论文地址:Unified Language Model Pre-training for Natural Language Understanding and Generation
UNILM:三种预训练任务的统一语言模型
Abstract
本文提出了一个新的预训练模型UNILM可以做语言理解和生成任务,使用三种语言模型任务建模:单项的语言模型、双向的语言模型,序列生成任务。通过共享transformer 网络和自注意力掩码实现控制上下文的条件
Introduction

不同的训练任务和目标对应不同的预训练语言模型

UNILM是一个多层的transformer网络,应用大量的语料联合优化三种类型的无监督语言模型
三个好处:
- 因为不同类型的语言模型采用共享的参数和结构,所以UNLM预训练过程是一个单个的transformer 语言模型,避免了多个语言模型训练过程的分离
- 参数共享使得学习的文本表示更加通用,因为它们是针对不同的语言建模目标联合优化的,以不同的方式使用上下文,从而减少了对任何单个LM任务的过拟合
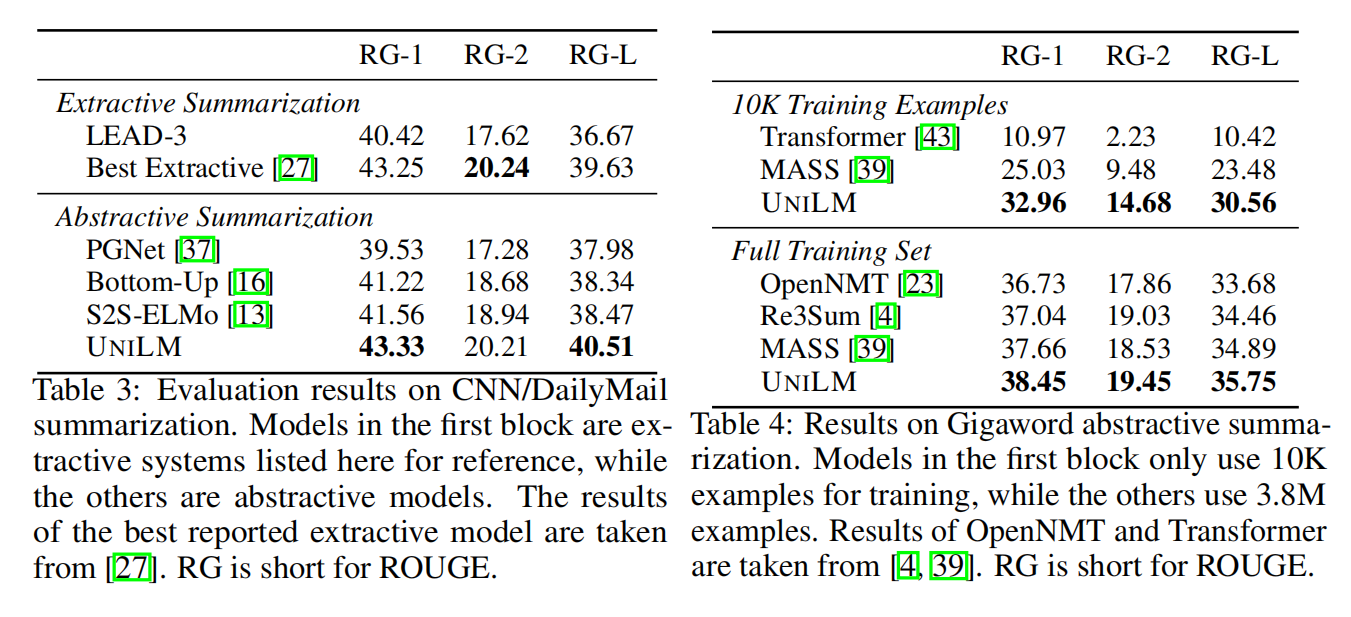
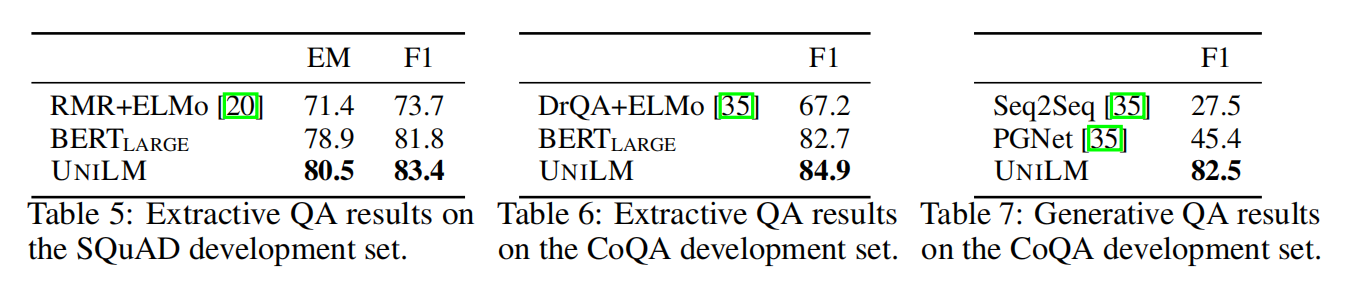
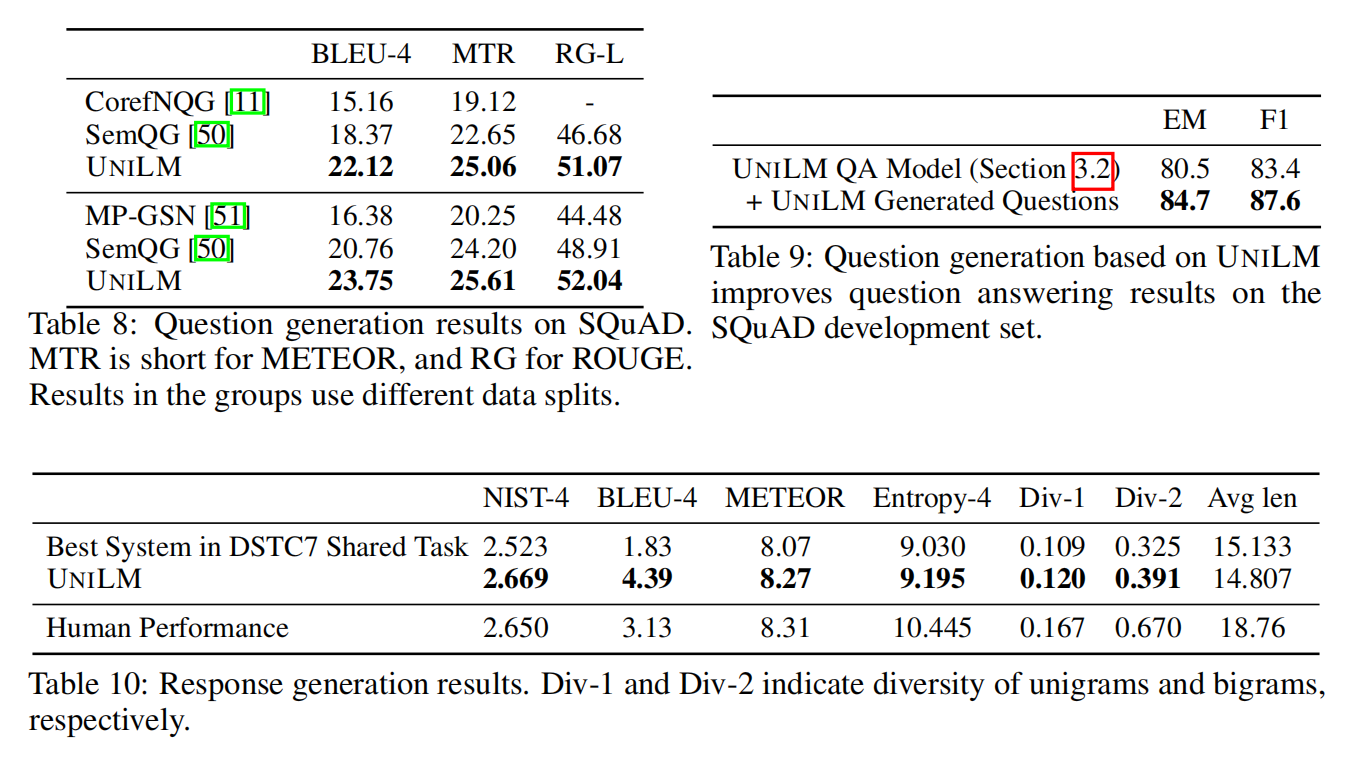
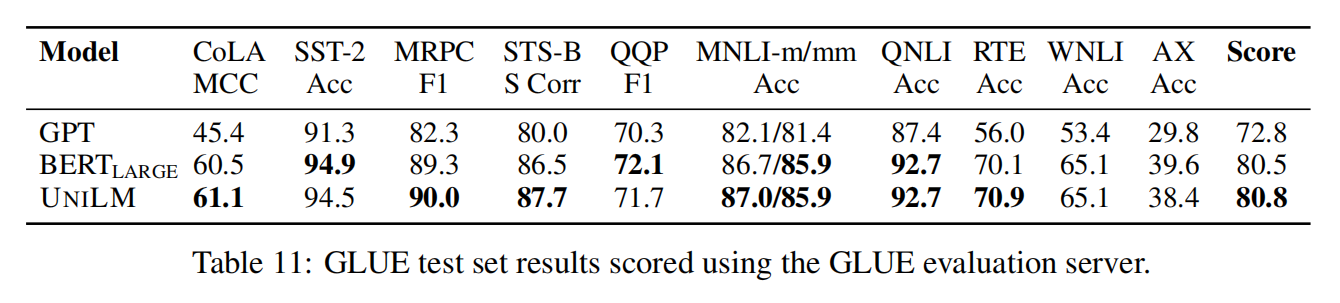
- 除了应用于NLU任务,UNILM可以作为seq-to-seq LM模型,也可以应用于NLG任务,例如摘要生成,问题生成
Unified Language Model Pre-training
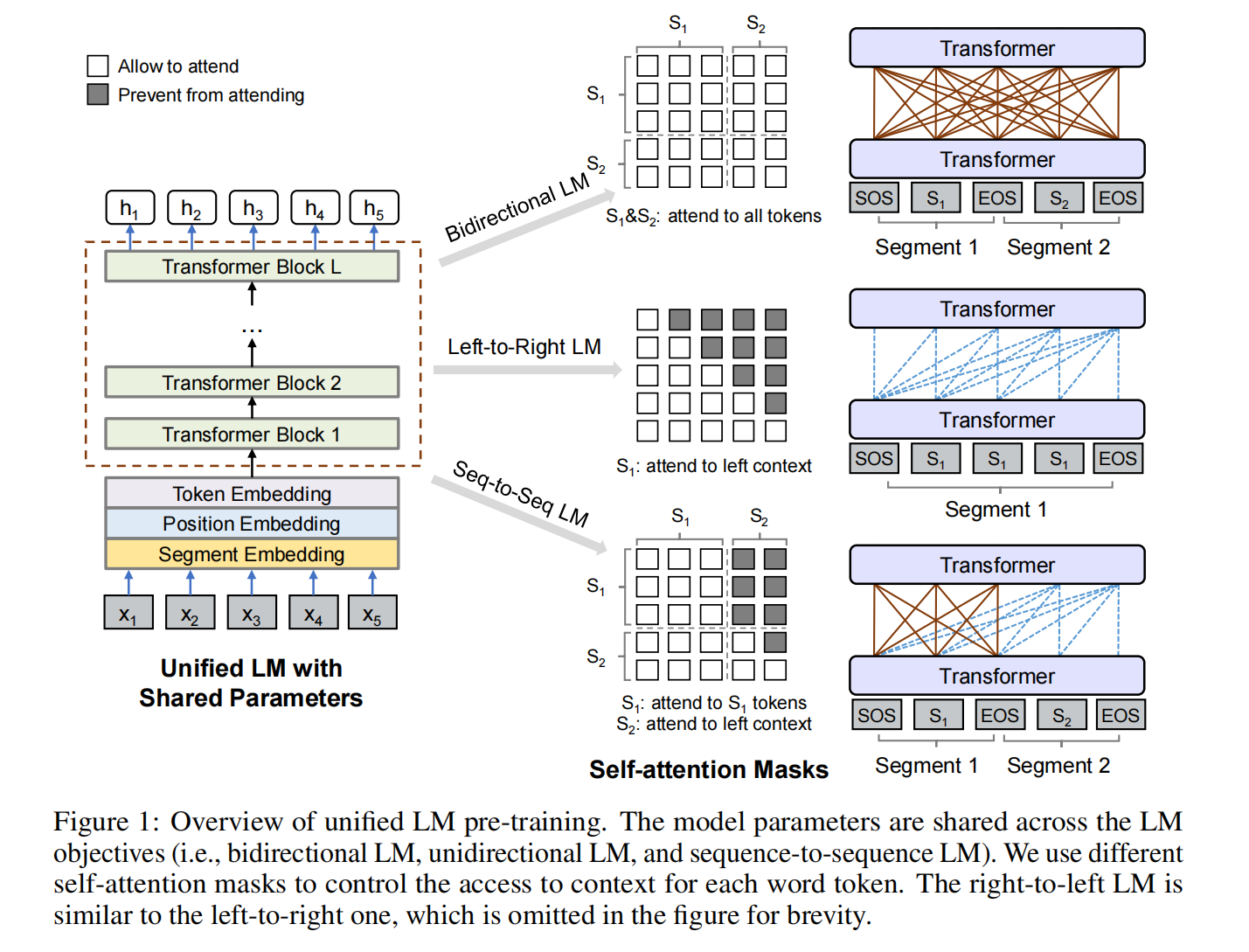
Backbone Network: Multi-Layer Transformer
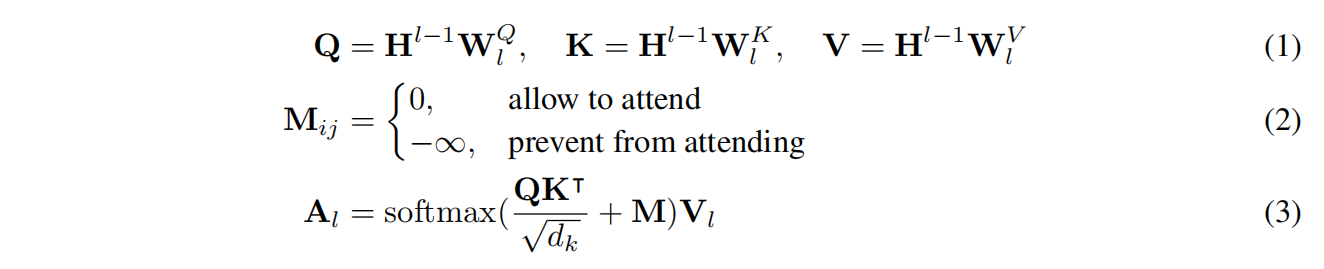
先前transformer network的输出,通过不同的W参数被映射为queries、keys和values向量,另外,mask matrix M决定了token能否互相关注
Pre-training Objectives
Unidirectional LM、Bidirectional LM、Sequence-to-Sequence LM,对Bidirectional LM还设计了Next Sentence Prediction
Pre-training Setup
训练目标为三种不同的LM目标的综合。尤其,训练过程中每个batch,1/3的时间训练双向的LM,1/3的时间训练seq-to-seqLM,left-to-right and right-to-left LM各1/6的采样速率
模型使用24层的Transformer结构,隐层维度:1024,注意力头:16,包含340M的参数,词表28996,最大输入序列长度512,mask概率15%(这和BERT一样)
Adam优化器 $\beta_1=0.9,\beta_2=0.999$,学习率3e-5,linear warmup前40000个step,dropout=0.1,weight_decay=0.01,batch_size=330,770000steps,10000个steps在8张V100训练7小时
Experiment