DNABERT:预训练DNA模型
Abstract
Motivation:解译非编码DNA的语言是基因组研究中的基本问题之一。由于存在多义关系和遥远的语义关系,基因调控编码高度复杂,以往的信息学方法往往无法捕捉到,尤其是在数据稀缺的情况下
Results:DNABERT捕获基于上游和下游核苷酸上下文的基因组DNA序列的全局和可转移的理解。单一预训练的transformer模型在使用小的任务特定标记数据进行微调后,可以同时在启动子、剪接位点和转录因子结合位点预测方面达到SOTA。DNABERT能够直接可视化输入序列中的核苷酸水平重要性和语义关系,从而更好地具有可解释性和准确识别保守序列基序和功能遗传变异候选。最后,我们证明了人类基因组预训练出来可以很容易地应用于其他生物体
Introduction
相同的顺式作用因子 Cis-regulatory elements在不同的生物环境中通常具有不同的功能和活性
Materials and methods
The DNABERT model
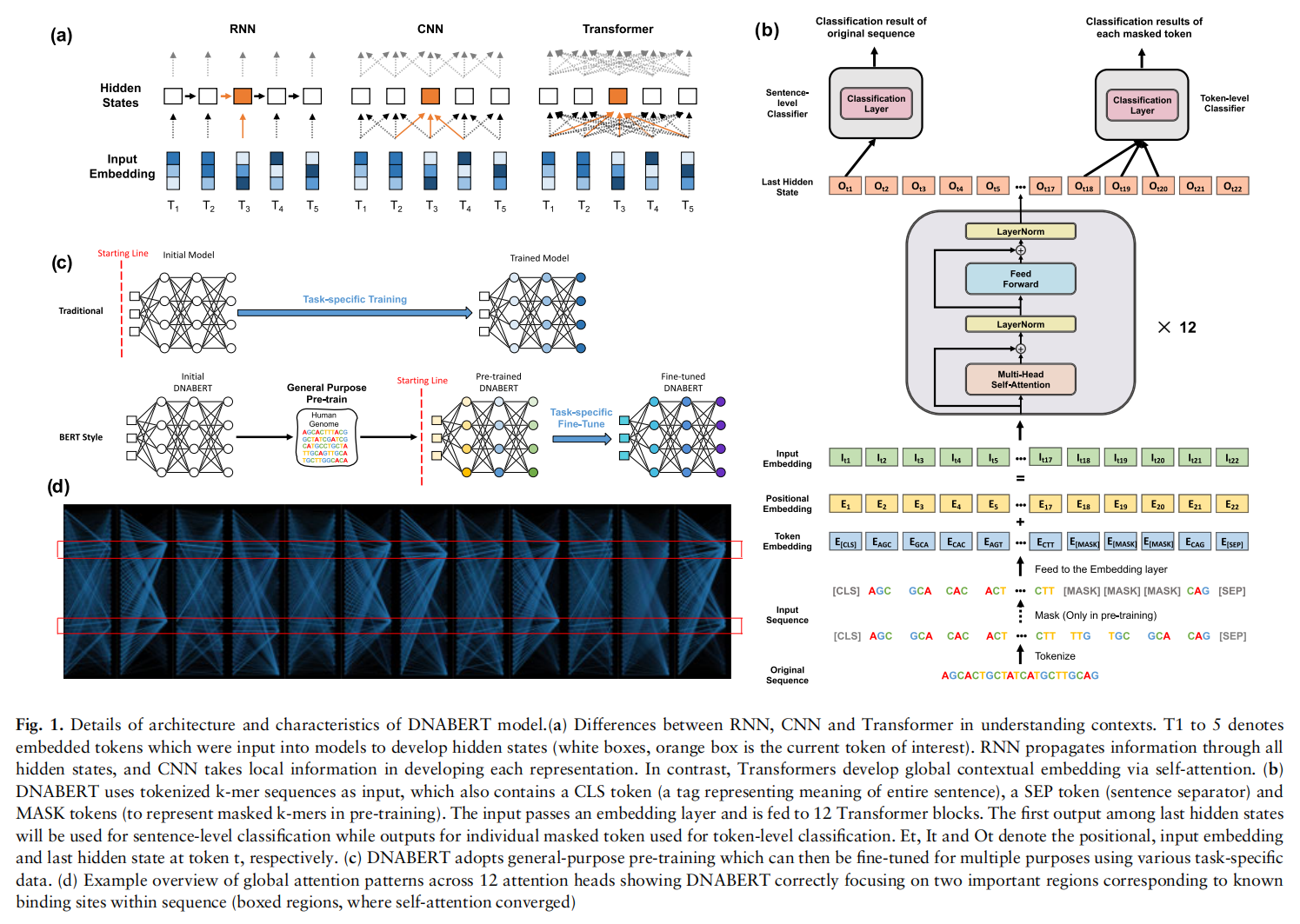
Training of the DNABERT model
将序列转化成k-mer的token表示作为输入,token还包含一个CLS标记(表示整个句子含义的标记)、一个SEP标记(句子分隔符)和MASK token(在预训练中代表k-mers)
采用了3-mer,4-mer,5-mer和6-mer四种方式来对DNA序列进行编码,例如,‘ATGGCT’在3-mer的编码方式下会变为以下四个token {ATG, TGG, GGC, GCT},实验中设置了这个k表示DNABERT-k
Pre-training
通过直接非重叠分裂和随机抽样从人类基因组生成训练数据,序列长度在5-510之间
训练120k个steps,baatch_size=2000,前100k个steps用15%掩码,后20k用20%
Fine-tuning
在所有的下游应用中使用同样的训练trick,学习率先升再降,具体细节看代码就行
Results
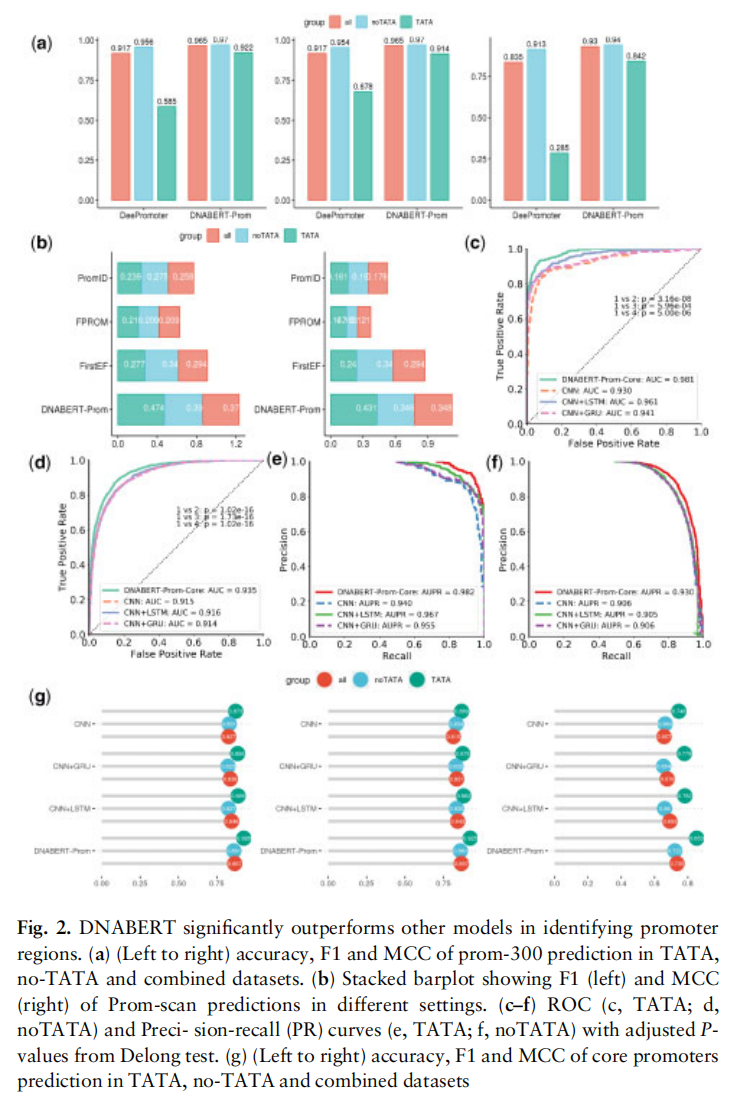
- 第一个实验是用在预测启动因子上,作者给微调后的模型起名为DNABERT-Prom。为了和基线的方法比较,作者还增长了输入长度,采用了1001bp的模型,实验表明无论参数如何,DNABERT-Prom都优于传统的CNN,CNN+LSTM和CNN+GRU(如图2所示)
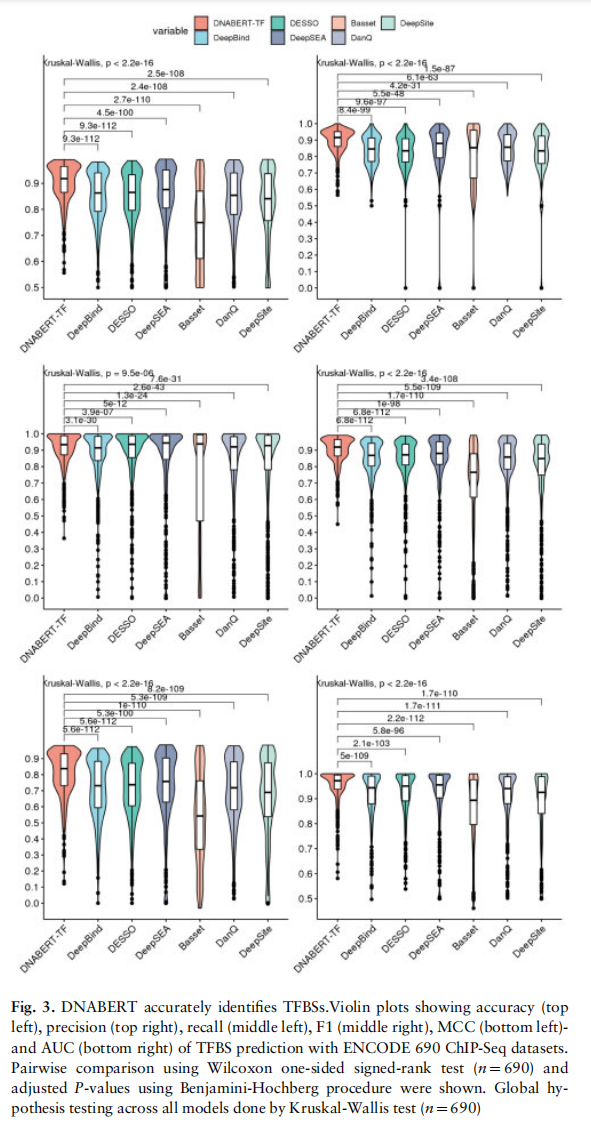
- 第二个实验是识别转录因子结合位点,先前的模型在寻找true negative上达到了和作者提出的DNABERT-TF模型一样的表现,但是预测了过多的false postive和false negative位点。并且在低质量的数据集上,DNABERT-TF和其他的模型相比取得了极高的召回率
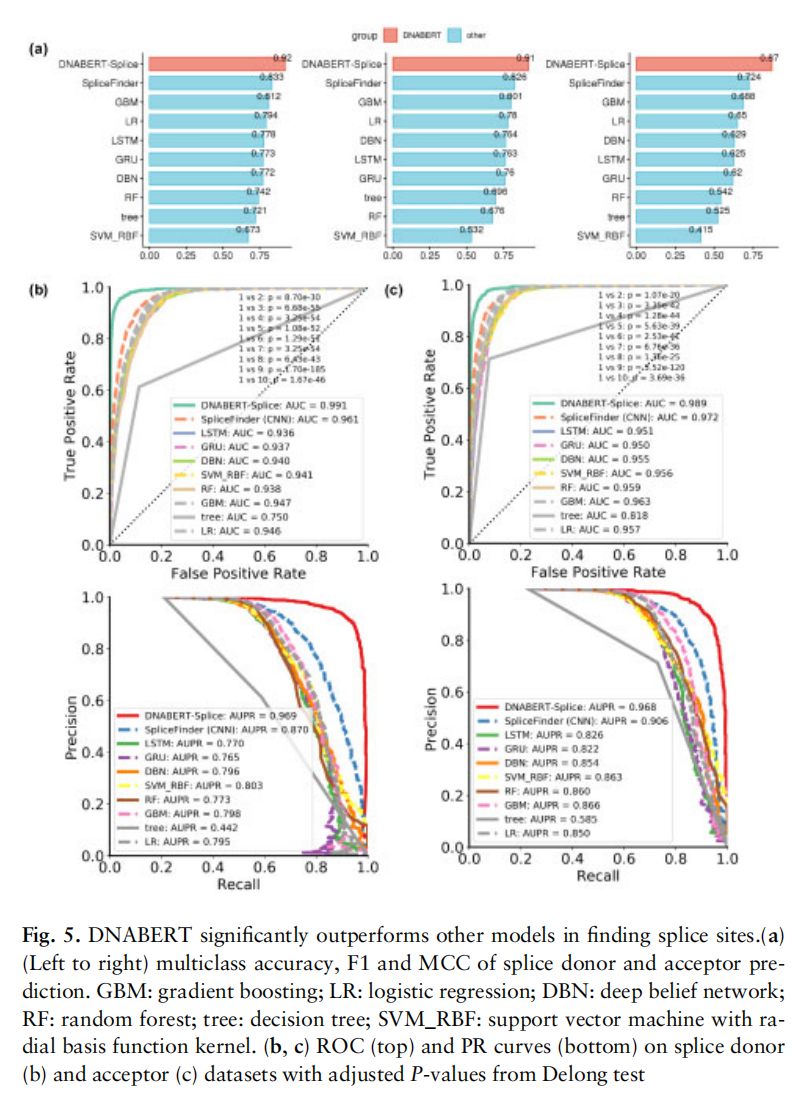
- 第三个实验用在了识别规范或不规范的剪辑位点上。同样,与对比实验的诸多方法相比,基于DNABERT的DNABERT-Splice取得了优秀的实验数据,并且通过注意力的解释发现模型突出强调了内含子的作用功能的重要性
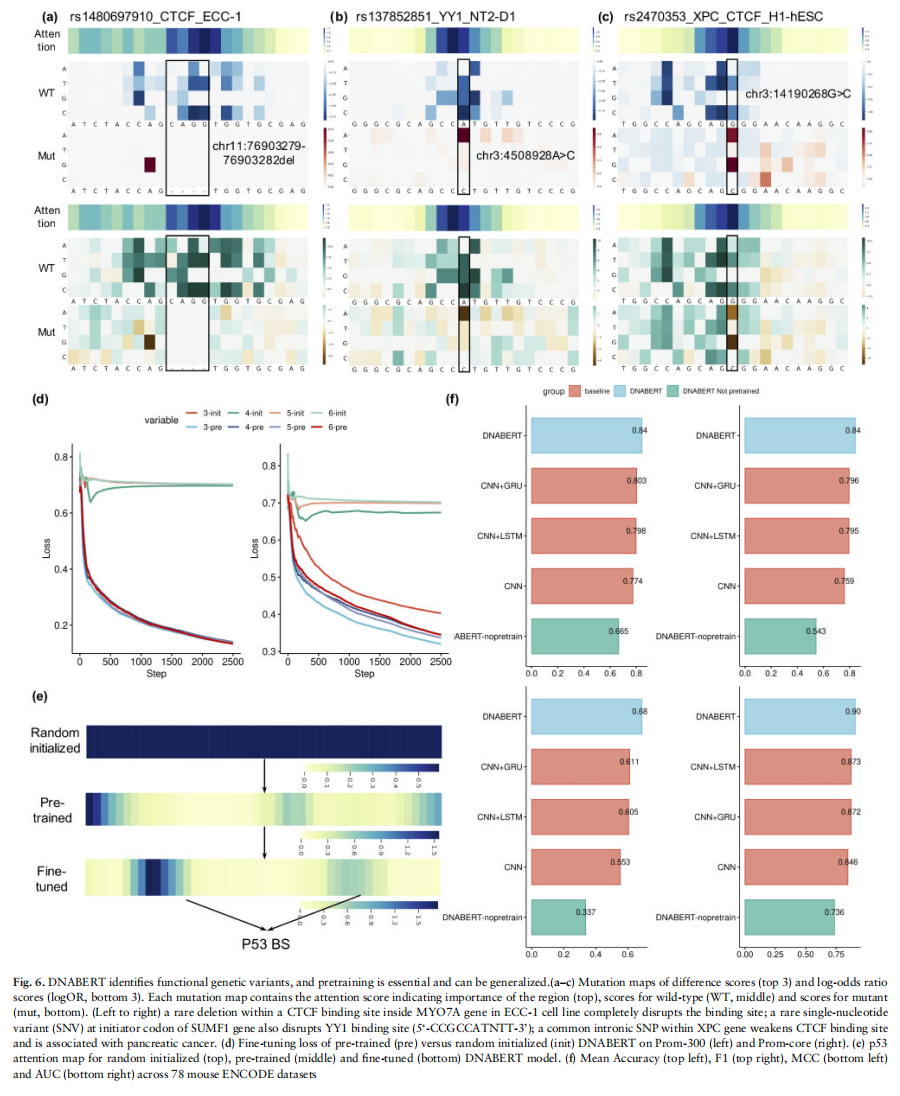
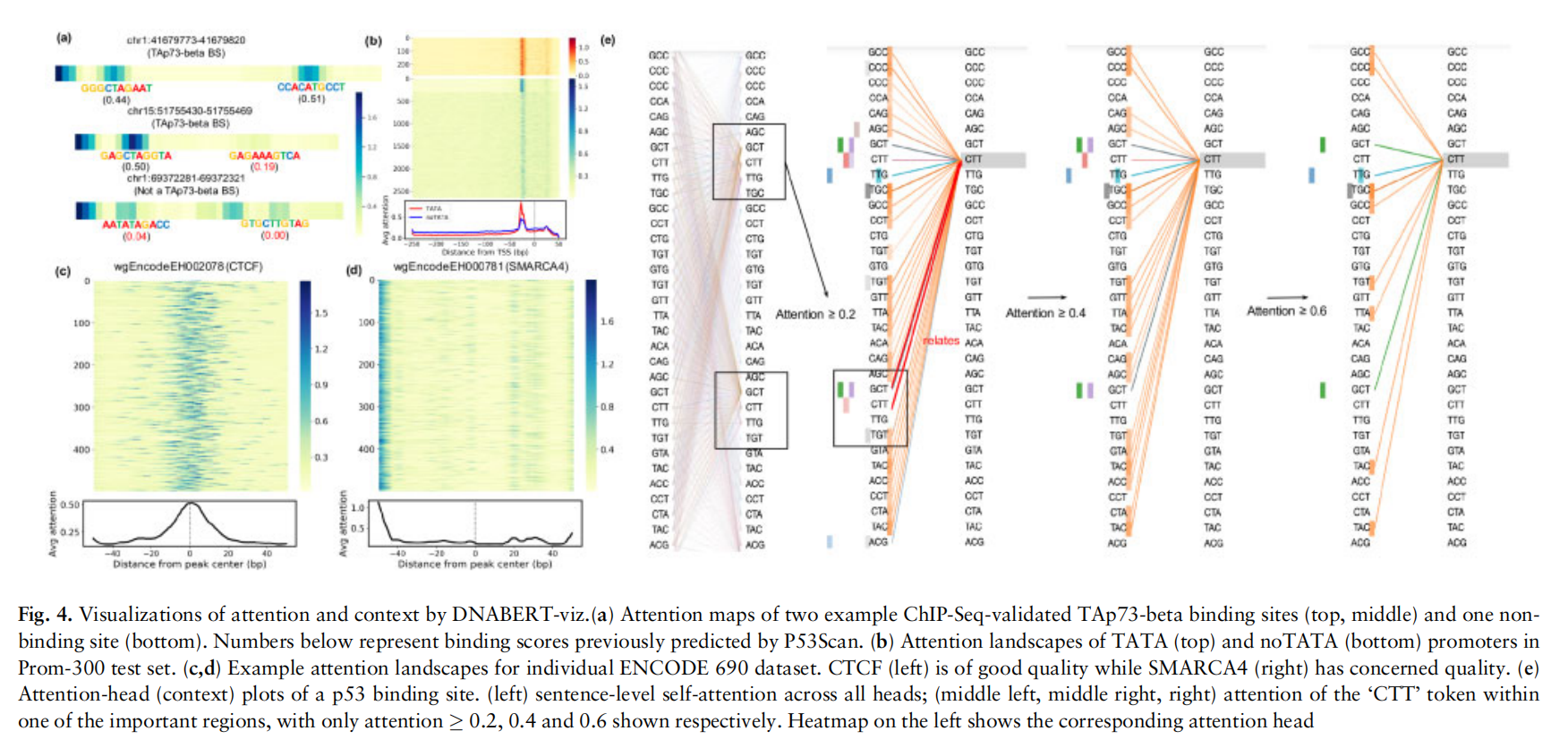
为了克服深度学习中的黑箱难以解释的问题,BERT模型需要解释出自己学习到的东西。因此,作者做了相关的工作来证明对于BERT寻找相关的重要位点和理解它们与上下文的关系是非常自然的
通过可视化bert的attention层得到的分数解释了学习的重要位点在哪里(如图4所示),a图即是随便选取了几条序列得到的结果。通过b图和c图都说明了模型学到了一定的知识,一个是-20到-30bp位置,一个是中心的左右位置,但是在低质量的数据集上可能只有在开头有很高的注意力,如d图。接着,作者在e图中可视化了序列上下文的关系,可以看出黄色的head注意力集中到了CTT位点上,同时也有三个其他的head(绿色,紫色和粉红)也成功注意到了这个位点,表明多头已经理解了上下文的相关性和重要性
预测剪接位点
用DNABERT识别功能性遗传变异
证明预训练和在具体任务上的微调是有作用的,分别进行了对比实验和对应attention的可视化操作(如图4所示),从d图和e图看出有了很明显的提升。而后作者又在小白鼠的数据集上进行了迁移实验,从f图看出结果依旧表现很好,说明模型抓取到了DNA共有的深层语义,进一步突出了预训练的重要性