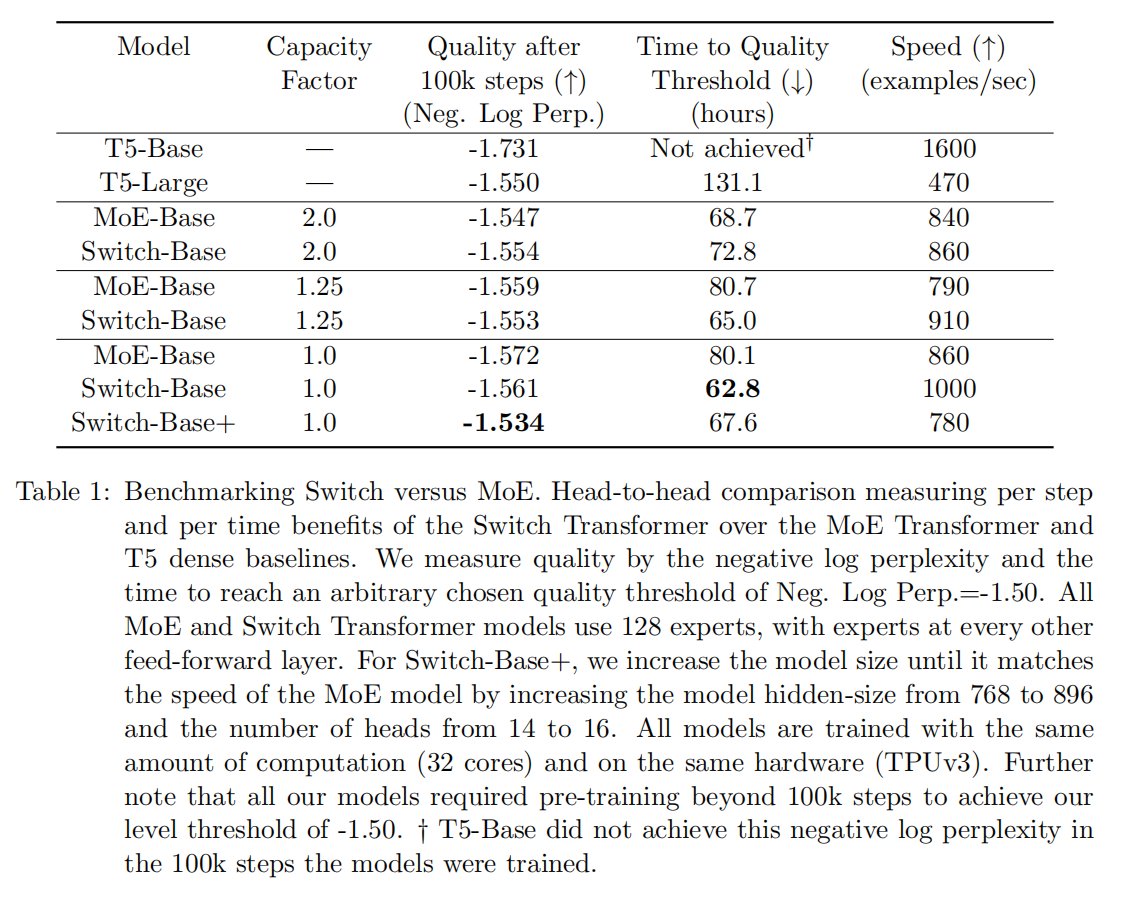
本文采用的实验是T5模型的基础上应用switch transformer和MOE,下面是一些结论:
(1)Switch Transformer比MoE和Dense模型都要好;
(2)Switch Transformer在capacity比较小的时候效果更好;
(3)Switch Transformer比MoE要少一点计算量,如果让它们计算量相等的话,那么Switch Transformer还可以有更多提升(Switch-base-Expand)
Improving Training and Fine-Tuning Techniques
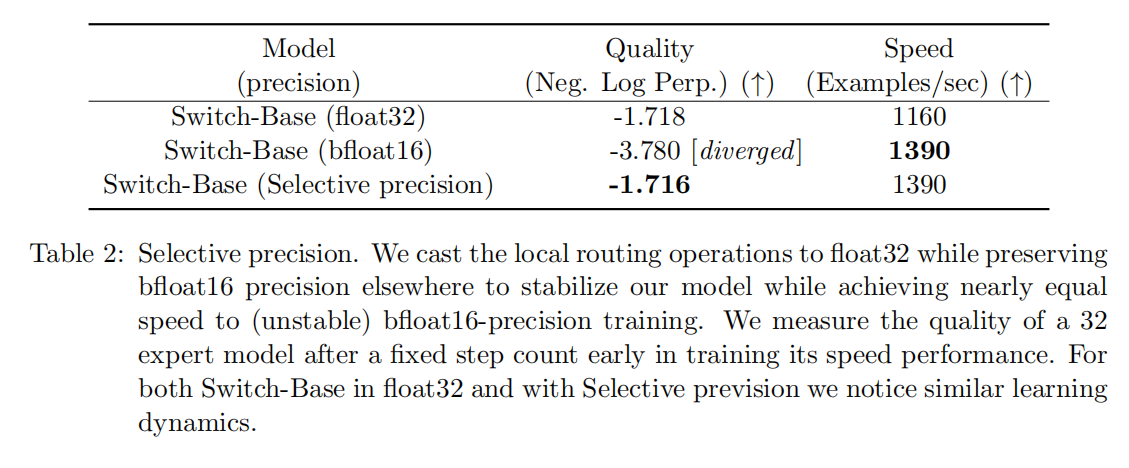
Selective precision with large sparse models
Switch Transformer参数量达到了一万多亿,为了保证计算效率,降低到每次过只过一个expert,这样相当于关闭了模型某些部分的硬切换机制,就引入了稀疏性,而稀疏性会导致模型训练不稳定,换句话说,就是稀疏模型可能会对随机种子比较敏感
当使用bfloat16精度的时候,模型的不稳定性会影响训练性能。这个bfloat16是谷歌的一个格式,全称叫Google Brain Floating Point。MoE Transformer中使用了float32精度来训练,这样会带来一定的通信成本。所以这里作者使用了selectively casting,只在模型的local部分使用float32的精度,这样可以实现稳定性
具体来说,在router的输入端使用float32精度,并且只在router函数中使用,也就是说在当前设备的局部进行计算。在函数结束进行广播通信的时候,使用bfloat16精度,把这个API暴露给网络其余部分,因此float32的值永远不会离开本地设备,而且设备间通信仍然保持低精度。这样既可以从float32精度中获得收益,也不会带来额外的通信成本
下面这个表说明了这种方法的好处,可以看到,作者提出的这种方法可以保证和bfloat16一样的训练速度,但是获得了媲美float32精度训练的稳定性
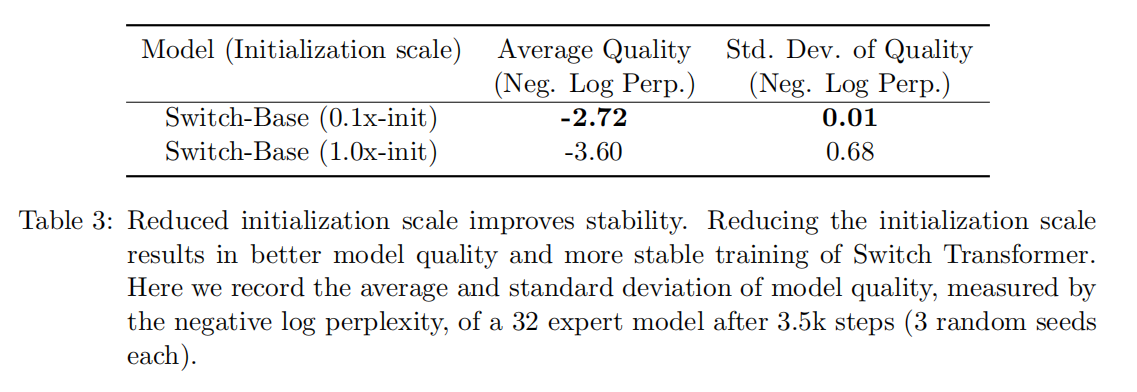
Smaller parameter initialization for stability
为了保证模型的稳定性。作者观察到,在Switch Transformer中,合适的初始化方法也是成功训练的一个重要因素。他们的做法是,用均值μ=0,标准差σ=√s / n的截断正态分布来对权重矩阵进行初始化,其中s是放缩超参,n是权重向量输入的数量。这里作为减小路由数量不稳定性的一个补救,作者把transformer默认的初始化s从1.0缩小10倍。他们发现这样的话既可以提高质量,又可以减少实验中训练不稳定的可能性
下面的表三测量了训练初期,模型质量的改善还有方差的降低。作者发现,用这个negative log perp度量的平均模型质量得到了一个比较大的改善,而且运行多次的方差也减少了很多,从0.68到0.01。他们使用这个方法,把200多兆参数量的baseline稳定地训练成了超过一万亿个参数的超大模型
Regularizing large sparse models
因为这篇论文是在一个大的语料库上做预训练,然后在比较小的下游任务做微调,一个比较自然的问题就是过拟合问题,因为许多微调任务中比较缺乏数据。Switch Transformer比一些dense model的参数要多很多,这样可能会导致在这种比较小的下游任务上更容易过拟合
之前有一些工作使用dropout来防止过拟合。这篇文章是提出了一种比较简单的在微调时候减轻过拟合问题的方法,就是增加expert内部的dropout,他们叫expert dropout。在微调的时候,只在每个expert层的过渡的feed-forward层计算的时候大幅增加dropout的概率
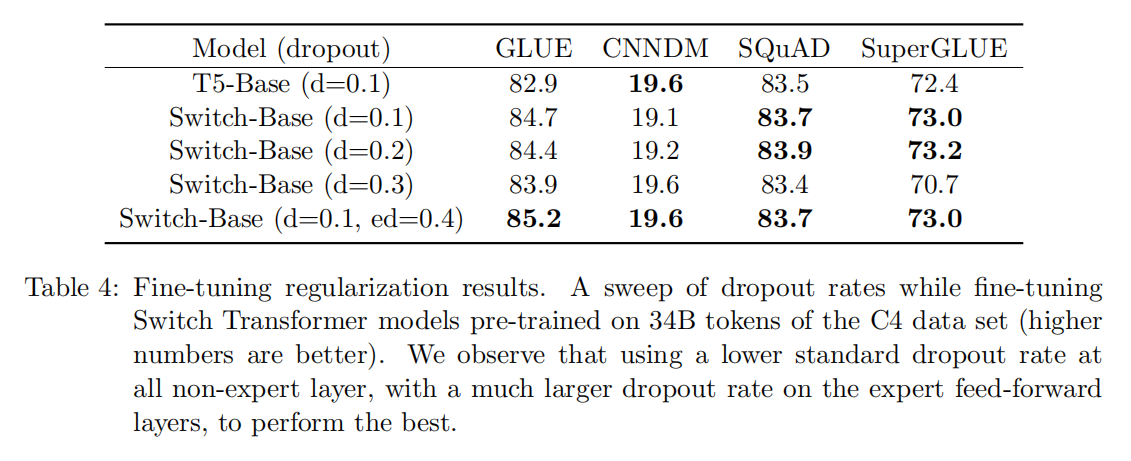
下面的表四做了这部分的实验,我们可以发现,只是简单对所有层都增加dropout之后,会得到一个比较差的结果,当给非expert层设置一个比较小的dropout,也就是0.1,给expert层设置一个比较大的dropout rate会在四个下游任务上得到一定性能的提升
Downstream Results
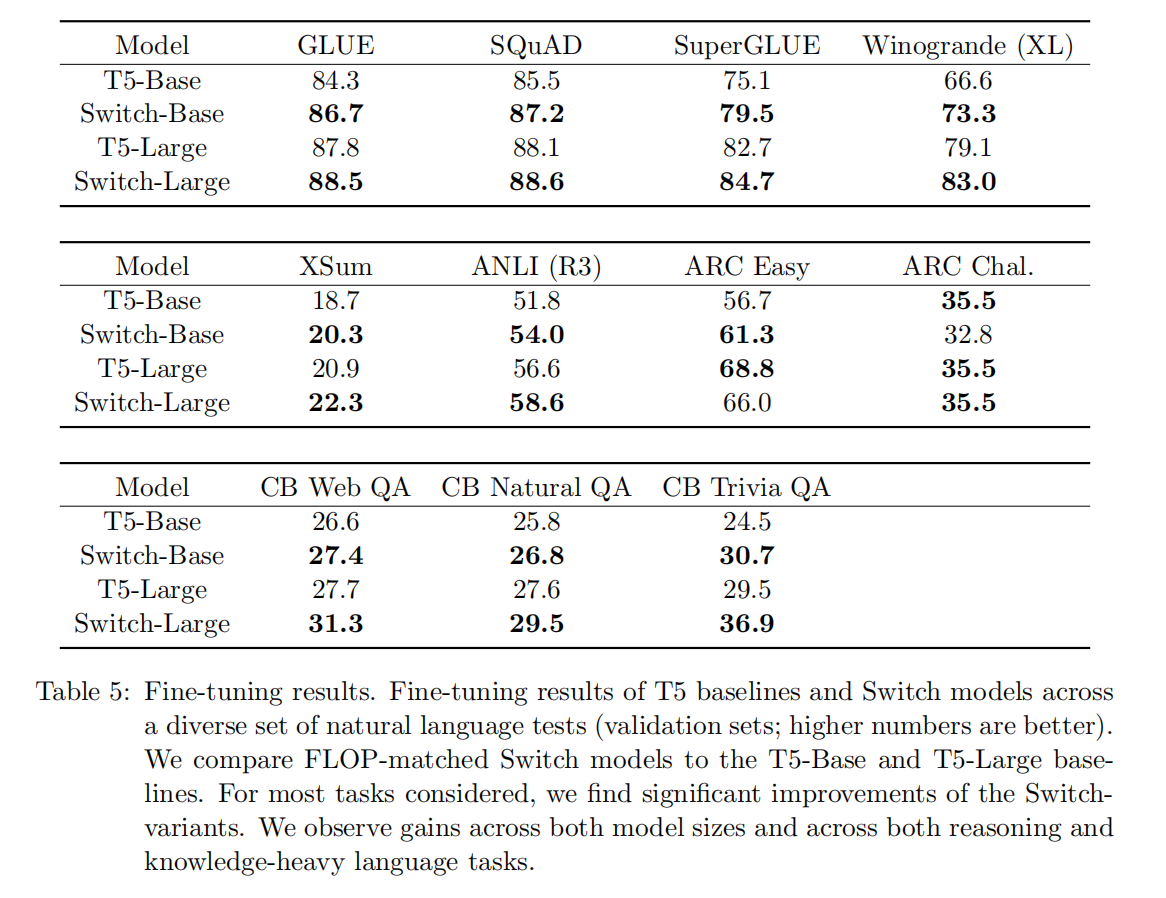
下游任务上,团队选取了包括GLUE、SuperGLUE、翻译、文本摘要在内的多个任务的数据集,Fine-tuning表现如下
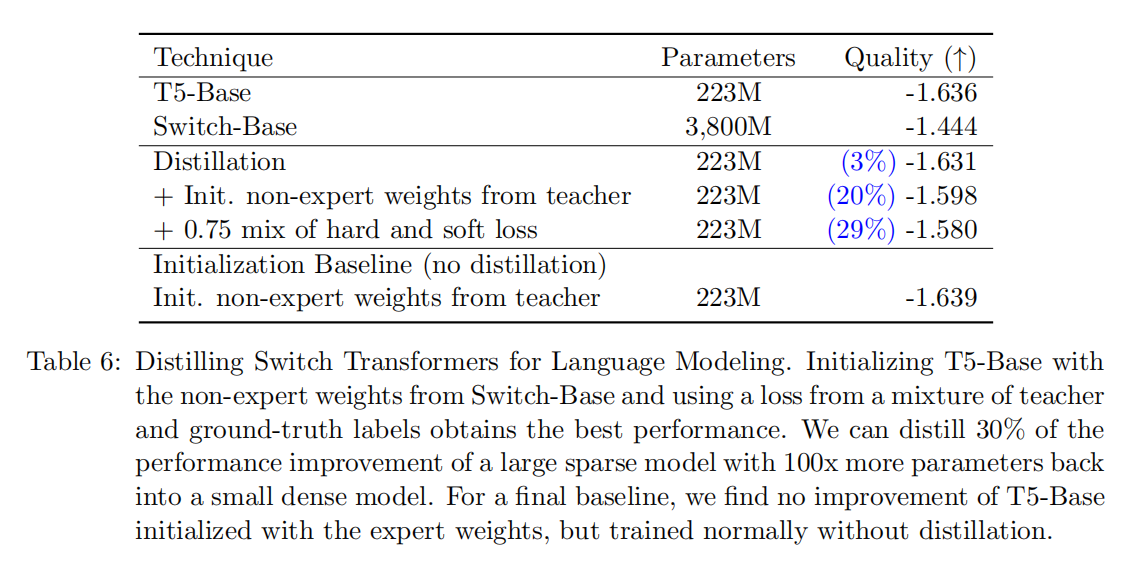
做知识蒸馏的表现如下
Designing Models with Data, Model, and Expert-Parallelism
标准的数据并行的定义是一个batch的数据在不同的device上并行处理,这时每一个device上都保存了模型的一份完整拷贝,前向计算完进行梯度汇总和更新。模型并行表示模型不同的参数(层、组件)分配到不同的device上,处理一个batch的数据
本文中下图中上面一行整体表示权重的分配方式,下面一行表示数据的分配方式,一种颜色表示一个矩阵(a unique weight matrix)。其中每一个方格表示一个core。
数据并行:
第一列表示数据并行,模型权重拷贝16份,16个同一种颜色矩阵分别表示一个完整的模型,数据侧则是一个完整的矩阵,这里可以理解为16个模型计算完成后由于存在梯度汇总再更新的步骤,所以整体更新的是一个batch,因此这里数据侧是一个唯一的矩阵

模型并行:
模型并行部分从模型侧看出来,16个cores维护的是一个整体的模型,但是每一个core只分配到其中非常高通信代价,同一个batch在所有的core上计算,由于1个core中分布了不同的模型权重,每次计算完都需要和其他的core进行通信
专家并行:
原本路由机制只会分配给当前core中的不同的expert,现在则有可能会分配到其他的core下的expert,范围更大
Discusstion
Q1: Switch Transformer效果更好,是否是因为更大的参数量?
A1: 是的,并且是设计成这样的。大型模型已被广泛显示出具有更好的性能 [1]。我们的模型在使用相同的计算资源的情况下,效率更高,速度更快。
Q2: 我没有supercomputer, 这篇工作对我还有用吗?
A2: 尽管这项工作集中在非常大的模型上。但是只有两个exports就能够提升性能,并且可轻松地适用常用的GPU或TPU的内存限制。因此,这项技术在小规模环境中仍然有用。
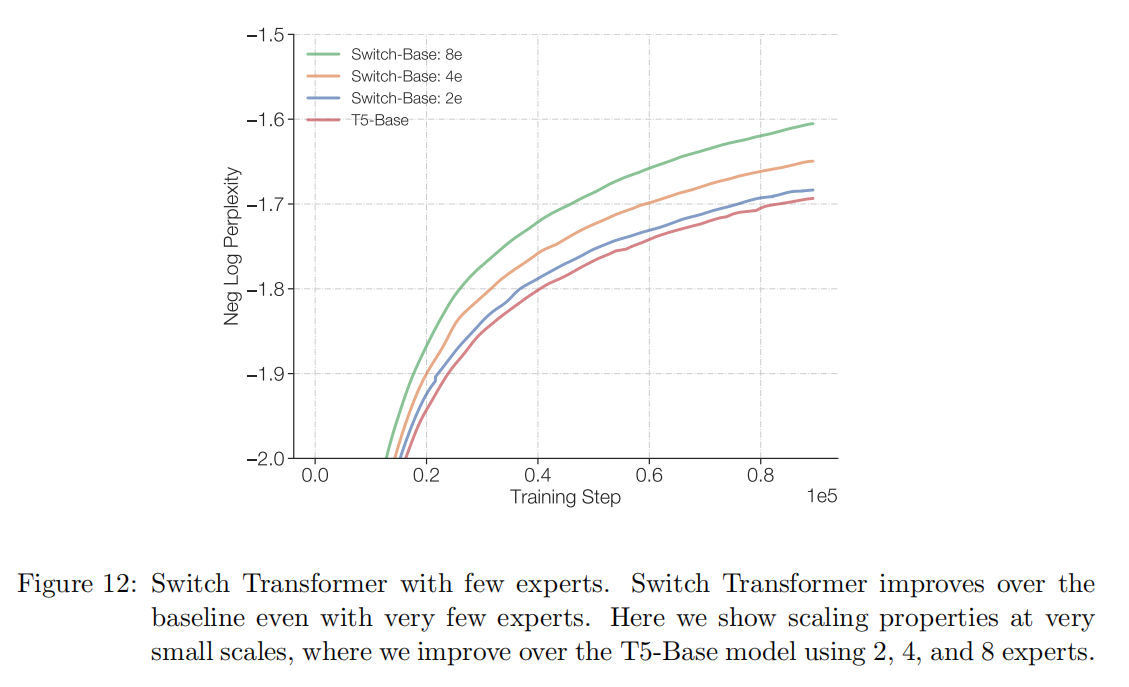
Q3: Sparse Model是否在pareto曲线上优于Dense Model?
A3: 是的。实验表明,在固定的计算量和时间上,Sparse Model的性能都优于Dense Model。
Q4: 我无法部署一个万亿参数的模型,能够缩小使用这些模型吗?
A4: 无法保证缩小后的模型的质量。但是以10到100倍的压缩率将Sparse Model蒸馏为Dense Model,可以获得Export Model 30%的质量增益。
Q5: 为什么使用Switch Transformer来代替模型并行方式的Dense Model?
A5: 从时间的角度看,Switch Transformer要比Dense Model高效得多。另外,这两者并不冲突,可以在Switch Transformer中使用模型并行来增加每个token的Flops,但这会导致传统模型并行性的降低。
Q6: 为什么Sparse Model尚未广泛使用?
A6: 尝试Sparse Model的动机受到了Dense Model的巨大成功的阻碍(其成功是由与深度学习硬件的共同适应驱动的 )。此外,Sparse Model存在以下几方面的阻碍:(1)模型复杂性;(2)训练困难;(3)通信成本。Switch Transformer在缓解这些问题上取得了巨大进步。

