论文地址:Supervised Contrastive Learning for Pre-trained Language Model Fine-tuning
SCL:有监督对比交叉熵
Abstract
受到好的泛化性需要捕捉一类样本里的相似性和区别其他类样本的直觉启发,提出了在微调阶段的有监督对比学习(SCL)目标。与交叉熵相比,提出的SCL可以有效提高RoBERTa-Large在GLUE基准few-shot上的分数,不需要特殊的架构,数据增强,memory banks或额外的无监督数据。对不同级别的噪声具有更强的鲁棒性,能够更好泛化在有限制的标注的相关任务上
Introduction
交叉熵的泛化性能很差,缺乏对噪声标签或对抗样本的鲁棒性
在NLP中使用交叉熵微调在不同的运行情况下也趋于不稳定,特别是在有监督数据有限的情况下。实验表明微调的时候使用更多的iteration,重新初始化顶端的一些层可以使微调阶段更稳定
作者假设基于相似性的loss能够深入多维度的隐空间表征里重要的维度,这样能够得到更好的在few-shot学习结果,从而在微调的时候更加稳定
是用在有监督训练最后的任务中,不是对比样本的不同增强视角
主要贡献:
- 提出了一个新的语言模型微调目标
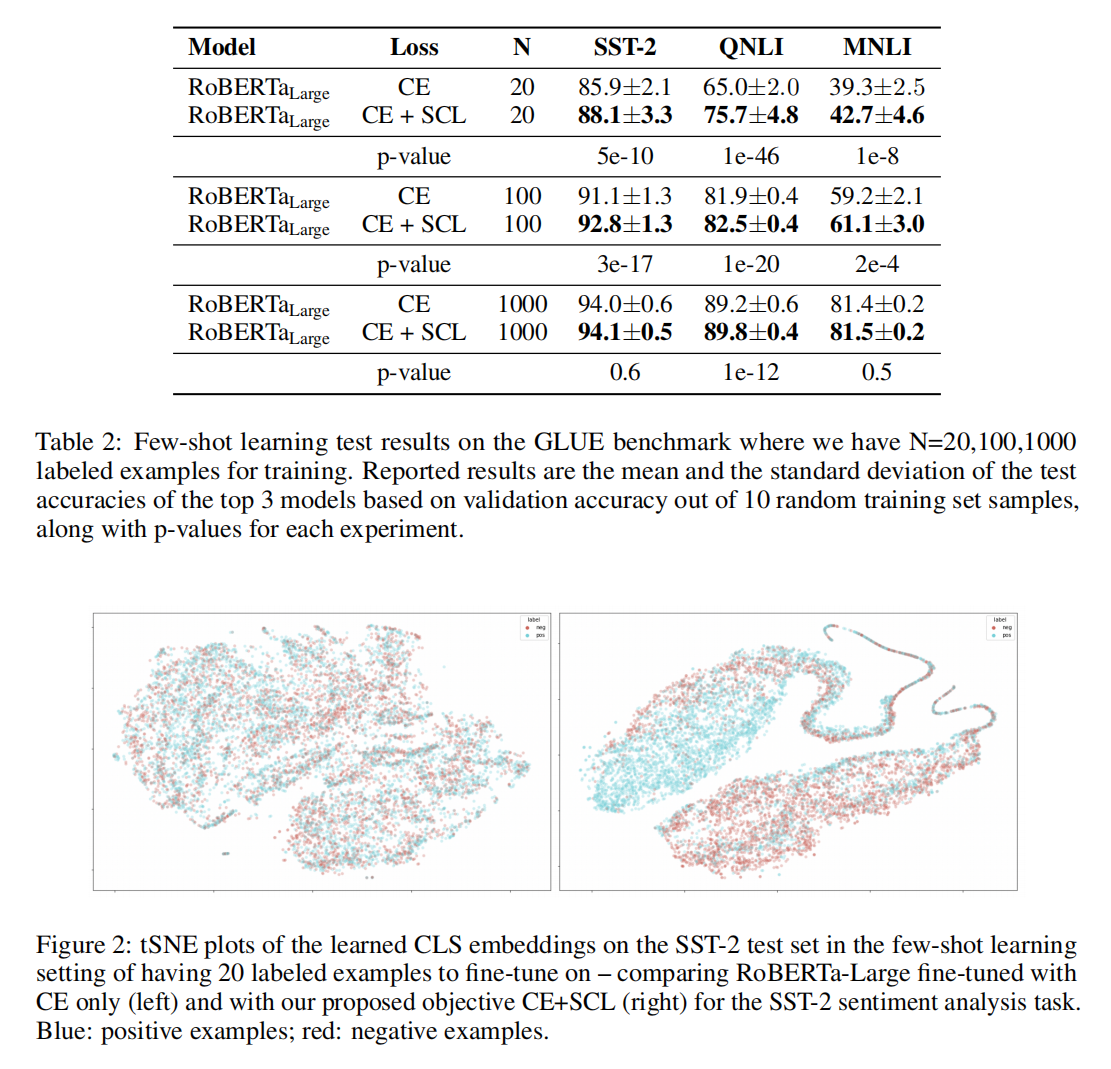
- 在few-shot设置(20,100,1000)有10.7个点提升,表2
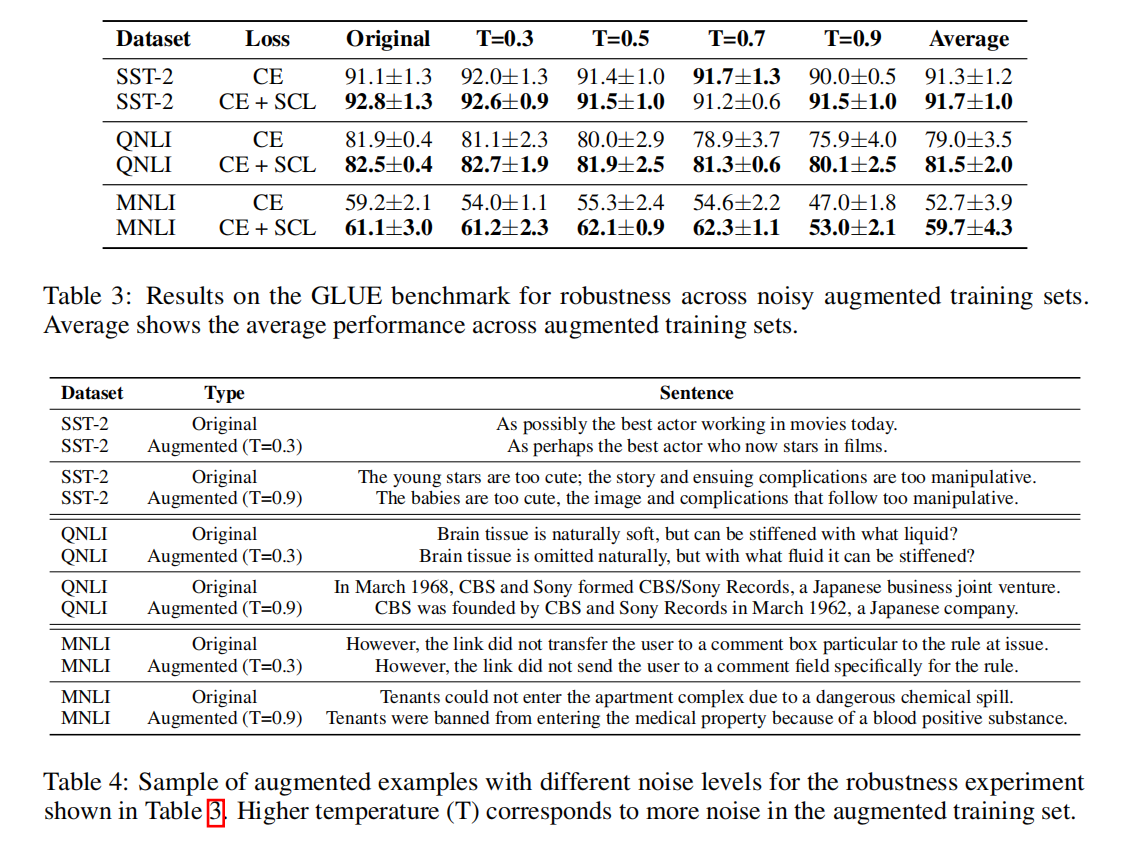
- 展示了这个微调目标非常鲁棒,在部分GLUE基准上有7个点提升,表3
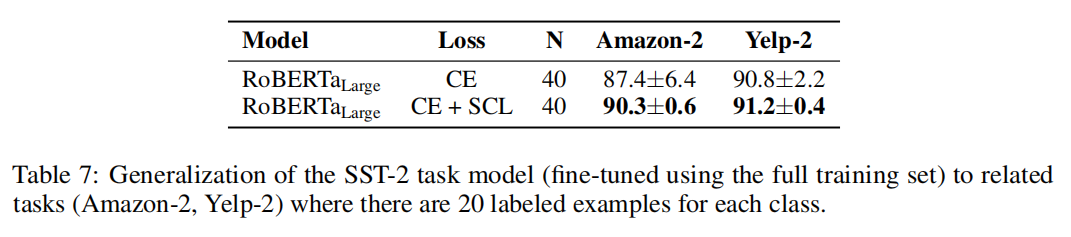
- 在有标注数据非常有限的任务上泛化性也有提升,表7
Approach
这个loss是捕获同类别的样本相似性以及在不同类别的样本做对比
多分类问题有C个类别;一个batch的训练样本是N,${x_i,y_i}{i=1,…,N}$;$\Phi(·)\in R^d$ 表示编码器;$N{y_i}$ 是一个Batch里标签都是 $y_i$ 的样本数;$\tau >0$ 是可调节的标量temperature参数控制类的分离;$y_{i,c}$ 是标签,$\hat{y}_{i,c}$ 是模型输出属于第c类的概率;$\lambda$ 是标量权重超参,对每个下游任务和设置进行调整。整个loss如下
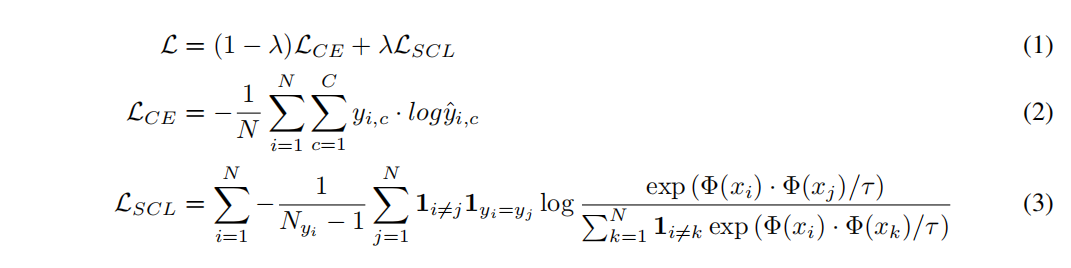
把交叉熵的Loss叠加上对比学习的loss,这里叠加的对比学习loss是info NCE loss
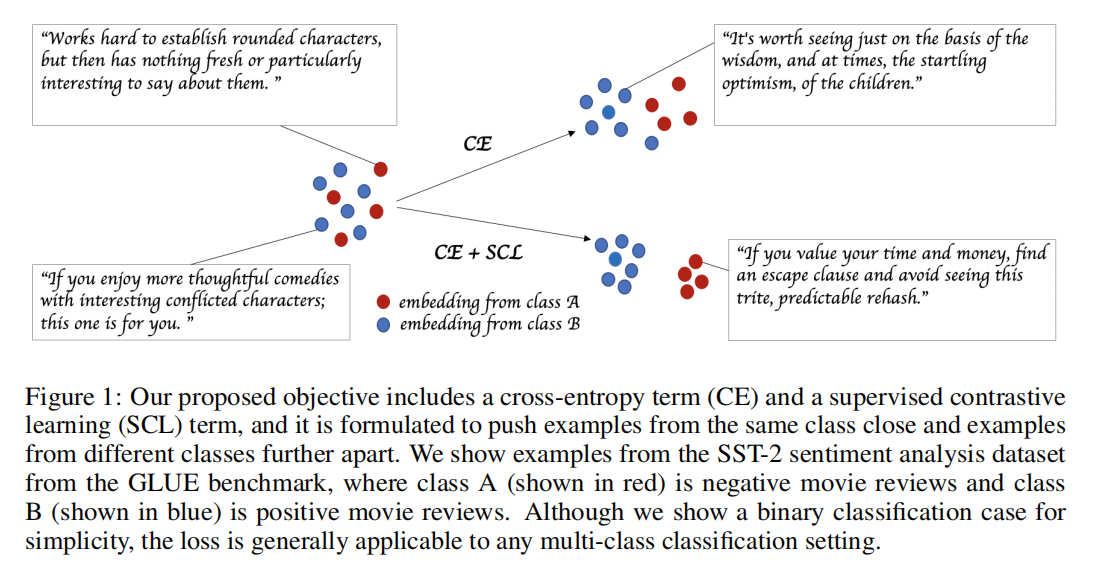
embedding表征通过L2正则化和标量温度参数 $\tau$ 可以提高性能,较低的温度增加了更难分离的例子的影响,产生了更难的负样例
Relationship to Self-Supervised Contrastive Learning
一个Batch大小为N,自监督对比学习的loss如下
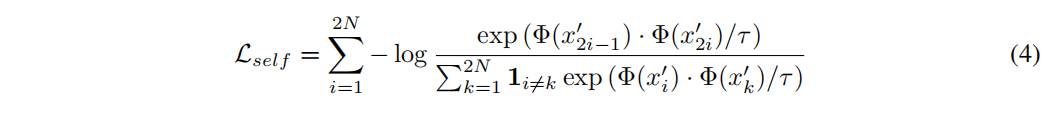
分子 $x’{2_i-1}$ 和 $x’{2_i}$ 的来源于原始样本 $x_i$
Experiment
GLUE Benchmark Few-shot Learning Results

Robustness Across Augmented Noisy Training Datasets
GLUE Benchmark Full Dataset Results
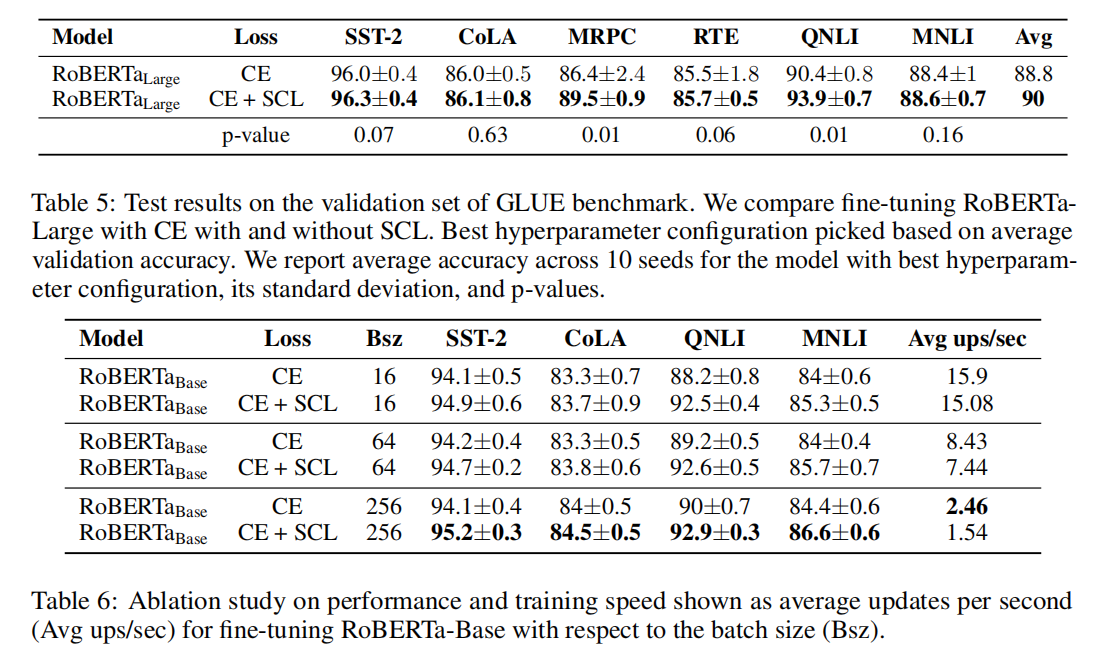
Generalization Ability of Task Models