论文地址:Contrastive Deep Supervision
论文实现:https://github.com/ArchipLab-LinfengZhang/contrastive-deep-supervision
CDS:中间层做对比学习
Abstract
传统深度训练方法是在最后一层进行监督训练,然后再反向传播,这样容易导致中间层优化困难。近年来的方法有在中间层添加辅助分类器,通过这些具有监督任务损失的分类器优化可以优化浅层网络。然而这与浅层学习低层次特征,高层学习偏向任务的高层次特征是冲突的,因此本文提出了对比深度有监督学习,在9个数据集11个模型上进行了实验
Introduction
随着大规模数据集数量的增长,深度神经网络成为了主要的模型,往往只在最后一层的训练中添加了监督信息。deep supervision直接对中间层进行优化,对中间层添加了数个辅助分类器,这些分类器根据原始的最后一个分类器进行优化
浅层网络往往学习一些低级的特征,最后几层则是学习高维的任务相关的语义特征。deep supervision强行使得浅层网络去学习任务相关的知识,但是这违背了原本的特征提取的过程,这可能并不是最好的对中间层级优化的监督
作者认为,对比学习可以为中间层级提供更好的监督信息。对比学习即对一张图片使用不同的数据增广构成的样本对称为正对,将不同的图片视为负对,由此网络可以学习数据中的不变信息。数据增广下的不变信息往往是低维的,任务无关的可以迁移到不同的视觉任务,由此作者任务这对中间层学习到的信息更有利
作者提出了Contrastive Deep Supervision,通过对比学习对中间层级进行优化,如图1所示
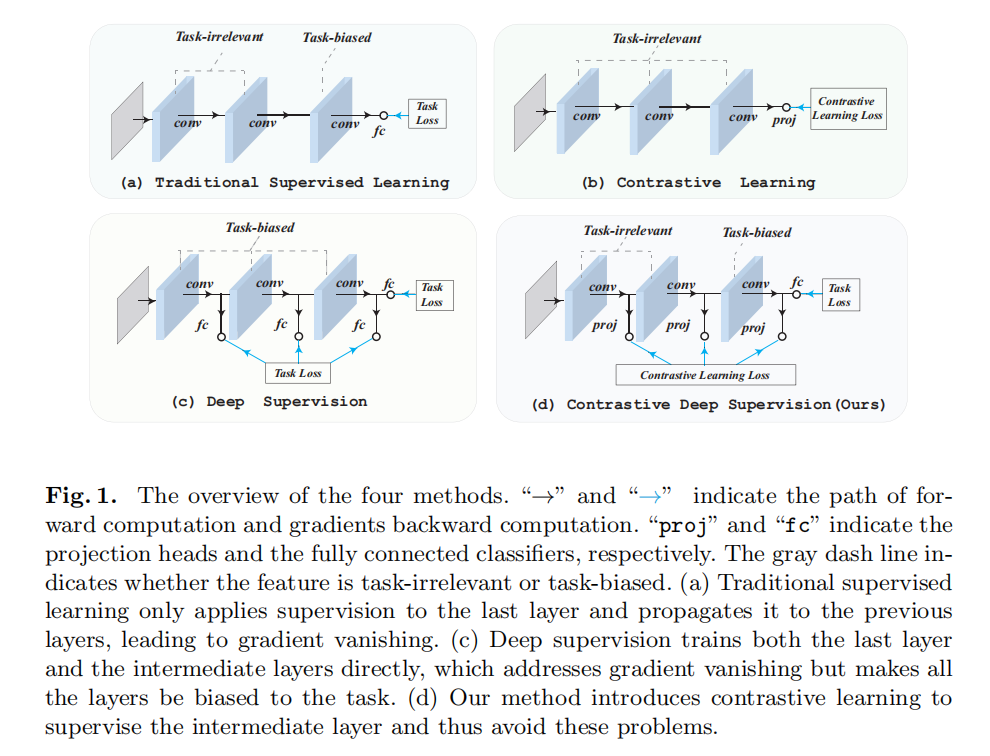
在中间层级添加多个映射头,在这些映射头上执行对比学习。这些映射头会在推理阶段被丢弃,以避免计算资源的损耗。deep supervision训练中间层去学习一个针对具体任务的知识,本文学习的是数据增广中的不变信息
作者为了增加模型效果,还使用了知识蒸馏技术,知识蒸馏往往会蒸馏那些”关键知识“,比如注意力和相连关系,使得有更好的模型表现,本文表明在中间层用对比学习来学习数据增强的不变性能够更好的做知识蒸馏
Methodology
Deep Supervision
c是backbone分类器,g是最后的分类器,$f=f_K\circ f_{K-1}\circ ···f_1$ 表示卷积阶段,每个阶段添加辅助分类器 $g_i$ ,因此有K个分类器:
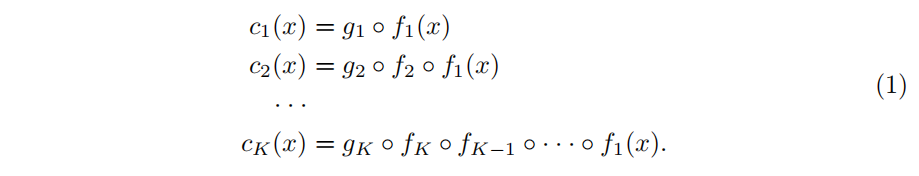
CE指的是交叉熵损失函数,deep supervision损失如下:
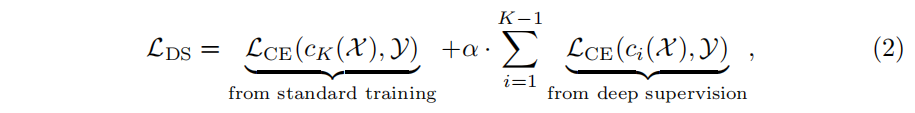
对deep supervision进行优化,针对中间层,借鉴知识蒸馏中对中间特征的蒸馏思想,对中间的特征映射向量和最后一层的向量做KL散度损失,最小化这个损失,可以看作是最后一层是教师,中间层是学生,公式如下:
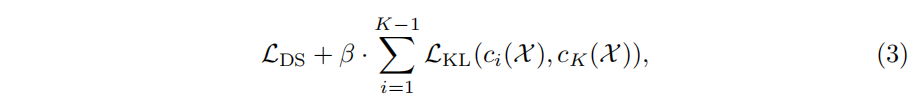
Contrastive Deep Supervision
对N张图片 ${x_1,x_2,…,x_n}$ 做数据增强得到2N图片,$x_i$ 和 $x_{i+N}$ 是正样本对,$z=c(x)$ normalized projection head输出
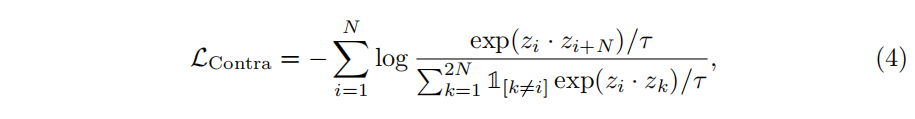
本文方法和deep supervision的主要不同在于,deep supervision通过交叉熵损失来训练辅助分类器,本文使用对比损失来训练辅助分类器
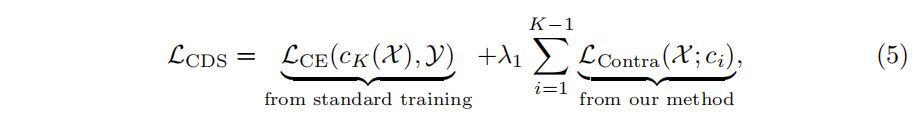
Semi-supervised Learning
半监督任务主要思想是没有label的数据部分只使用对比学习,有label的部分使用CDS损失
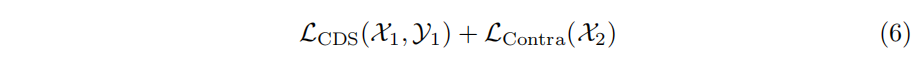
Knowledge Distillation
知识蒸馏主要思想是对学生网络和教师网络对应的中间层的projection输出以及最后层的任务输出都进行蒸馏
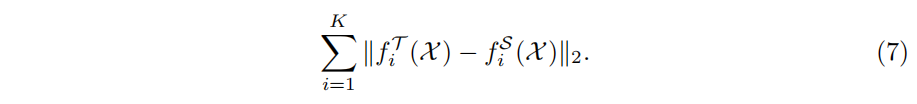
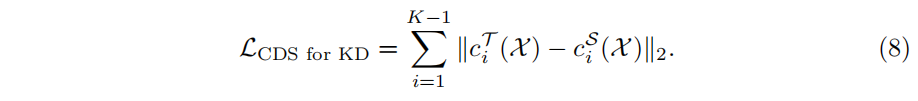
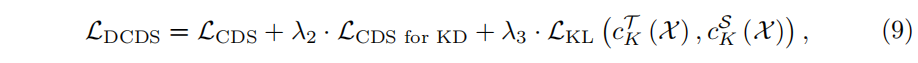
Other Details and Tricks
Design of Projection Heads
一般的projection head就是两层全连接+relu,但是在中间层这么做太简单了,所以在非线性投影前加了卷积层
Contrastive Learning
本文提出的是一个泛化的对比学习框架,还有提升空间
Negative Samples
负样本的数量对对比学习的表现有很大的影响,现有方法往往要依靠:大的batch-size,动量编码器或者是memory bank来解决。本文不需要依靠这些方法,因为有监督的损失可以避免对比学习收敛到崩溃解
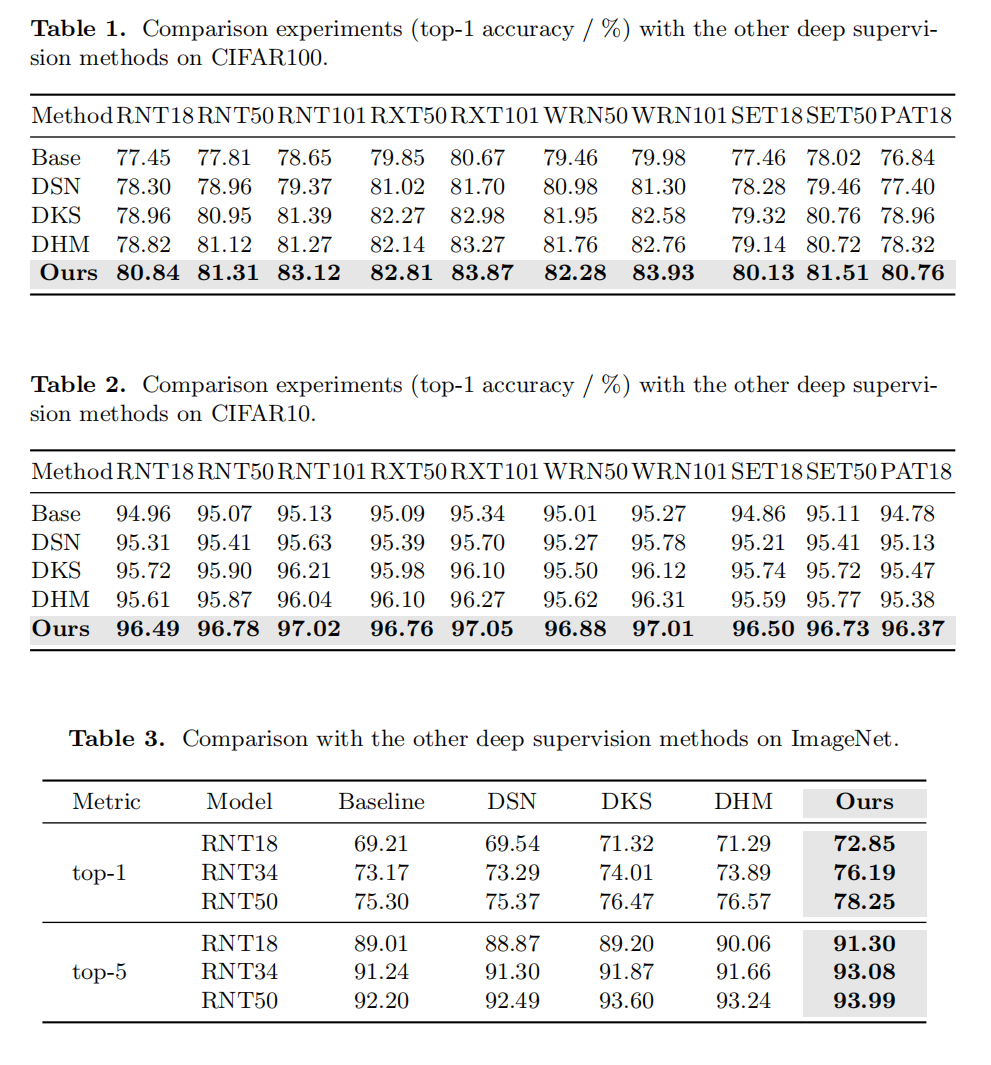
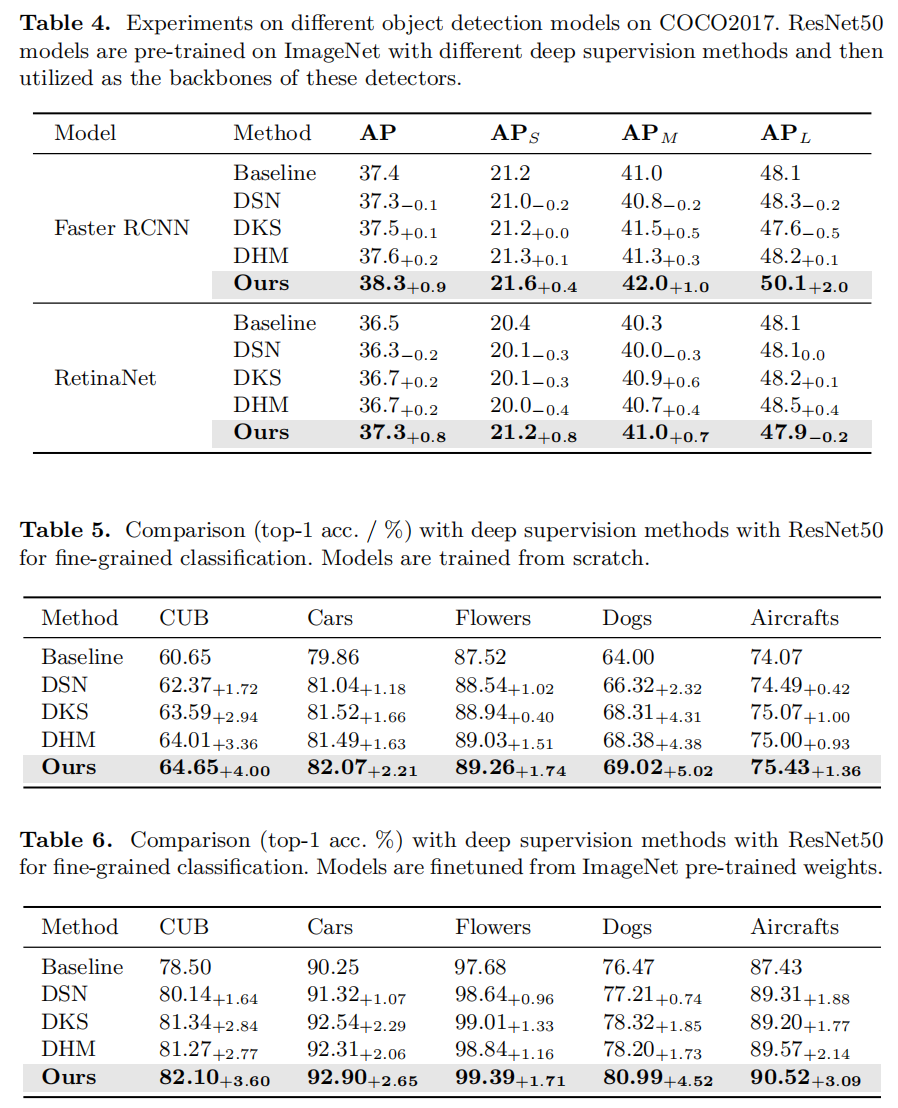
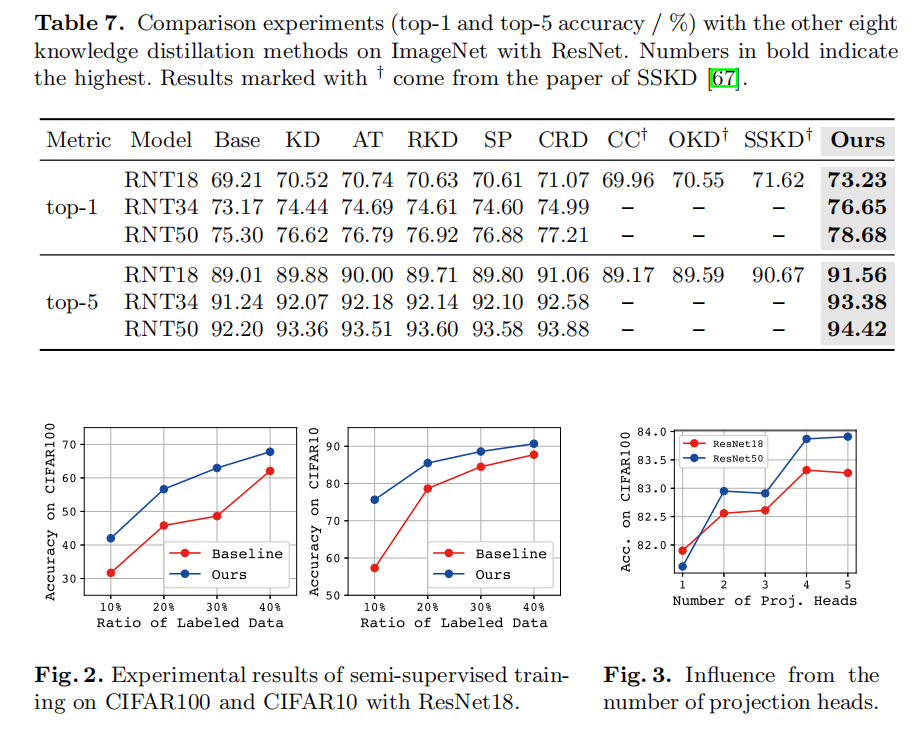
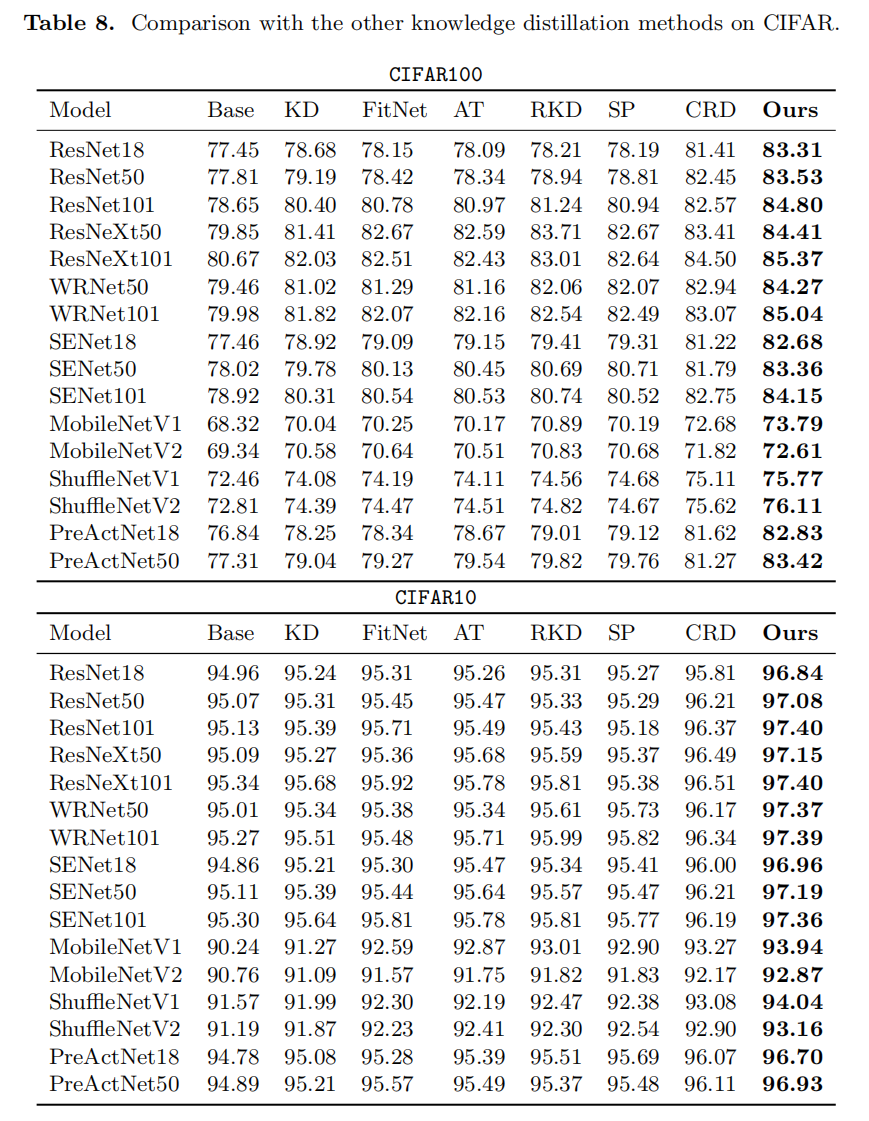
Experiment
Discussion
Contrastive Deep Supervision as a Regularizer
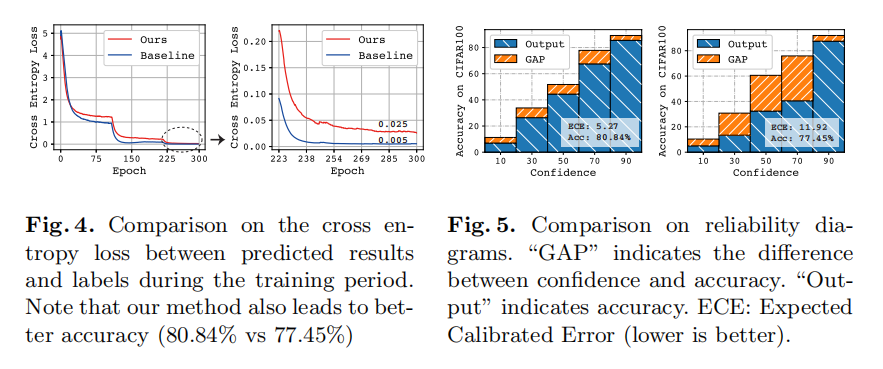
在中间层对比学习类似于一种正则化,缓解过拟合问题;ECE越低表示预测概率是真实的可能性更高
Comparison with Contrastive Learning
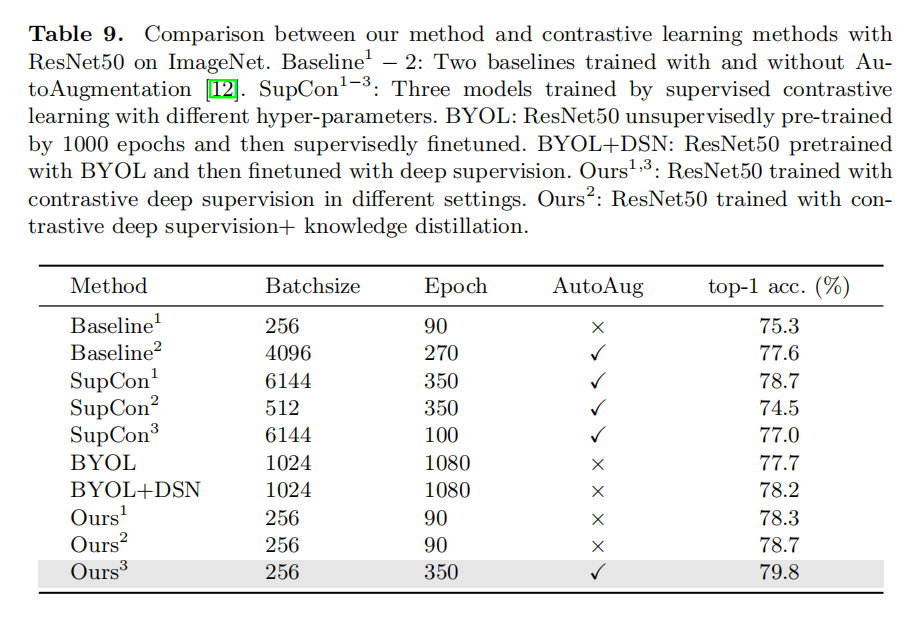
不要大batch_size,也不需要autoaug也能取得不错的效果

