论文地址:Align before Fuse:Vision and Language Representation Learning with Momentum Distillation
ALBEF:多模态融合前先做动量对比学习
Abstract
最近大规模的视觉-语言表征学习进步很大,大部分方法都是用一个transformer的模型当作多模态的编码器,同时编码视觉的token和文本的token。用了预训练的目标检测器之后,视觉特征和文本特征其实不是align的(目标检测器是提前训练好的,导致视觉特征和文本特征可能隔很远)。为了在经过multimodal encoder之前(fusion之前)把图像和文本align起来,用了对比学习loss。为了更好的从有噪声的网络数据学习,用了一个momentum distillation自训练方式,打伪标签
ALBEF Pre-training
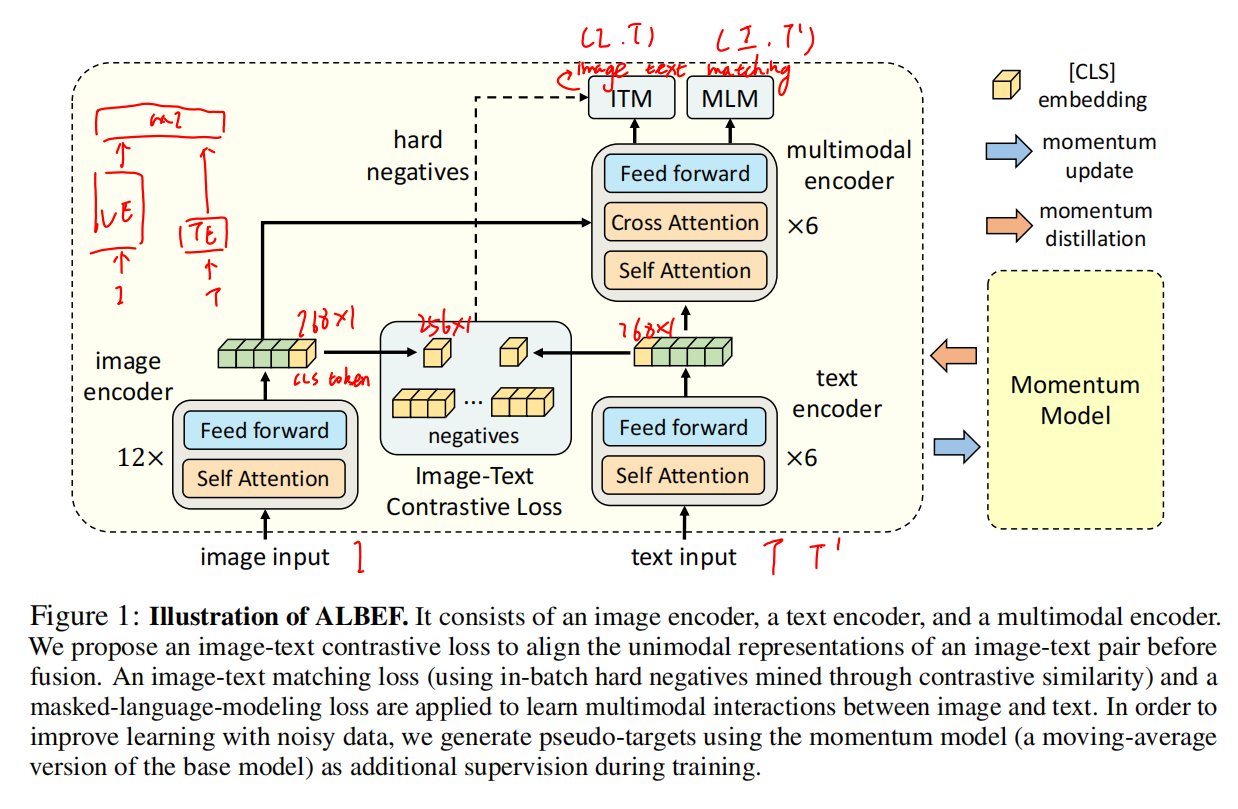
Pre-training Objectives
图像特征和文本特征丢到多模态encoder之前先尽可能拉近,这里的ITC loss完全按照moco里面来的
ITM loss这个对正样本还可能比较困难,但是对负样本来说还是非常简单的,这样训练再长时间其实也没有多少意义,所以在训练的时候需要加一些限制,去选择那些难的负样本(最接近正样本的负样本)。负样本是通过在前面的ITC loss里面算了cos sim然后拿出除了自己之外相似度最高的文本,其实文本和图片已经非常相似了,但是硬说这个是负样本(hard negative)
最后一个loss就是MLM,把缺失的文本和图像经过ALBEF模型,最后把完整文本预测出来,借助了图像这边的信息
因此每个训练的iteration其实做了两次模型的forward,一次用的原始的I和T,一次用的原始的I和mask后的T‘
Momentum Distillation
网上爬下来的图像文本对经常是weakly correlated,文本的很多单词图像没有,或图像的很多物体文本没有。这样在算对比学习loss就有偏差,比如负样本可能也描述了很多这个图片里的内容,可能不是爬下来当作ground truth的结果,但可能这个已经很好描述了。这时候非要把他当负样本,其实对ITC学习问题很大
对MLM来说,完形填空的空可能存在比ground truth更好的结果
因此用网上爬下来的one-hot label对这两个loss是不好的,因此找到额外的监督信号,不是One-hot而是Multi-hot,或者是额外模型的输出就行了,就是self-training,用一个动量模型来生成pseudo-targets(一个softmax score,不是One-hot label)
具体方法就是在已有的模型上做exponential-moving-average(EMA),训练的时候不仅和one-hot ground truth尽可能接近,和动量模型出来的pseudo-targets也尽可能match,达到一个不错的折中点
对ITC来说
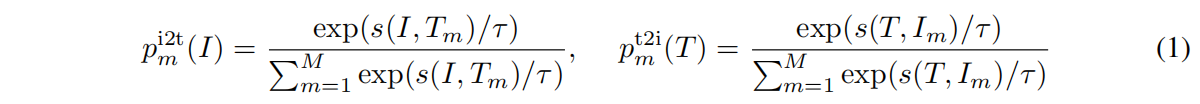
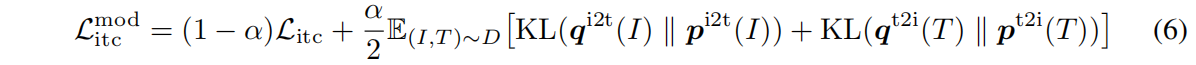
因为q是一个softmax socre,而不是one-hot label,所以用的KL散度而不是交叉熵
对MLM来说
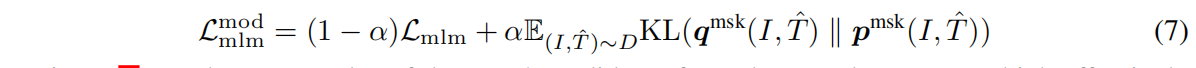
所以对ALBEF的训练loss来说有五个,两个ITC,两个MLM和一个ITM。因为ITM本身就是基于ground truth的,需要知道这是不是一个pair,就是一个二分类任务,又做了hard negative,这和momentum model有冲突

可以看出确实有很多的选择比ground truth要好,使用pseudo-targets确实有好处
Pre-training Datasets
两个web数据集 Conceptual Captions, SBU Captions;两个domain数据集 COCO and Visual Genome
Downstream V+L Tasks
Image-Text Retrieval
图像文本,图像到图像的检索等,商用价值高
给定一个数据库怎么搜到ground truth的图像文本对,一般用recall,R1,R5,R10,检索回来的几个sample里有没有ground truth sample
Visual Entailment
给一个假设前提,能不能推理出这个前提,推理出来的就是蕴含,推不出来就是矛盾,不然就是中立
三分类问题,用分类准确度
Visual Question Answering
视觉问答,给定问题,给定图片,能否回答问题
两种设置
- answer是固定的,固定的set,从里面选,变成了一个多分类问题,这就是闭集VQA
- 另一种是开集VQA,生成文本,需要transformer decoder去生成,任务难度就大了很多
Natural Language for Visual Reasoning
预测一个文本能不能同时描述一对图片,二分类问题,衡量指标是准确度
Experiments
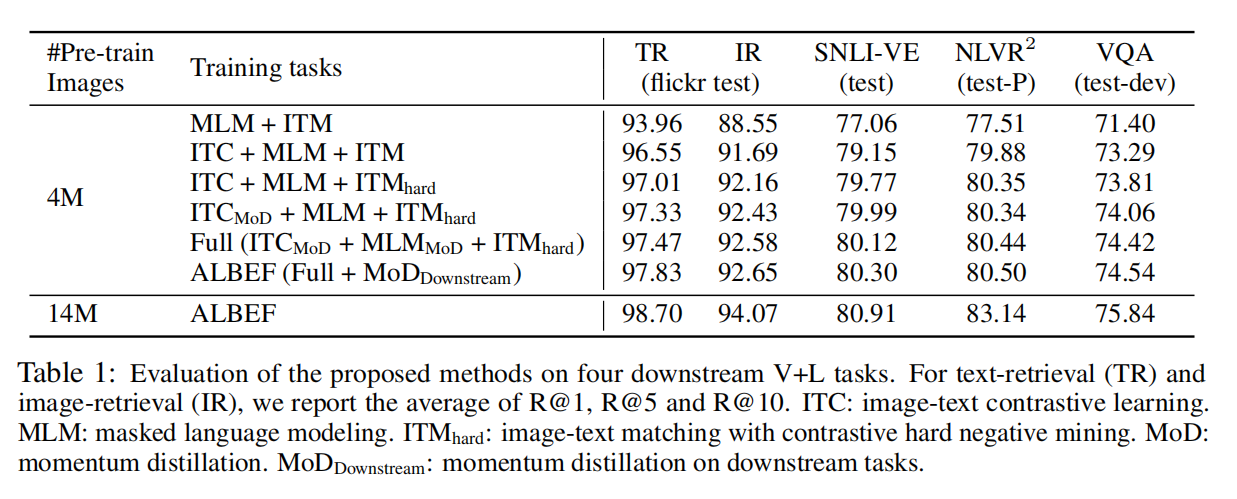
加了ITC之后提点很明显,用了hard negative之后效果也有提升,但对于换更大的数据集而言这些trick都无关紧要
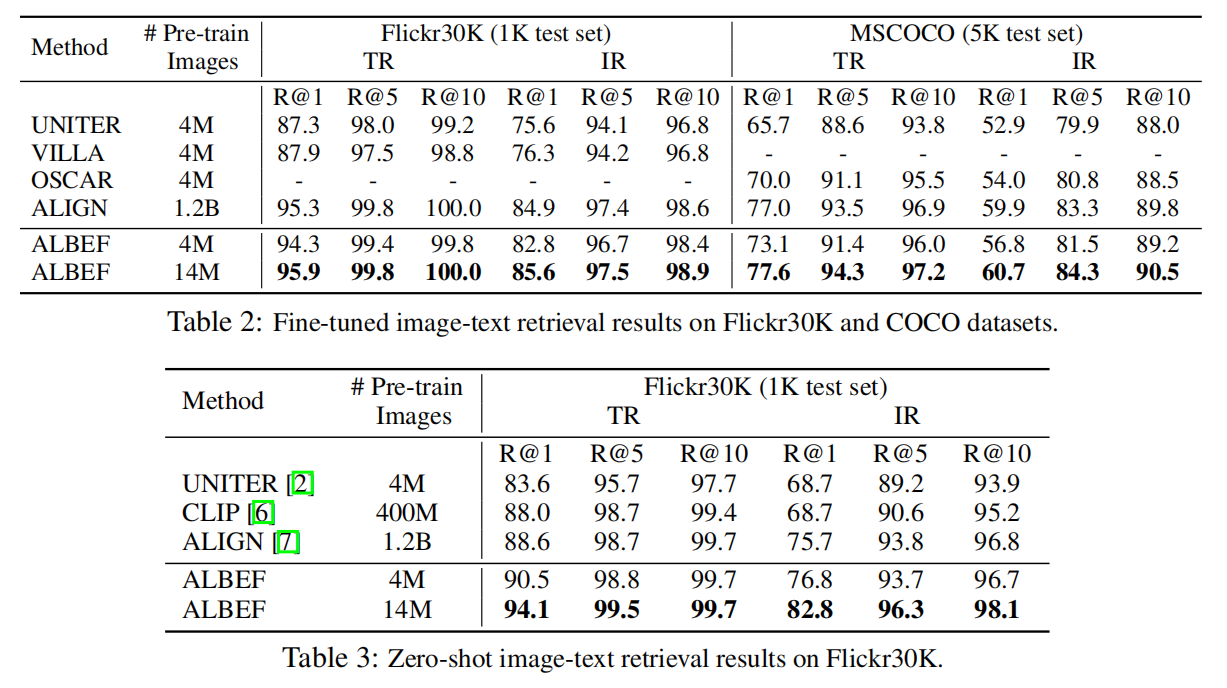
图文检索,数据集已经被刷爆了