论文地址:VLMo:Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
论文实现:https://aka.ms/vlmo
VLMo:MoE做多模态
Abstract
使用了混合模态专家模型和分阶段训练
Introduction
现在多模态学习领域有两种主流结构:
- 一个是像CLIP这种dual encoder双塔结构,模态之间的交互就是一个简单的cosine similarity,非常适合大规模是图像文本检索等,有很好的商业价值。但这种交互太shallow了,即使是CLIP在下游任务上也比不上SOTA
- 另一个就是fusion encoder,文本图片先分开处理一下,然后用transformer encoder去做模态交互,因此在VL classification task上很好,但在图像文本对特别多的情况下要把全部都encode再编码,推理时间就会非常慢,大规模数据集就不现实
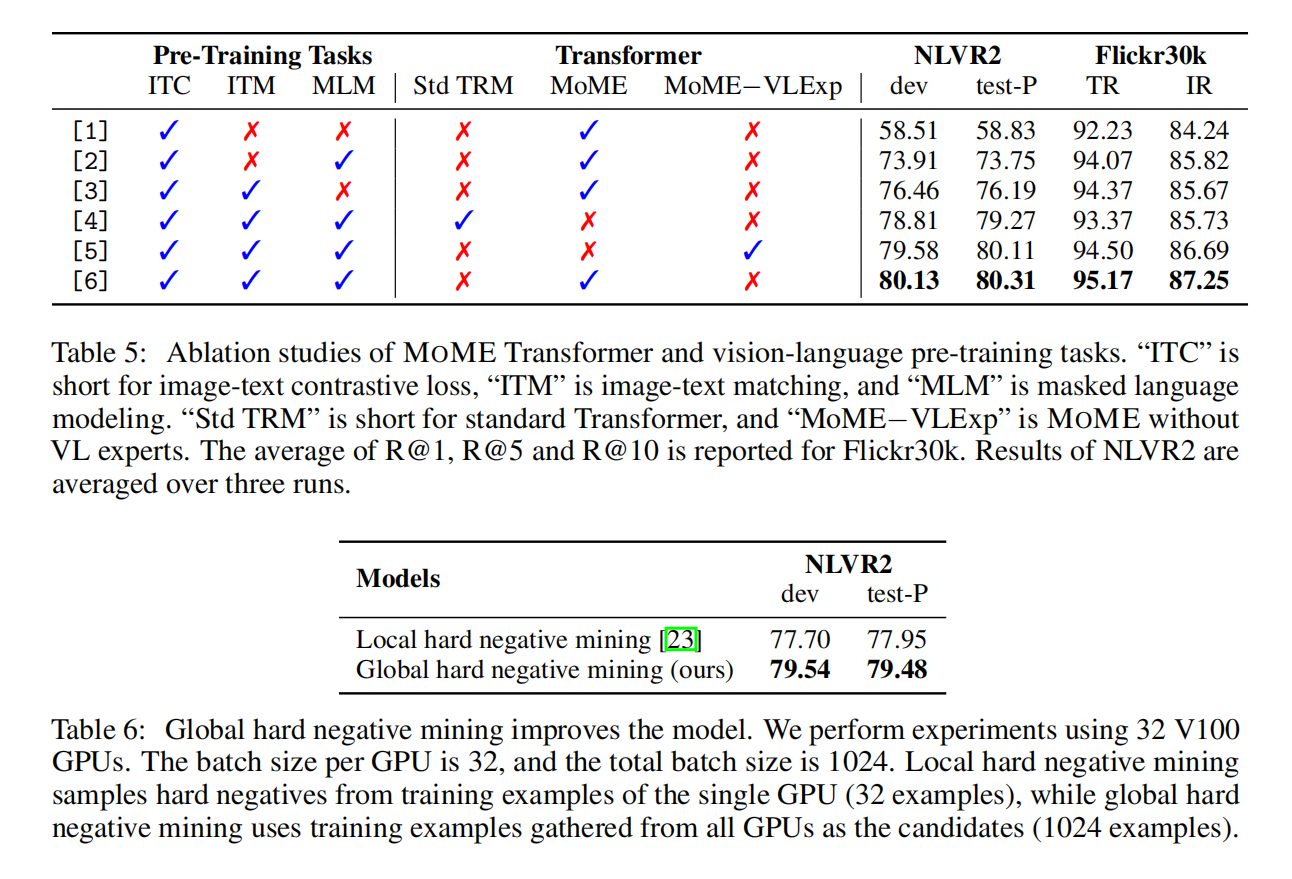
因此作者提出要把两者优点结合,让模型既可以用dual encoder,又可以用fusion encoder,因此提出了mixture-of-modality-fusion,每个模态对应自己的expert,根据输入训练和推理
训练的目标函数是ITC,ITM和MLM
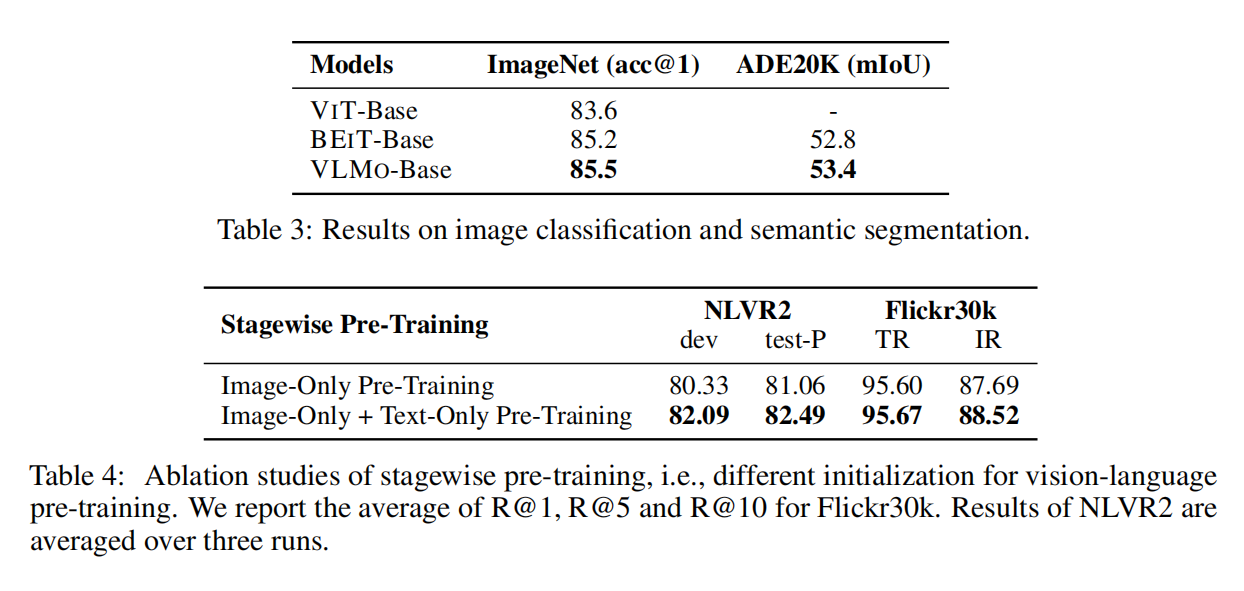
多模态的数据集大小比不上单模态的数据集,因此提出分阶段训练,把用图像数据把vision expert训练好,再用文本数据把langugae expert训练好,带来了很大的提升
Methods
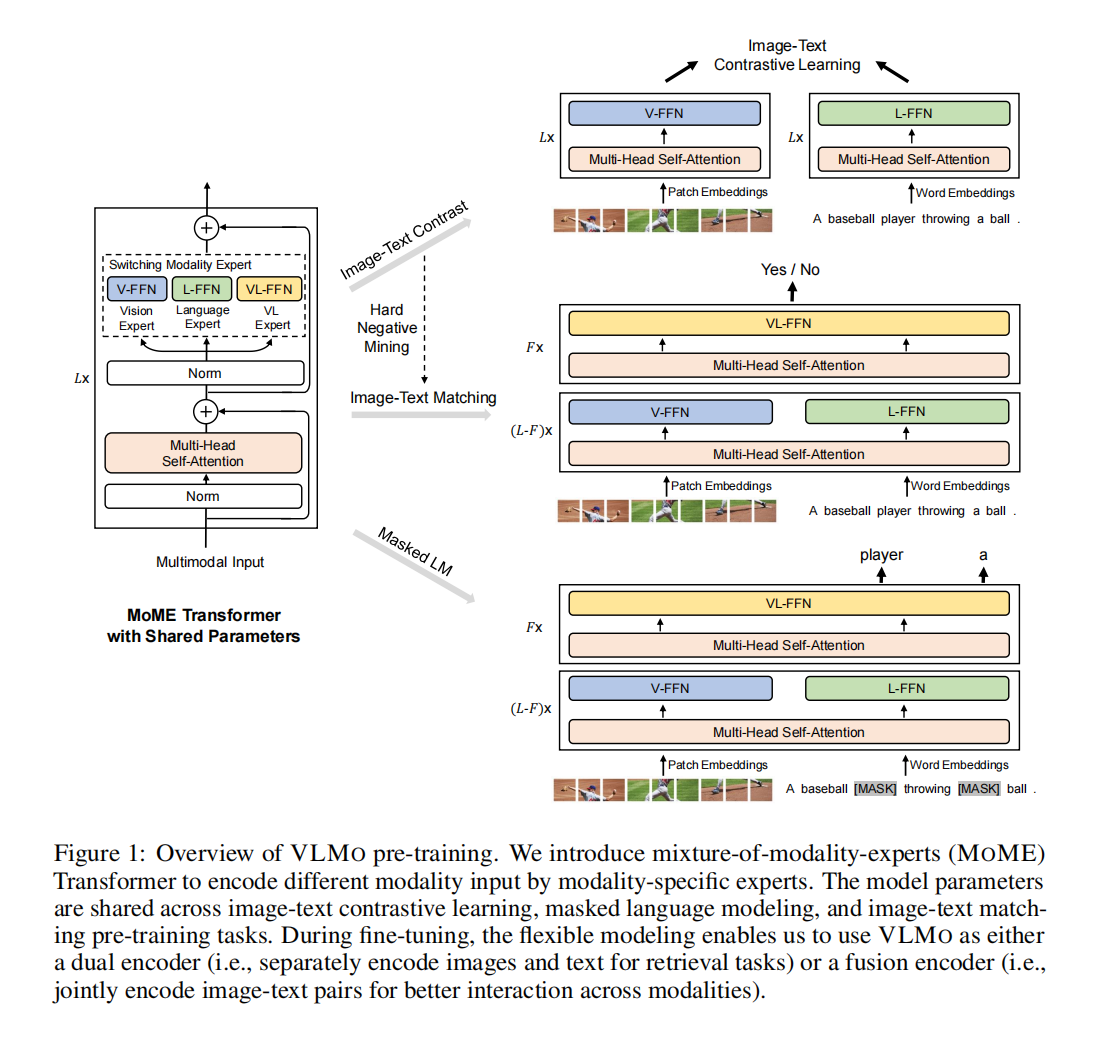
每个模态一个FFN
算ITC的时候直接化身CLIP,算ITM和MLM的时候变成fusion encoder,
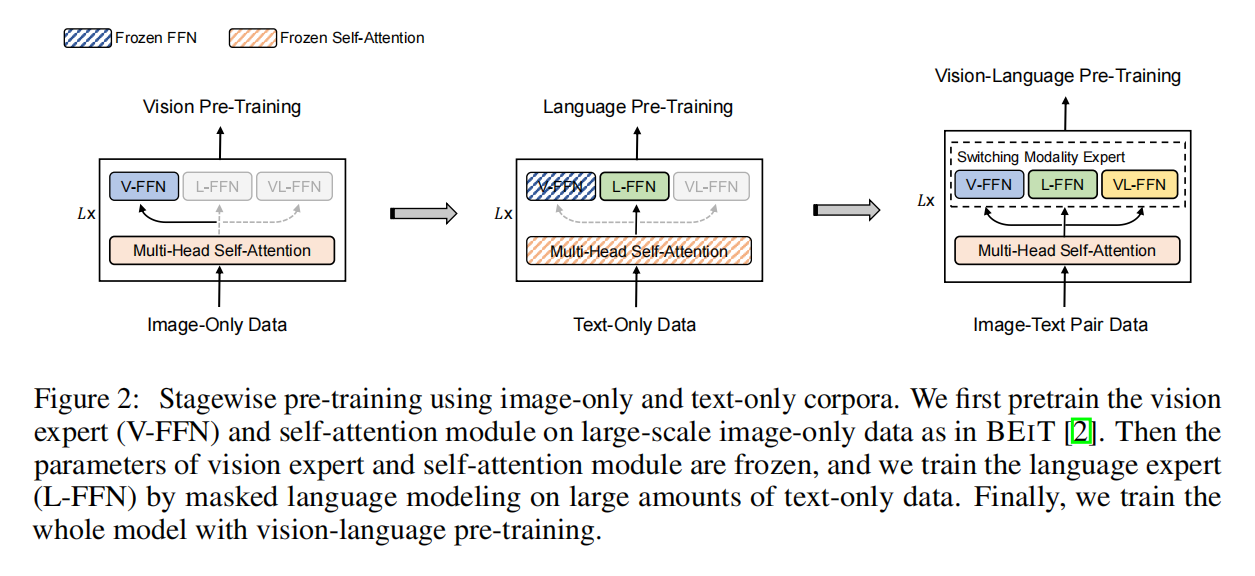
从左向右的顺序训练,在language pre-training的时候直接用的图片训练好的self-attention,很奇怪但有趣,最后阶段都打开做fine-tune
Experiments
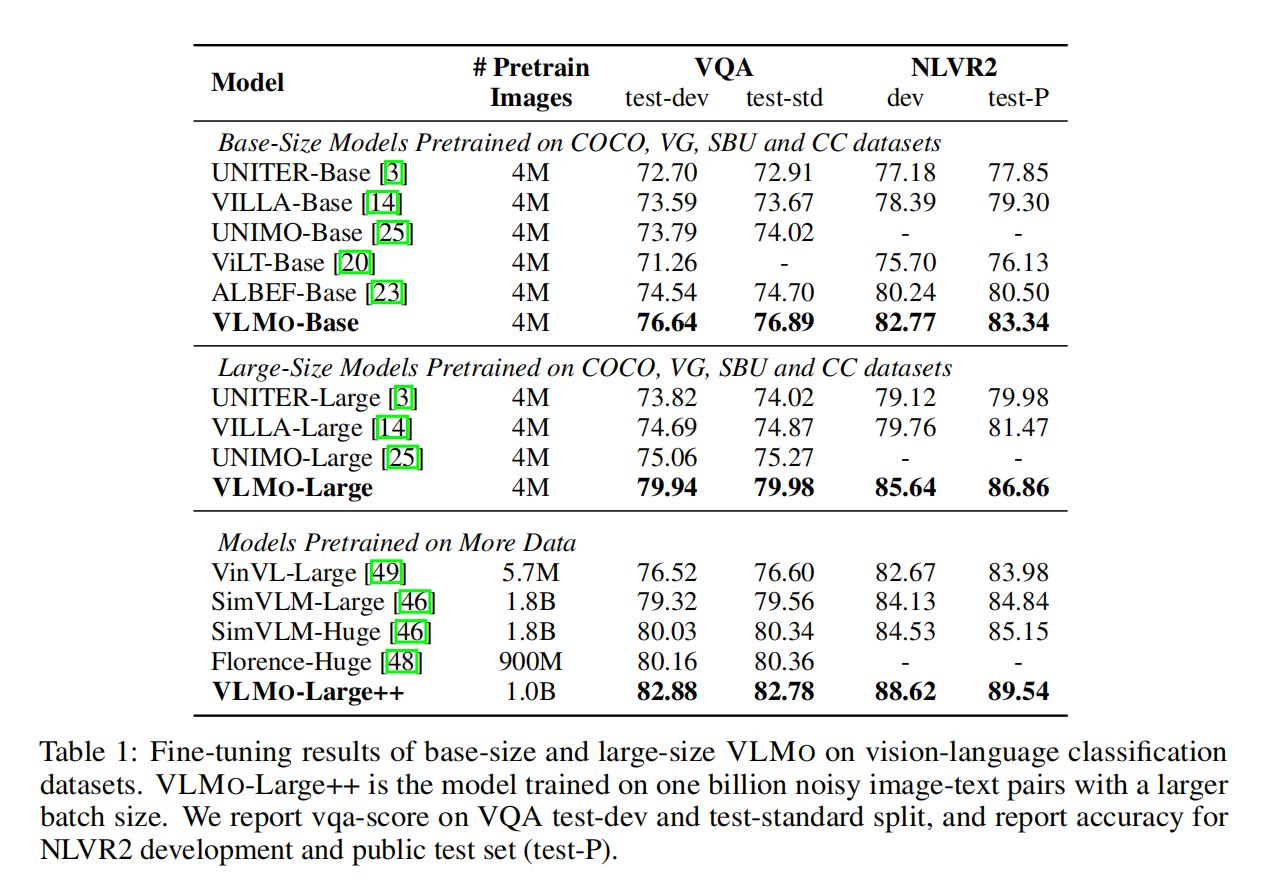
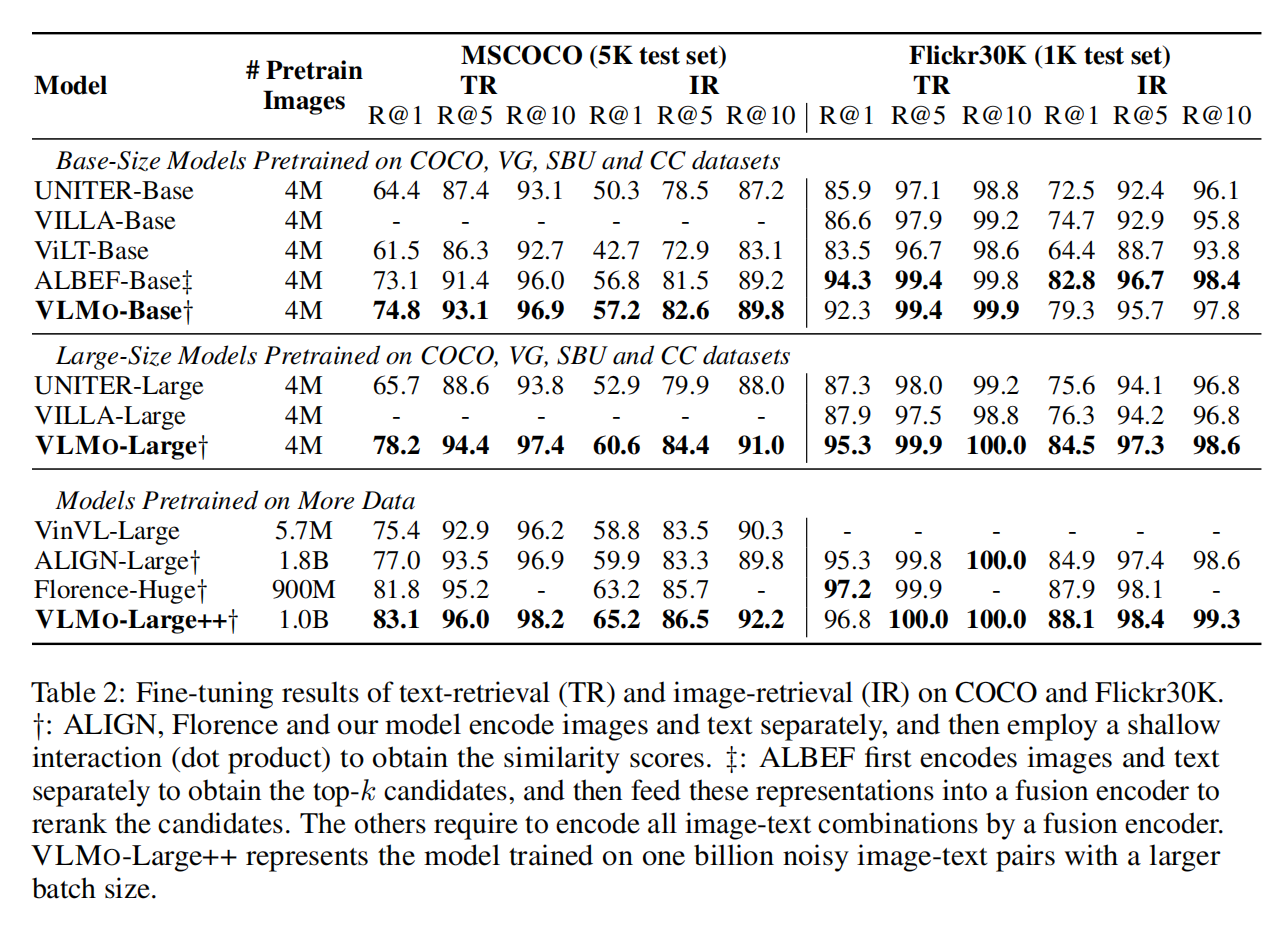
Conclusion
未来工作
- 提升VLMo预训练模型规模(BeiT-v3,用的ViT-G)
- 做更多下游VL task(VL-BeiT)
- Unimodality能够帮助multimodality
- 用于speech(WAVLM),video(LayoutLM v3),structured knwledge,以及通用模型(MetaLM)

