NCI:端到端文档-索引模型+层次聚类+PAWA decoder
Abstract
现在的文档检索系统通常是基于索引的,但这种方法就很难根据最终要检索的目标来做优化。本文提出一个端到端的神经网络把训练和检索糅合在一起能够提高召回率,提出了一个叫NCI的方法,能够根据查询直接生成相关的文档索引,还提出了一种prefix-aware weight-adaptive decoder架构,能够提升性能很大
Introduction
文档检索和排序是搜索引擎最重要的两个stage,排序往往会做成一个神经网络,把query和document作为对输入来预测他们的相关分数。但这种行为比较贵,特别在文档数很多的情况下,因此最多选几百一千个,所以这个时候检索就很重要了,把相关的东西先都找出来
现有的检索方法分为两种
- term-based:建立一个对整个语料的inverted index(所有的term到index的映射),看个某个词就返回页面或词条,不能获取语义
- semantic-based:把query和document同时映射成embedding,用的双塔架构,然后用一个ANN(Apporximate Nearest Neighbor)近似搜索。但如果用一个简单的embedding vector的话也可能有点问题,比如需要exact match的时候,需要精准的匹配不需要模糊的近似
好处是可以做一个端到端的优化,以及抓出term-based和semantic-based特征,能够adaptive to the changing of workloads,而且能够抓住更深层的交互
此外从系统设计来说也会更好,原本ranking是神经网络,现在retrieval也换成神经网络,整个设计会更简单而不需要其他的sub-modules。但是因为性能问题,其实基本不可能部署的
主要贡献
- 展现了一个端到端的可微文本检索模型能够带来巨大提升
- 提出了NCI根据给定query直接生成docid
- 设计了一个新的decoder
Neural corpus indexer
NCI是一个端到端的网络,以query为输入,输出最相关的document identifier(docid),但是只是这样就会使得模型没有记住文档的信息,因此肯定是要让模型能了解到文档的。可以把一个doc变成多个query,形成多个query-id对拼进去进入模型
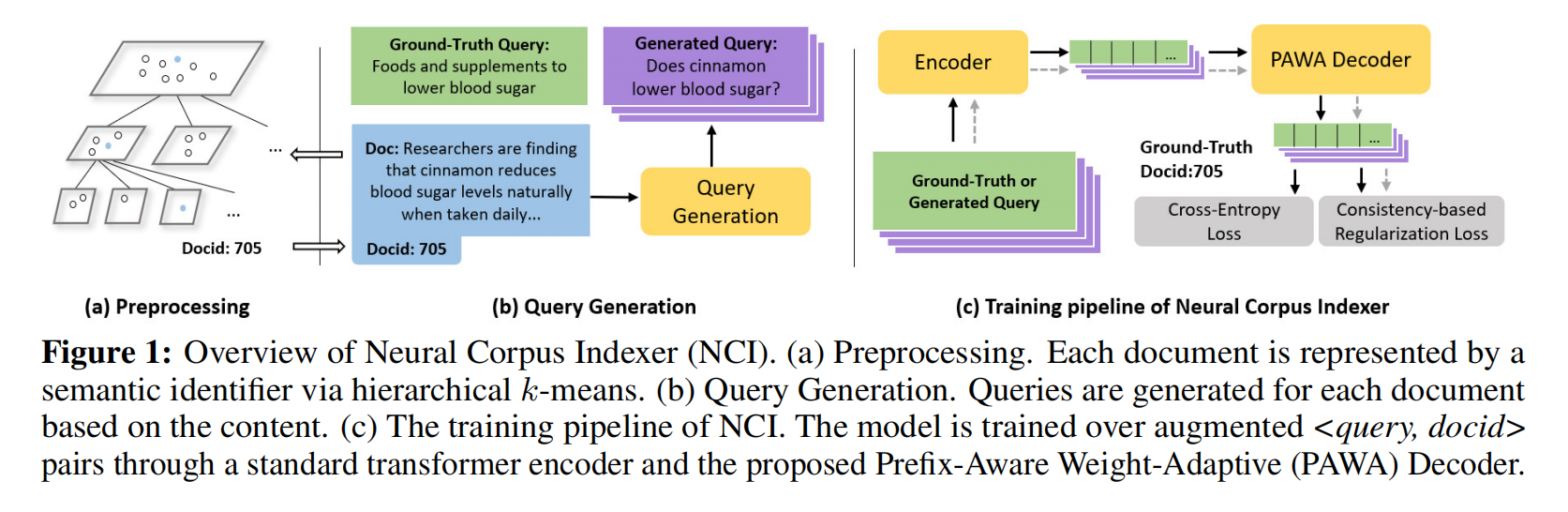
怎么映射成docid;给定文档怎么生成query;把生成的query和ground truth拼起来放入encoder-decoder,对decoder做一个改进和设计损失函数
Representing document with semantic identifiers
使用hierarchical k-means,在图1a里面,先对所有的document embedding做聚类,比如分1、2、3,如果某个类多于某个阈值就进一步做聚类分11、12;21、22、23等,获得上一个类的前缀,最后得到的比如11里面的内容重新标号出111、112等得到最终的id,这就是层次多分类问题。这样的id多少有点语义信息的,后面的预测是根据前面的预测做出来的
Query generation
DocT5Query:用一个巨大的transformer将一个document映射到一个query,每步根据预测出来的概率分布采样出一个词,这里采样不是用的beam search而是random sampling,作为训练数据多样性好随机性不错
Document As Query:跟DSI一样,先把64个词作为query,然后接下来在全文随机中选10组,每组接下来的64个词又作为query
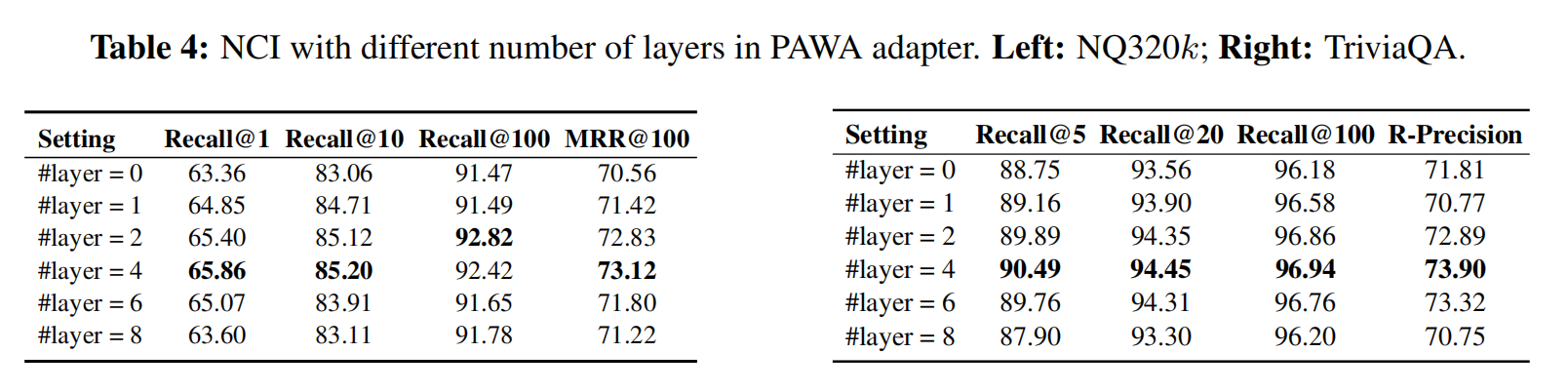
Prefix-aware weight-adaptive decoder
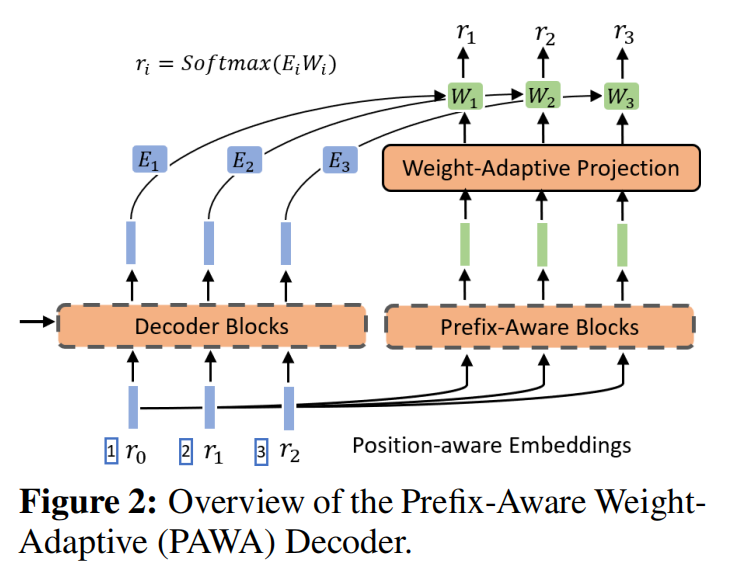
标准的decoder对时序信息感知还是不够,所以改了解码器
假设编码是 $3_15_25_3$ 的情况下,下标表示位置,不是把355丢入学习,而是变成了(1, 3)(2, 5)(3, 5),位置信息作为输入也加进去
做softmax的时候不共享W,而是根据位置的不一样选择不一样的W,而且这个W不仅和位置相关,也应该和预测相关所以做一个新的解码器
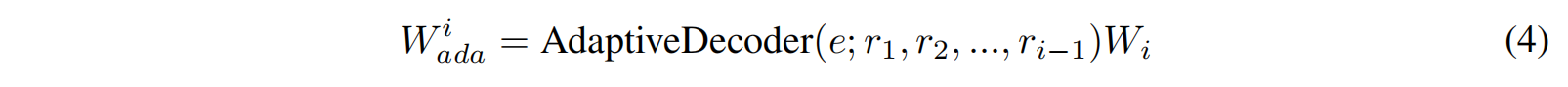
最后再拼上 $h_i$ 得到 $softmax(h_iW_{ada}^i)$
Training and inference
Consistency-based regularization
因为存在dropout等的一些随机性,所以要保证给一个query出来的 $z_{i,1}$ 和 $z_{i,2}$ 应该是尽量相似的
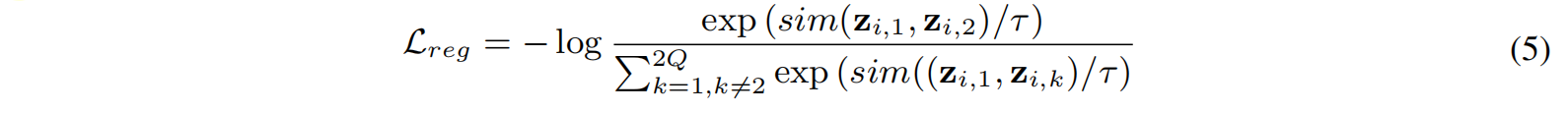
Training loss
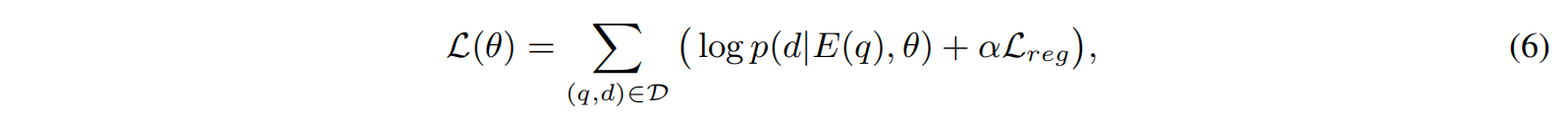
Inference via beam search
因为每次搜索的类别都是有数目限制的,所以需要限制每次束搜索的时候要在合法的docid下
Experiment
Datasets & evaluation metrics
Datasets:Natiral Questions (NQ)和TriviaQA,两个都是去wikipedia找答案返回page
Metrics:Recall @N,Reciprocal Rank (MRR),R-precision
Results
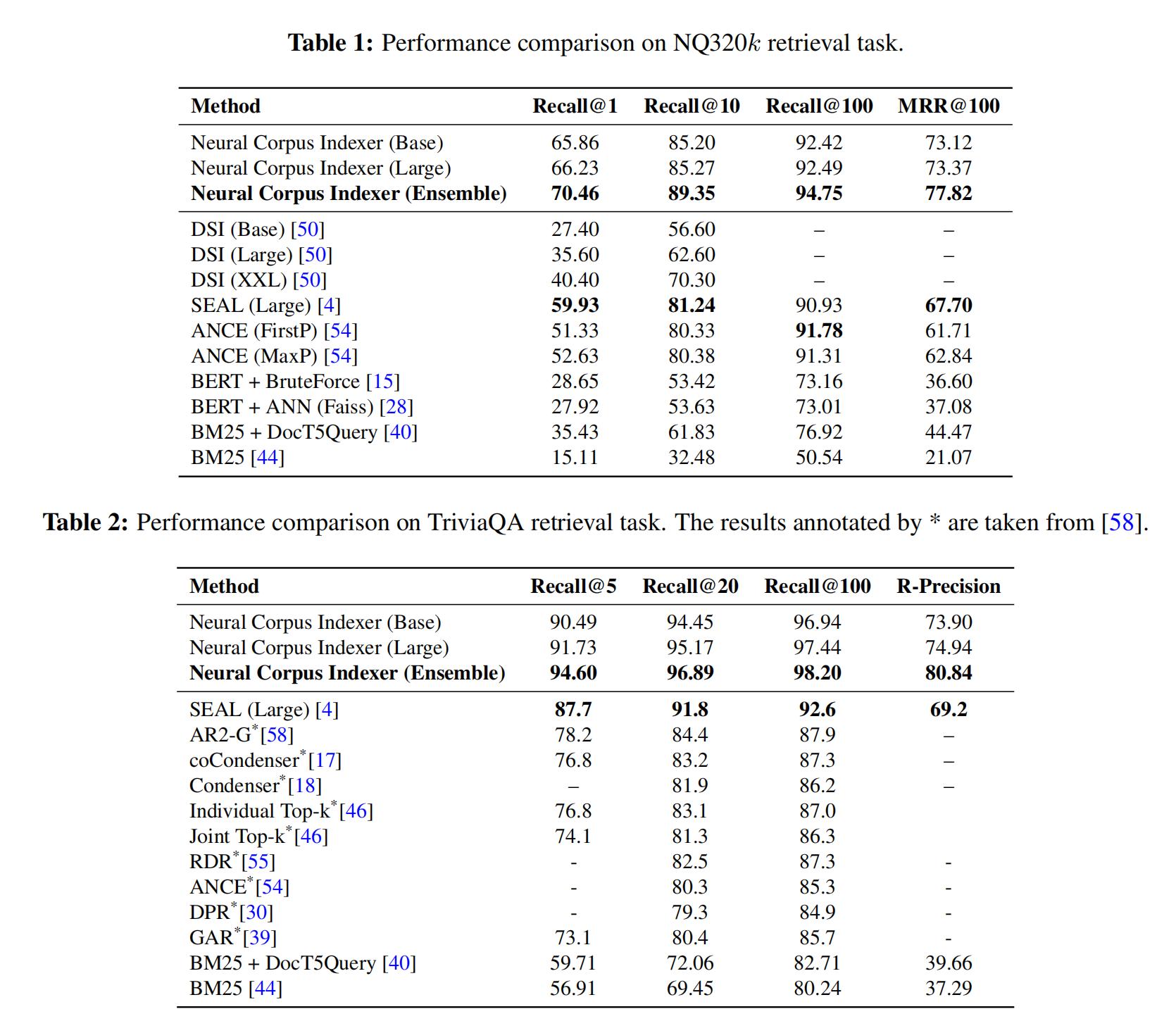
可以看到效果还是非常好的
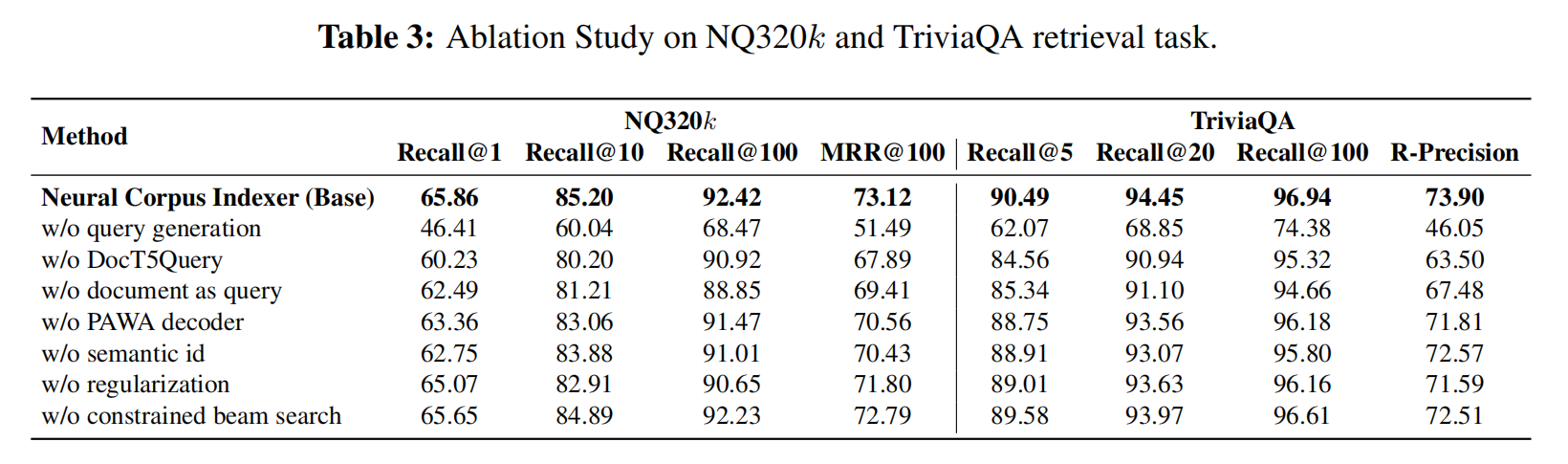
最重要的是query生成,用T5生成的query效果是最好的,提出来的解码器效果也不错的,但是层次分类和暴力的32万的分类对比发现暴力其实可能也不错,然后是对比学习的阀和对beam search做合法校验
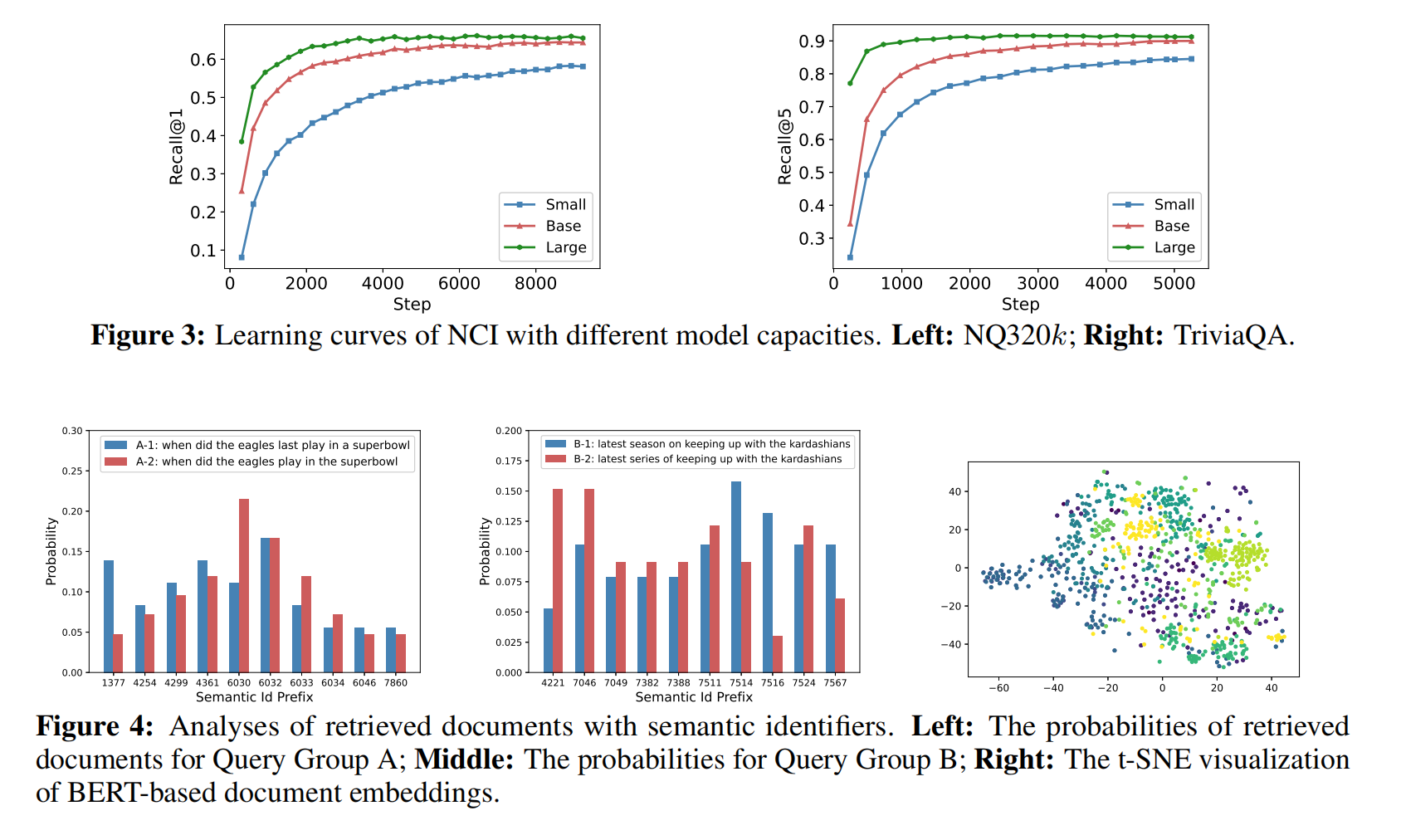
三个不同大小模型训练速度,预测稳定性
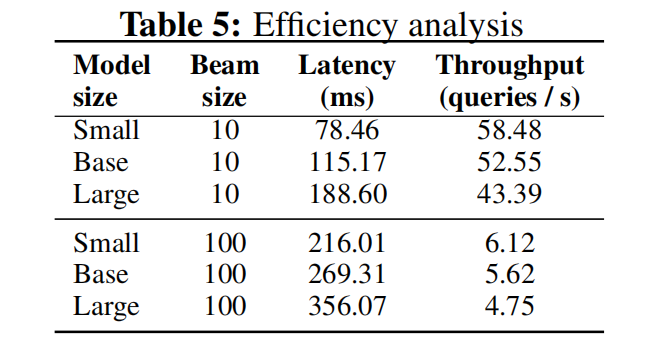
效率分析,延迟100ms还可以,但是一张v100的throughput只有五十多,就是一张卡只能处理五十多个query/s
Limitation & Future Works
- 要扩展到web scale的话需要非常庞大的模型容量
- 推理速度离能上线还是很远
- 新文档来的时候更新index困难,而且会变,模型又得重新训练,对不断增加文档得场景不适用

