论文地址:Robust Speech Recognition via Large-Scale Weak Supervision
Whispser:tansformer用大量数据做语音识别
Abstract
研究了网络上收集的语音脚本用来大规模训练的效果,把数据扩展到68万个小时用多语言和多任务有监督训练效果会非常好,在标准测试上跟其他场景的做zero-shot能达到最佳
Introduction
最近的方法是用无监督的预训练,这里是有很多时序信息可以做任务的,这样的好处是:
- 数据采集容易,不需要标号和清理
- 能找到大量的没有版权问题的数据
这样可以得到一个非常好的编码器,但是没有一个好的解码器,需要有监督的数据来进行微调,这是一件比较麻烦的事情,如果不用微调就更好了。先前的预训练在语音识别预测出来的是一个声波,而声波到文字还需要一个格式转换,所以无论怎么样都需要一个微调
微调还有一个问题是容易在训练的数据上过拟合,这样泛化性不见得好。无监督方法最大的问题就是有一个好的编码器,但没有好的解码器,一个好的语音系统应该是一个“out of the box”的工作
有监督学习在多个数据集上学习都比单个数据集要好,但是7个有监督数据合在一起也就5000个小时,跟无监督的100万个小时差距很大。放松一下标号的要求能达到更多的数据集
在youtube上爬了一万个小时数据集,把视频和字幕抓出来做标号,在这种数量跟质量上做权衡是不错的想法
把弱监督数据集拓展到了68万小时,这个方法叫whisper,不仅大多样性也有改进,11万小时覆盖了96种语言,12万小时是讲的是某种语言但标号是英语的翻译。当模型足够大的时候做多语言多任务训练是有好处的
Approach
Data Processing
跟之前的语音系统不一样的是,本文模型预测的是原始文本,没有做标准化,直接还原出来,不需要做反向的文本规划的过程(单词变小写,去掉标点,展开缩写等),只要数据够大就不用做这些操作,所有情况在数据里都可以出现
从互联网下下来的数据有非常多样化的环境,录制,麦克风还有不同语言等等(音频质量的多样性)
但是文本质量的多样性就不好了,设置了一个自动过滤去来筛选掉低质量文本。文本可能是现有的系统识别得到的结果,如果混着人标注和系统识别的性能就比较差,基本是基于规则的简单方法
先把声音的语言检测出来,再用CLD2把文本语言检测出来,如果不对应的话就删掉了,但如果文本是英语就留下来,因为还有个翻译的任务;然后就是还有一些去重,文本相似度过高就删掉
把音频分为30秒区间,文字对应起来就是训练样本;如果没人说话也放进去做一些下采样,能区分有没有人在说话。还有就是检查了一下错误率很高的原数据,一般是转录了一半,音频和文字没有对齐的,就删了
最后就是把训练集里的测试样本删掉,避免泄露
Model
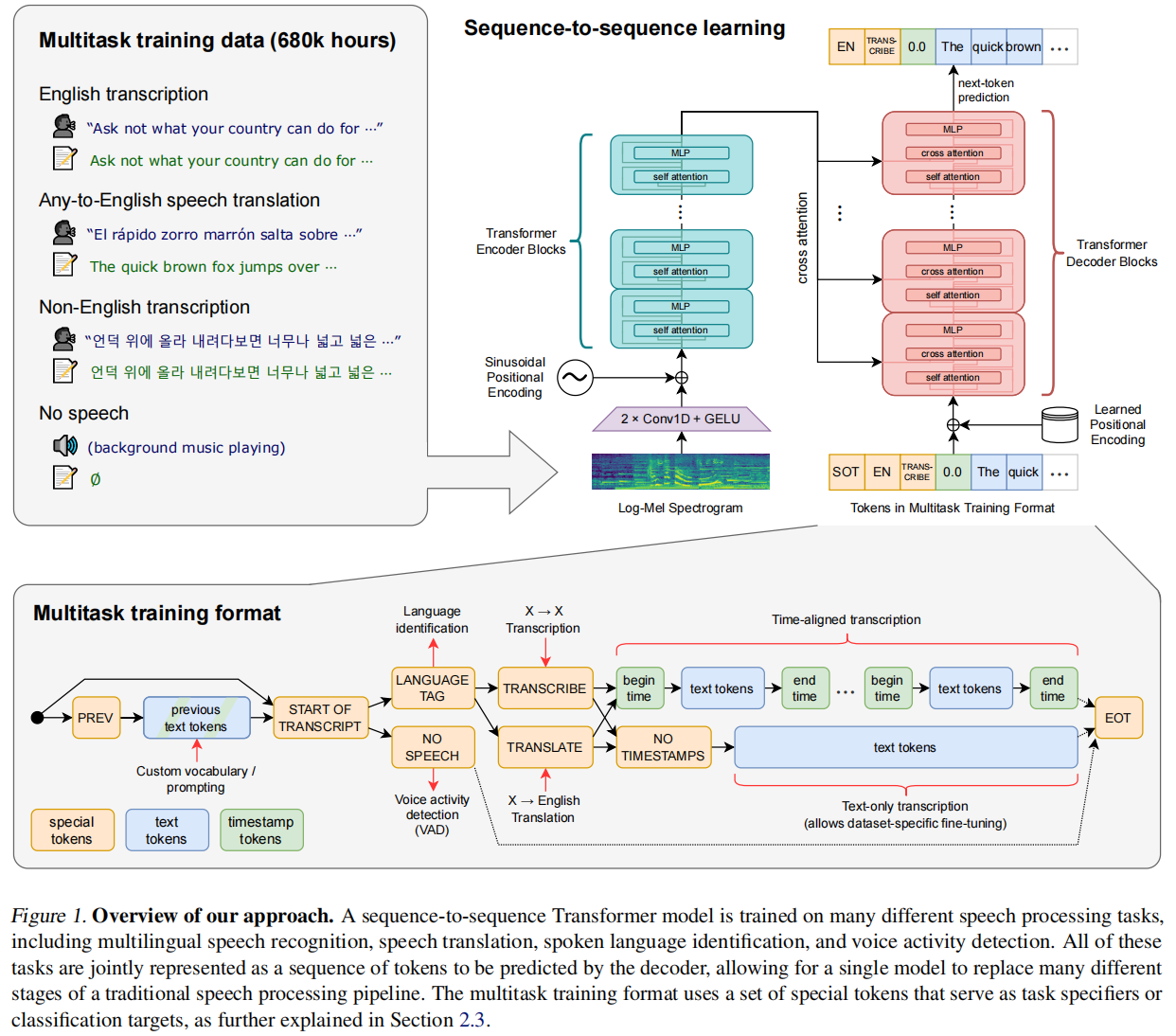
用的是完整的编码器-解码器的transformer,用的byte-level BPE tokenizer
Multitask Format
虽然语音系统的核心是给一个片段把文字识别出来,但还有一些任务比如检测是否有人说话,谁在说话等。通常是一个模型做一个事情,然后把模型串成一个系统,但作者希望一个模型能统一所有任务,能对一个语音做转录,翻译,检测…
多任务在图1左侧,图1下面这个图使用了prompt,不同的任务通过不同的token组合来确定的,有一定概率是给前面的文本,也有一定概率是直接开始转录,然后有一定概率是做语言任务,这里又有两步,一个是同语言转录,一个是翻译;后面也有两个走向,有时间戳和没有时间戳。还有一定概率走的是没有人说话,做VAD
这里不需要像BERT一样每个任务设置一个输出层,设计对应的损失函数,这里就是简单的输出下一个词,输出和损失都是一个东西;但是其中一个任务不好的时候很难做微调
Training Details
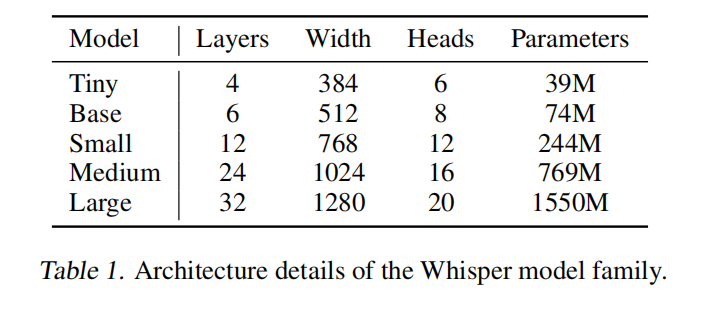
用的FP16,动态调整损失,训练了2-3个epoch不会overfitting
Experiments
Zero-shot Evaluation
在语音识别数据集评估性能,但不用这些数据集的训练集训练
Evaluation Metrics
WER
直接做WER会有点亏,因为比如输出是大写,标答是小写,这样还是会算一次错误,所以做了一次文本标准化为了刷榜,实际应用时不用
English Speech Recognition
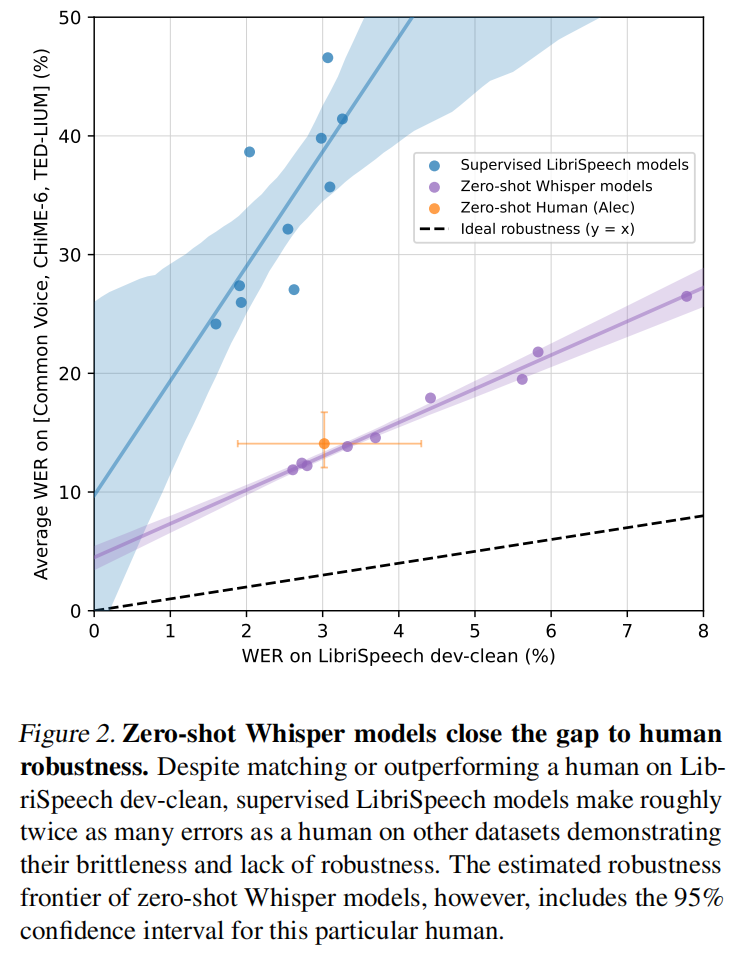
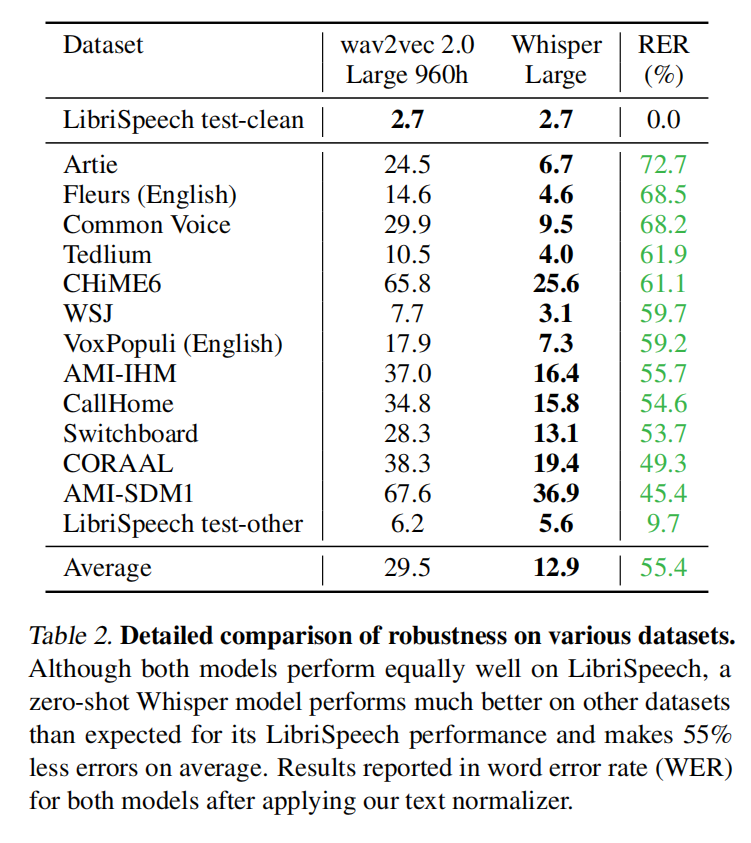
人类的错误率在5.8%,在干净的LibriSpeech刷榜已经到了1.4%到底有没有用。从图2来看有监督模型换个数据集表现就很差了,但whisper的泛化能力比较好,黄色点是人类错误率
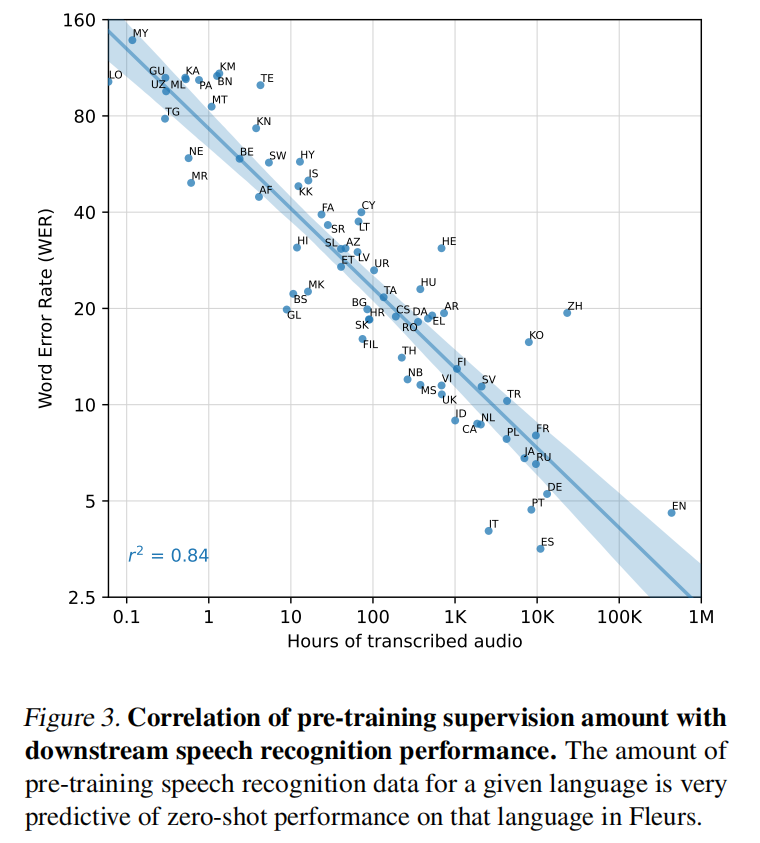
数据成倍增长的时候错误率也在成比例往下降
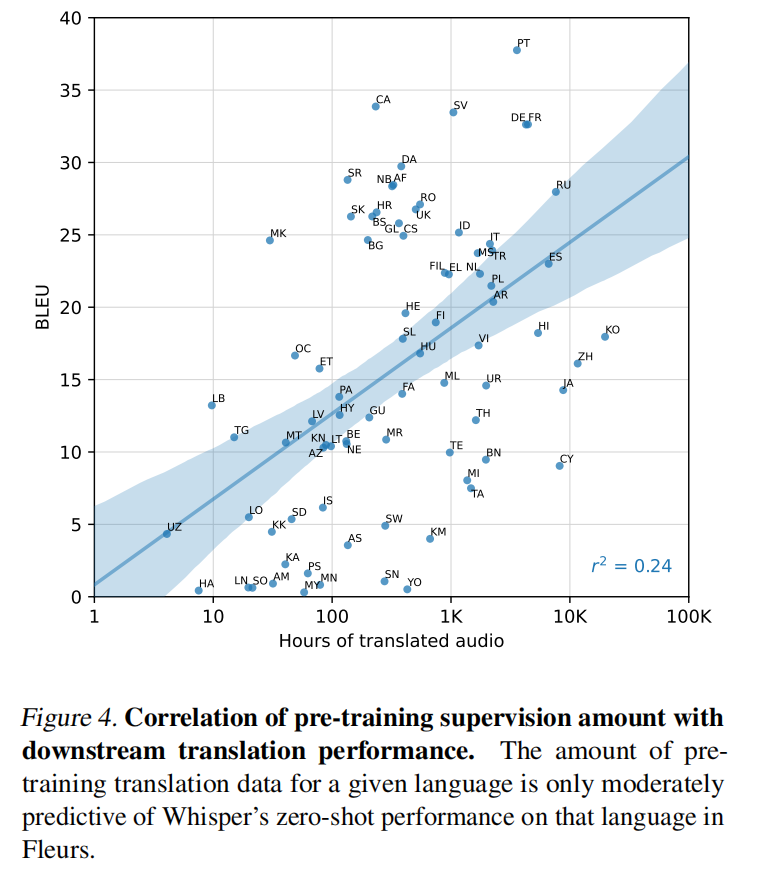
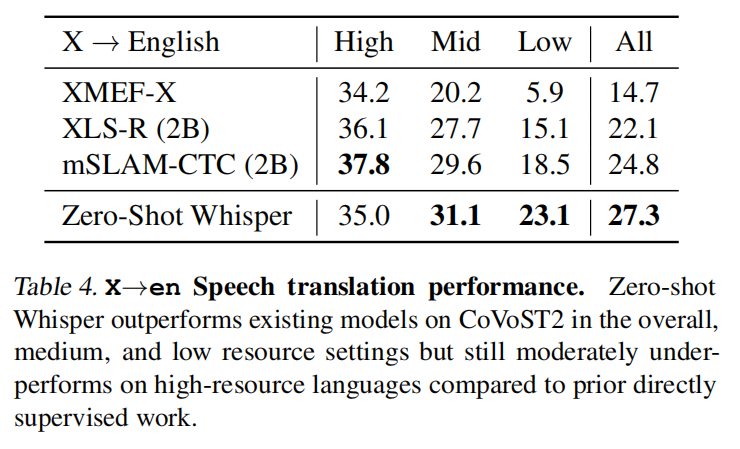
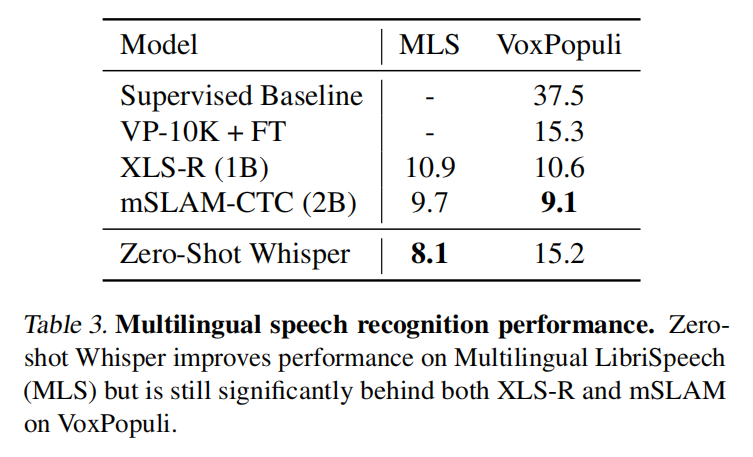
翻译的效果
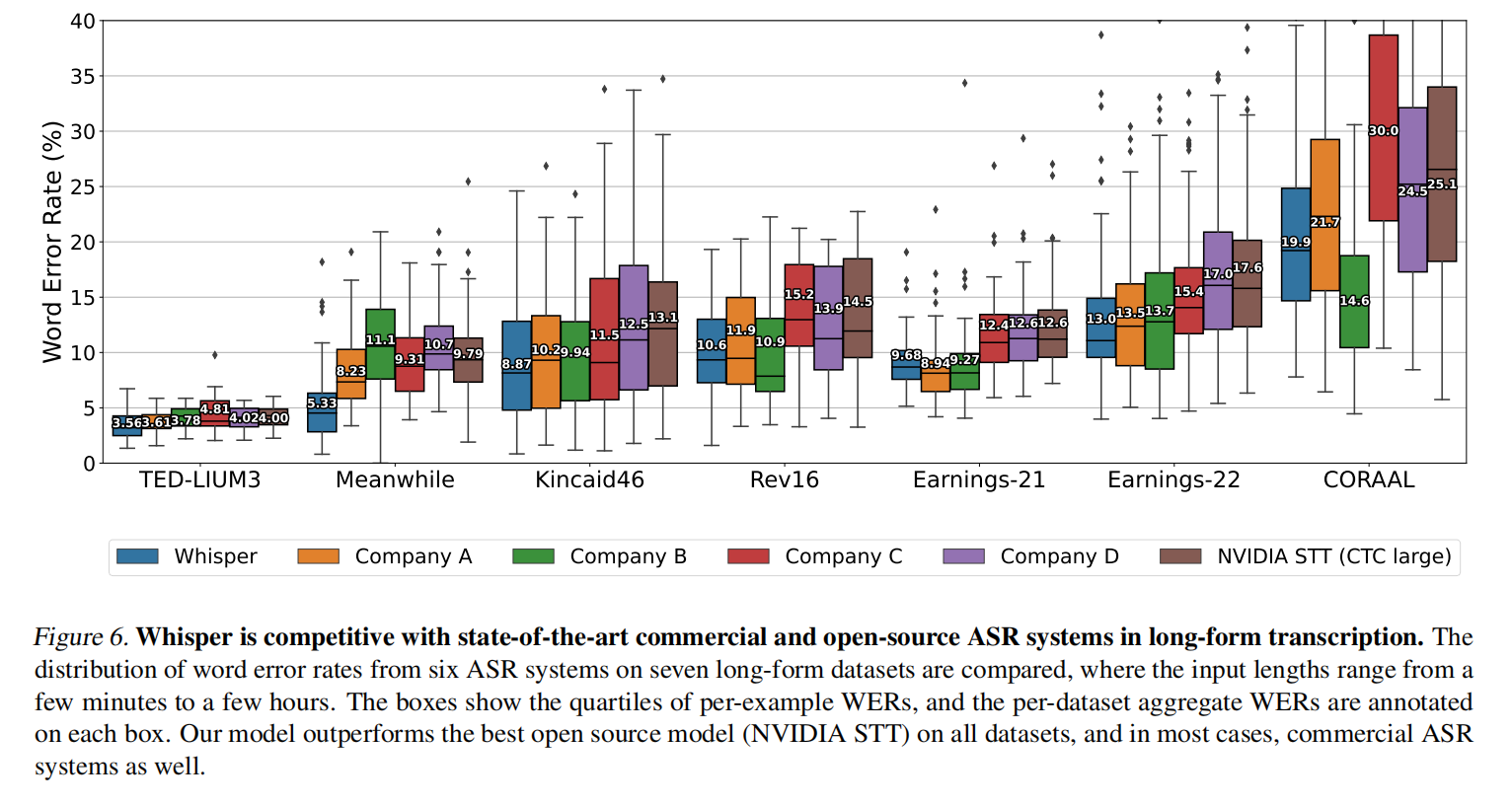
长的转录上面的对比,效果基本和商业的打平
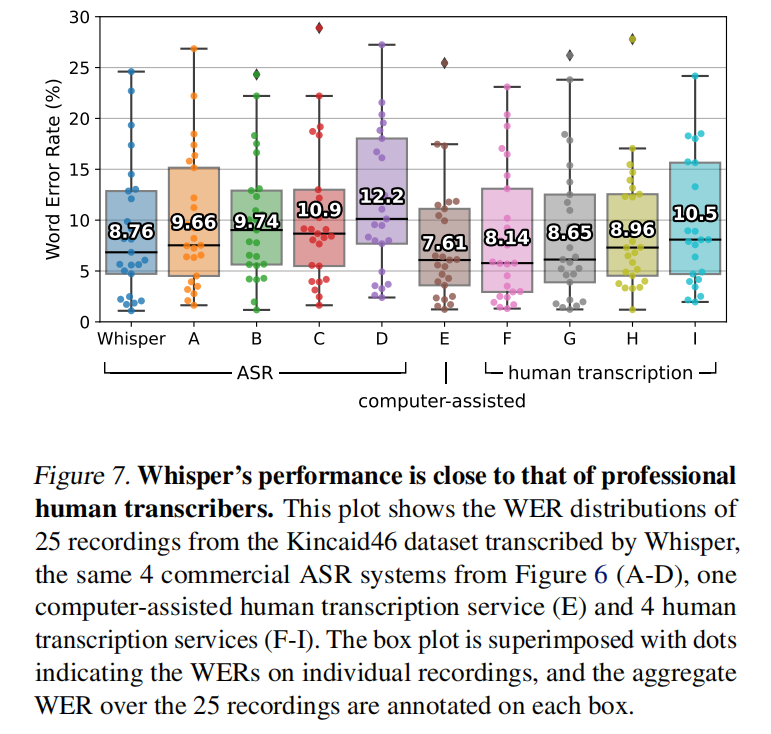
和专业的人的转录效果差不多
Analysis and Ablations
Model Scaling
弱标注可以用大数据集,但如果模型够大的话会记住数据里的噪声
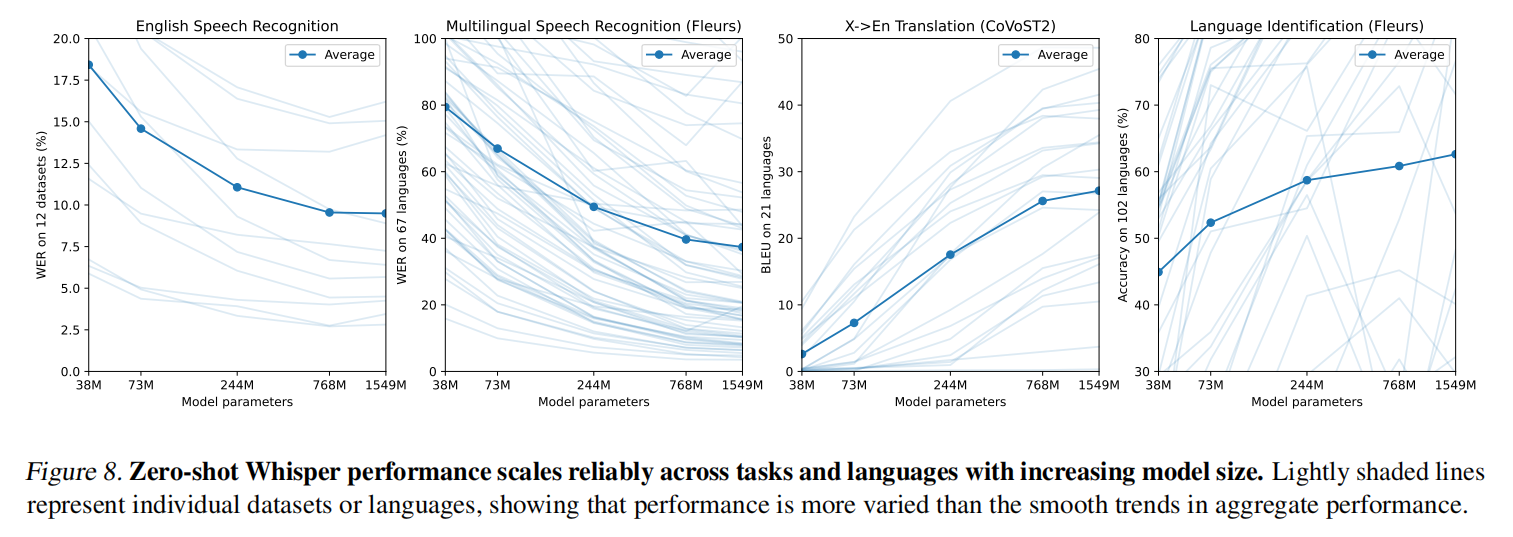
随参数增加整体效果还是在变好的,虽然有些误差在上升,但是在7亿的时候基本已经卡住了
Dataset Scaling
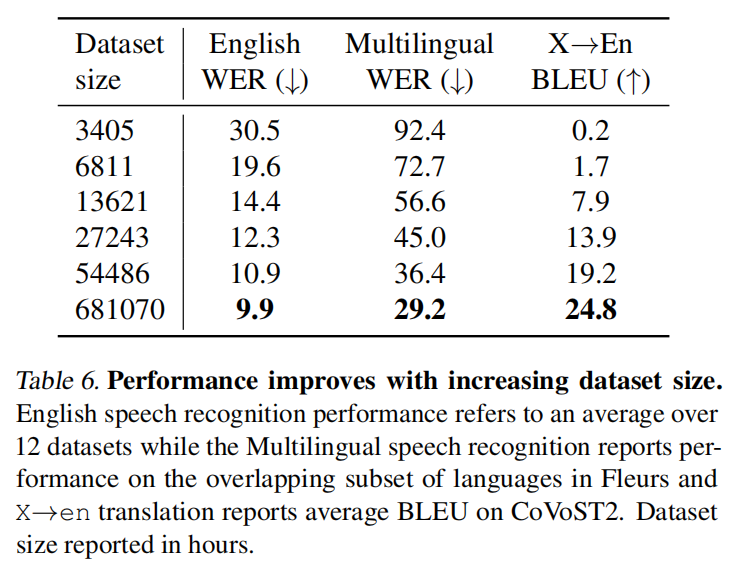
当数据集增加的时候,英语在五万基本饱和了,其他还是有不错的提升
Multitask and Multilingual Transfer
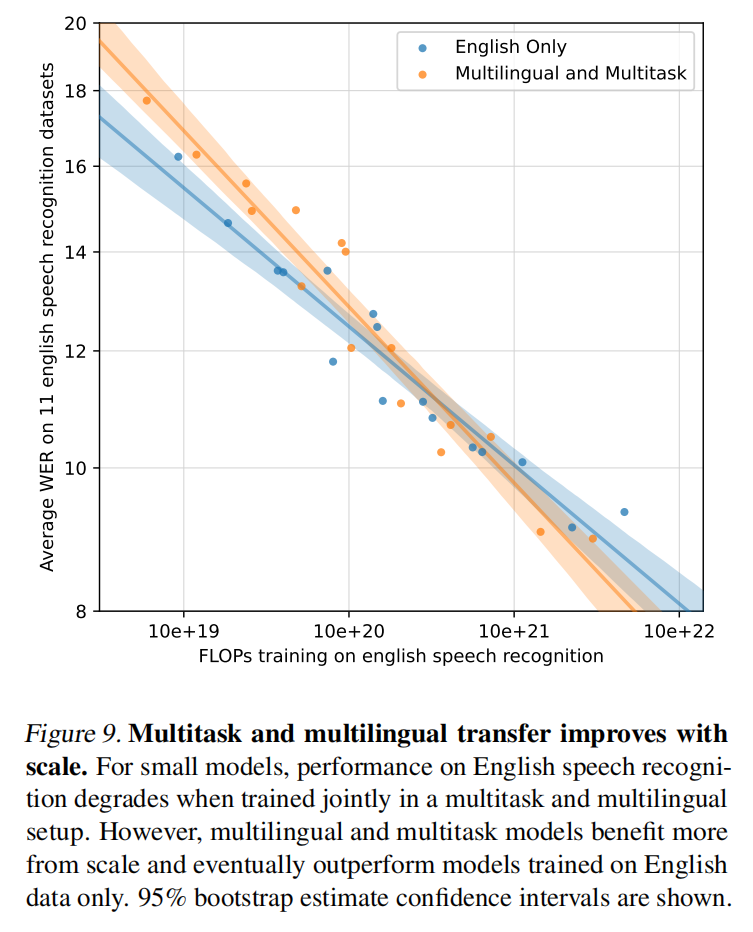
训练时间够长的时候多语言多任务会更好一点
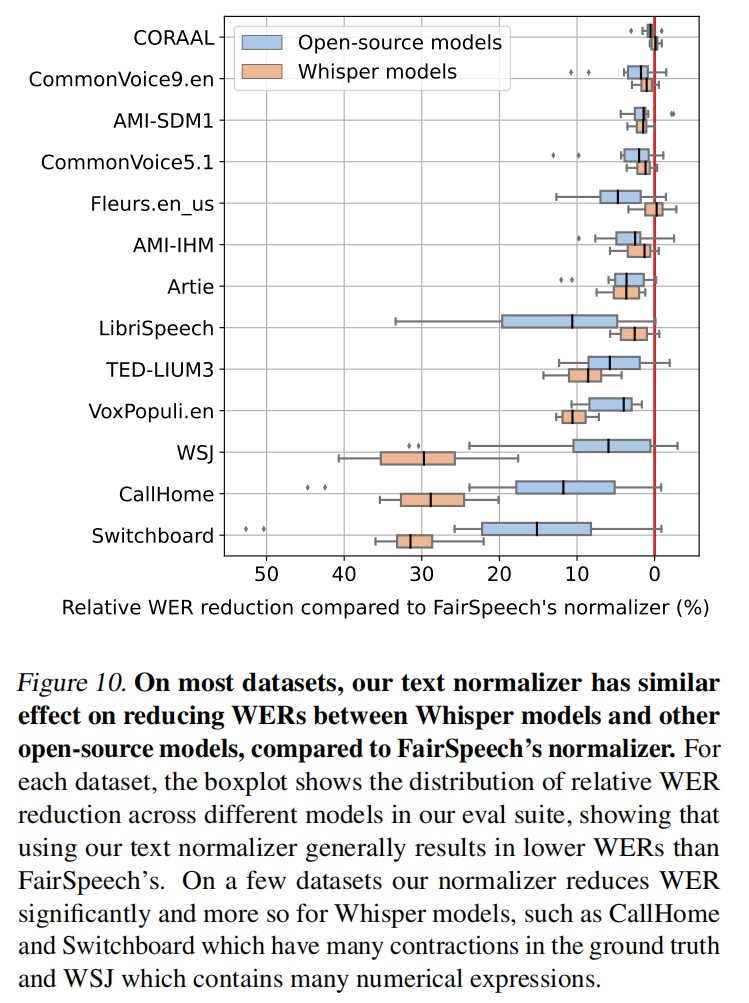
Text Normalization
Limitations and Future Work
Improved decoding strategies
模型变大的时候对词的选择会好一点
Increase Training Data For Lower-Resource Languages
有些语种数据少
Tuning Architecture, Regularization, and Augmentation
调整架构,加归一化或数据增强等
Adding Auxiliary Training Object
加一点辅助的目标函数
Conclusion
目前对用弱监督训练的认识还不够,但只要数据集够大效果是非常好的,预训练好后可以直接做zero-shot

