DSI:可微搜索索引
Abstract
把字符串query直接映射到相关的docid,极大的简化了检索的过程,此外还研究了训练的时候document和identifier怎么表示
Introduction
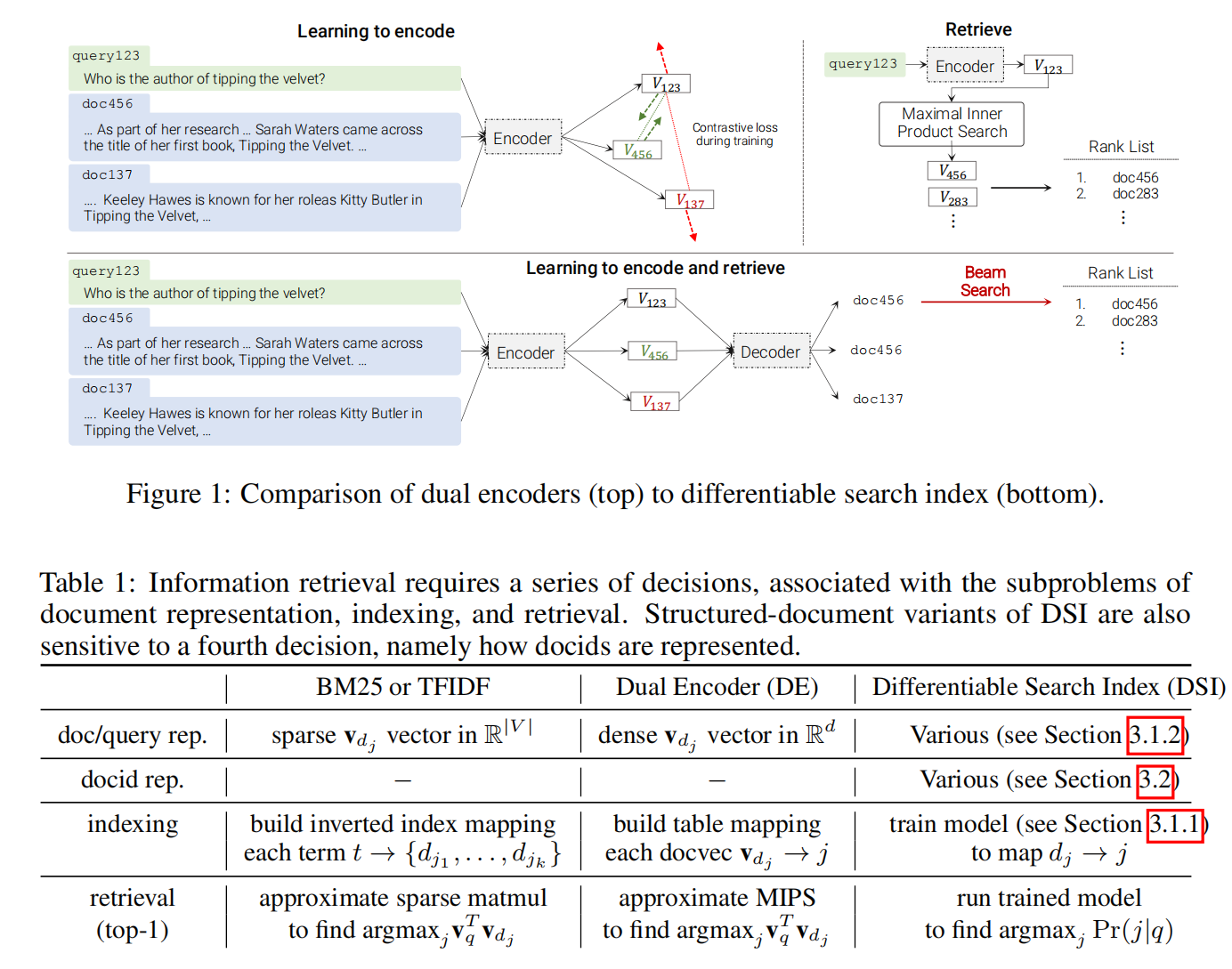
这篇文章用Seq2Seq的方法解决信息检索的问题,区别于之前的双塔模型
使用Seq2Seq做检索,最直接的思路就是给定一个query,然后通过BeamSearch生成documents。
但是这里不是完全的Seq->Seq,即直接的query->documents这样的过程。
而是这样的,分解为两个任务:documents<->docids,query->docids。其中第1个任务叫做indexing,即建立document和docid的一一映射,这个docid可以看成是document的一个缩写的摘要(可以看成一个seq2seq任务)。第二个任务叫做retrieval,这里直接根据query生成候选的docids(也可以看成一个seq2seq任务)。所以这里是一个query->docids->documents的间接的检索。
indexing这个任务主要的目的是让模型能够理解docid和document的映射关系,retrieval部分才是真正的检索。
然后indexing和retrieval这两个任务训练的时候,模型参数共享(不然模型可能无法理解docid的含义),使用多任务学习的方式同时进行。
Differentiable Search Index
可谓搜索索引(DSI)的核心思想就是将传统的多阶段的检索-重排的流水线使用一个模型进行参数化。为了实现这一点,DSI支持两种操作:
索引:一个DSI模型必须学会将一个文档 的内容和对应的文档标识docid给联系起来。这篇文章直接使用一个seq2seq模型,把文档内容作为输入,把标识符作为输出。
检索:给定一个查询,一个DSI模型应该能够返回一个排序的候选docids列表,这是通过自回归的生成实现的(也是seq2seq)。
Semantically Structured Identifiers
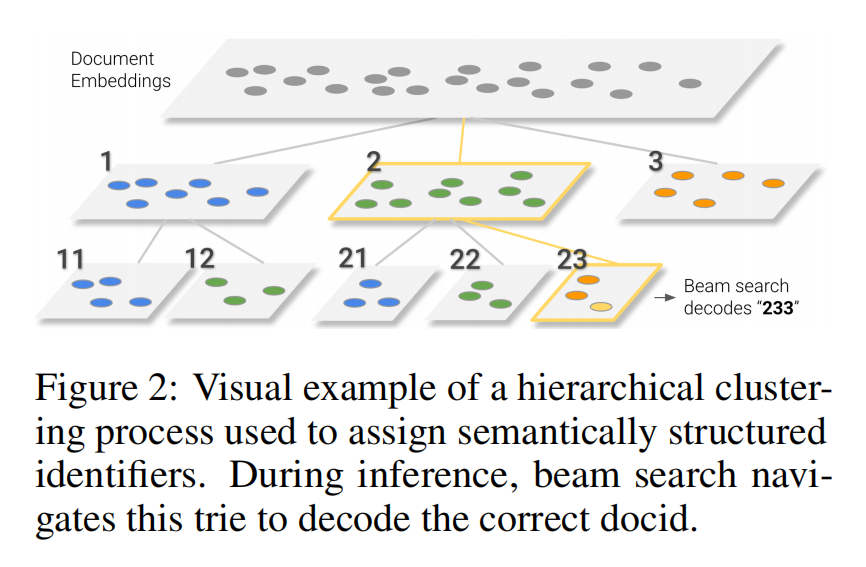

对文档的标识符不使用随机的整数,而是使用有一定规律的整数,即语义结构化的标识符。具体的,给定一个要被索引的语料库,所有的文档被聚类为10个集群。每个文档都被分配一个标识符,其编号分别为0到9。然后对于每一个集群,按照上面的方式递归处理,即,又划分为10个集群,每个集群标号为0到9。对于少于10个比如c个文档,那么赋予编号0到c-1。然后通过这样做,就可以得到一个树,树的叶子结点就是一篇文档,文档的最终标识符就是从根节点到当前结点的路径对应的编号组合
然后上面涉及到一个对文档的聚类,这里使用的是无监督的方法,即提取文档的BERT表示,然后通过k-means进行聚类。
这里超参要定每次要聚10个类,阈值c定的100,超过100继续聚类
Experiments