论文地址:Training language models to follow instructions with human feedback
InstructGPT:GPT-3+RLHF
Abstract
把语言模型变大并不意味着模型会更好的按照用户意图执行,容易生成不真实的,有毒的或没有帮助的答案,模型和用户没有align在一起。所以要把人类意图和模型做align,具体做法就是用人类反馈来做微调,先用一堆标注写好的prompt和提交到OpenAI的API上的prompt及其人工得到答案构成数据集,对GPT-3做微调。还收集了一个模型输出排序的数据集,用强化学习继续微调训练最终得到模型InstructGPT。这样1.3B的InstructGPT模型比175B的GPT-3更好,能够显著降低有毒的,不真实的情况,在公开数据集上没有变差
Introduction
大模型能够提供prompt方法把提示作为输入,但也可能生成一些不想要的行为比如捏造事实,生成有毒文本,或是根本没有按用户要求。这可能主要是因为训练的目标函数不太对,比如用的预测下一个token的方法和我们需要的要模型按人的指示来生成有帮助的安全的答案是不一样的,这就是语言模型的目标函数misaligned
最终需要的目标是让语言模型更加对解决问题有帮助,不要捏造事实的真诚,也不要有害
具体用的是人类反馈的强化学习(RLHF)
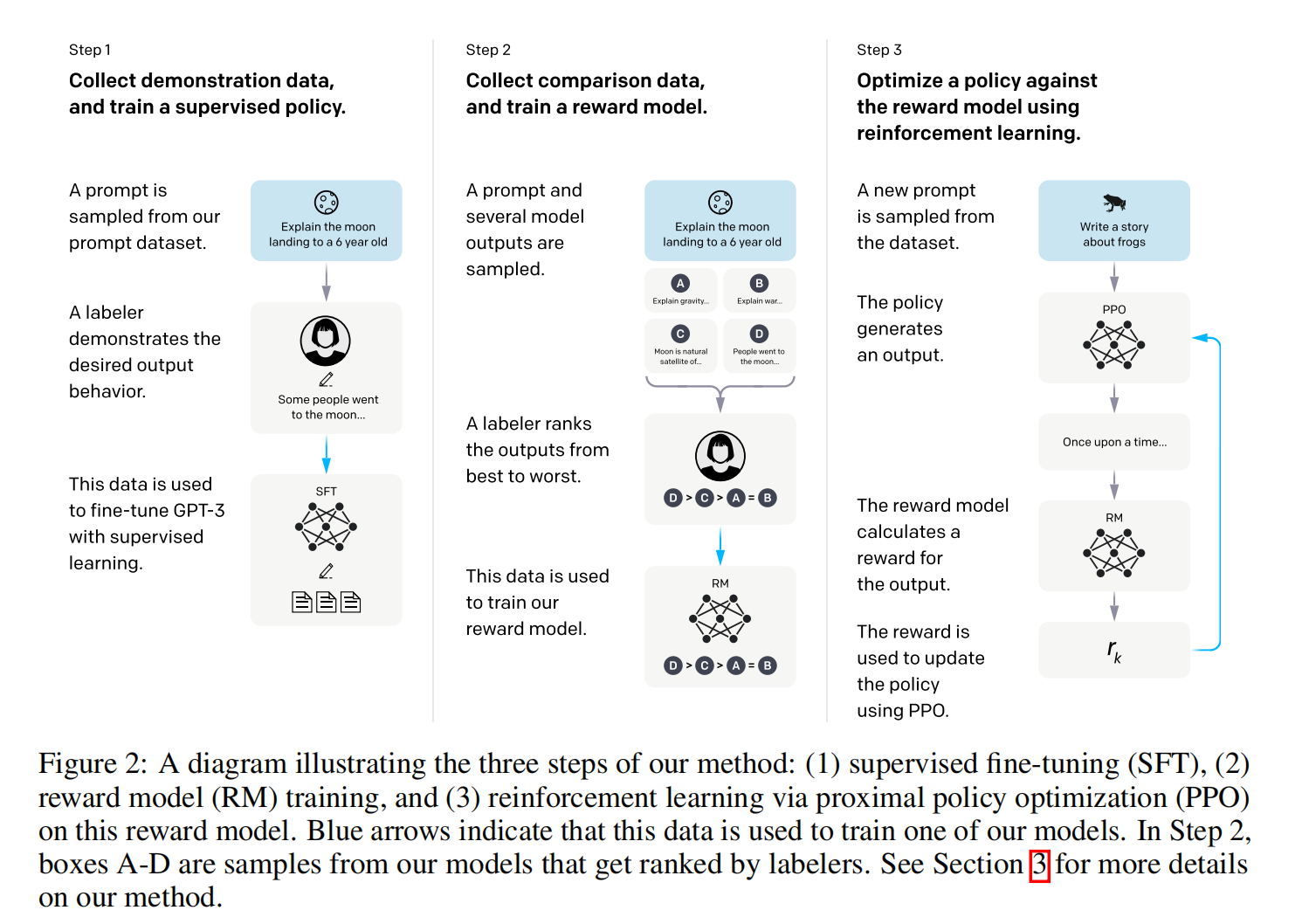
- 第一步:采样选择一些提示,标注工给出期望答案,用有监督方法来微调GPT-3,但生成式标注很贵
- 第二步:采样提示生成答案,人标注答案打分,训练一个奖惩模型
- 第三步:根据RM模型打分结果继续优化SFT模型
主要发现如下:
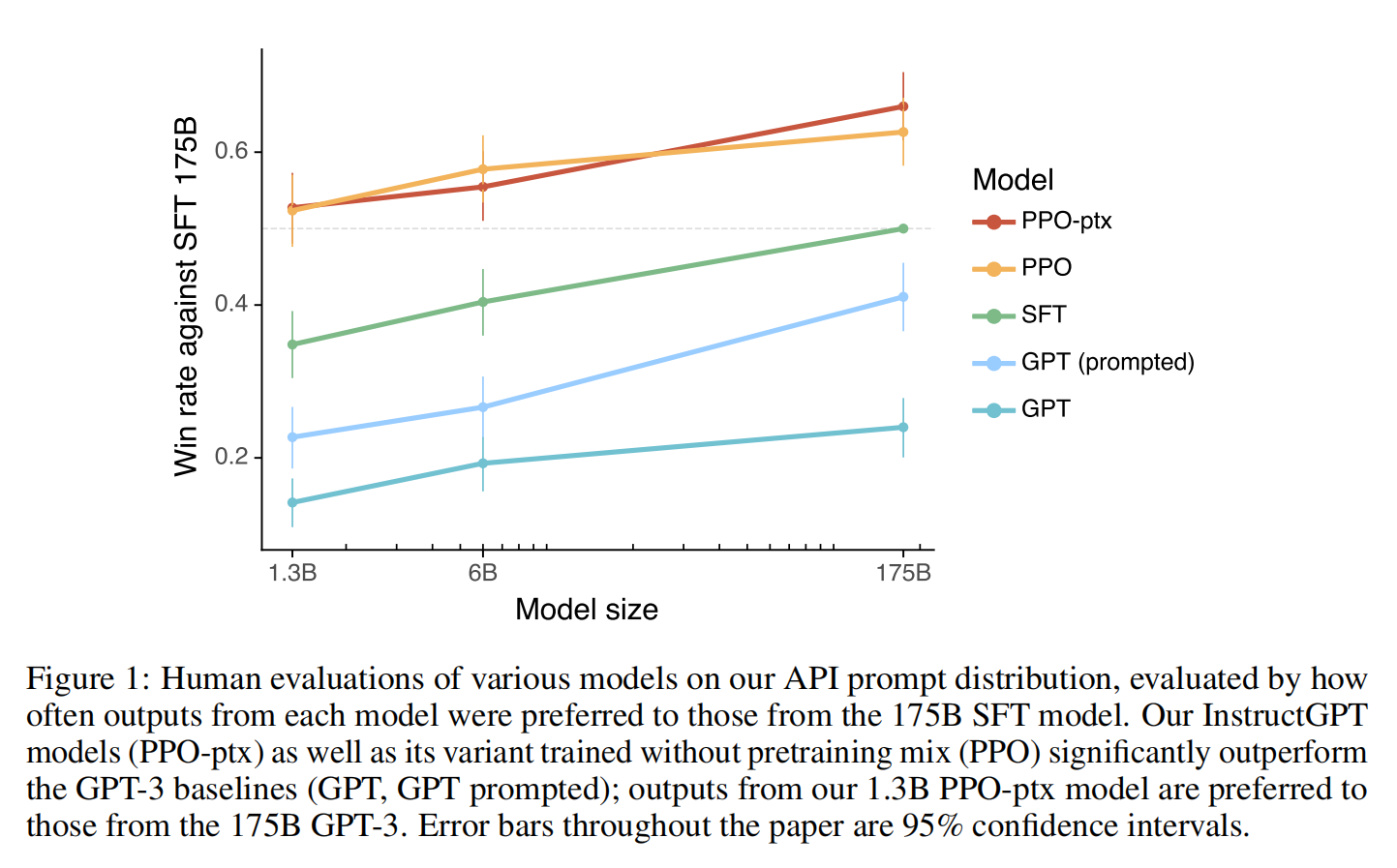
- 标注工认为InstructGPT比GPT-3输出更好
- InstructGPT比GPT-3更真实
- InstructGPT比GPT-3有毒文本更少
- 把原本目标函数还是用在了InstructGPT,避免在特定QA上微调后在其他任务上性能下降
- 标注数据有主观性,找了一些held-out的标注人员,没有参与标注数据,只是对结果进行评估,仍然认为InstructGPT比GPT-3更好
- 在共有数据上微调发现还是自己数据好,微调对数据还是比较敏感的
- 不可能把所有问题标注出来,但模型还是表现出一定的泛化性
- InstructGPT还是会犯一些简单的错误
Methods and experimental details
Dataset
标注工写了很多提示,包括plain:随便写任何问题,few-shot:带有指令的及其后续查询/回答对的,user-based:有很多OpenAI API里面的应用的用例。用这些数据训练了第一个instruct模型,然后放到一个playeground让大家用,采集反馈的问题,再做一些限制比如每个用户采200个prompt,按照用户来划分训练,测试,验证集,这样得到了更多的prompt
基于这些prompt构建了三个数据集:
- 标注工直接写答案训练SFT模型,13k训练样本
- 训练RM的数据集,33k训练样本
- 训练强化微调模型的PPO数据集,31k

models
Supervised fine-tuning (SFT)
在GPT-3上做微调16个epoch,其实一遍就过拟合了,但因为这个是作为后面模型的初始化,所以过拟合也没关系
Reward modeling (RM)
把SFT模型后面的unembedding layer去除,不用softmax而是在后面加一个线性层来投影到一个值上(输出为1的线性层)
使用的是6B的RM,175B会训练不稳定loss炸掉
把排序换成值用的pair-wise ranking loss
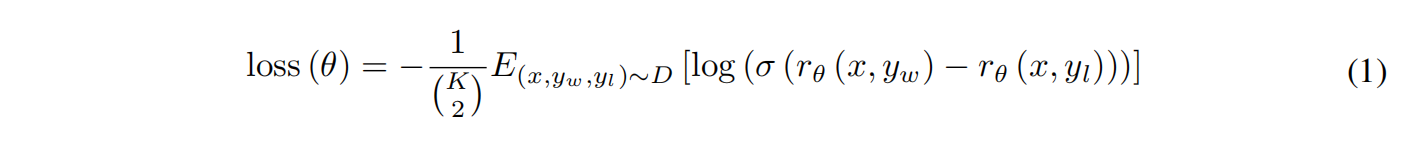
其中 $r_{\theta}(x,y)$ 是reward model的输出,前者比后者奖励分数高,这里k=9,也就有 $C_9^2=36$ 项组合,但只用算9次前向或反向,所以k越大省计算开销越多
Reinforcemnet learning (RL)
强化学习环境用的PPO
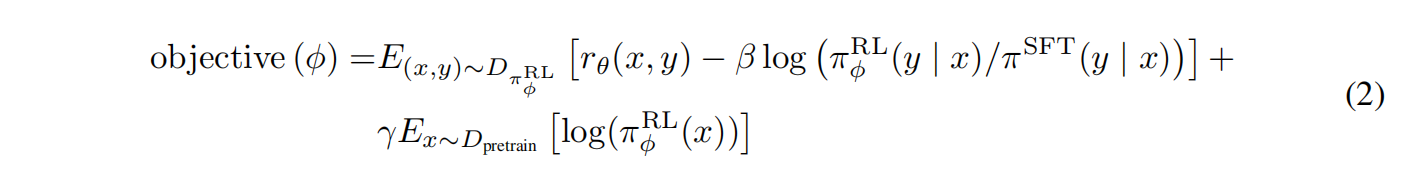
策略或是当前的状态是模型,要做一些action
$\pi_{\phi}^{RL}$ 是要学习的模型,$\phi$ 是学到的超参,$\pi^{SFT}$ 是有监督训练得到的模型,最开始用来初始化要学习的模型 $D_{pretrain}$ 是预训练的数据分布。x是不变的,采样到的y随着模型的更新会不同,数据分布随着模型更新发生变化,$r_{\theta}$ 就是学习一个人的排序来得到一个实时反馈
第二项是正则化项,不希望模型更新变化过大,加一个KL散度,$\beta$ 控制KL散度的惩罚
第三项是语言模型原本的目标函数,$\gamma$ 控制是否偏向原始数据,前两项在新的数据集上做拟合,但原始数据也不要丢,$\gamma$ 不等于0就是PPO-ptx
Results
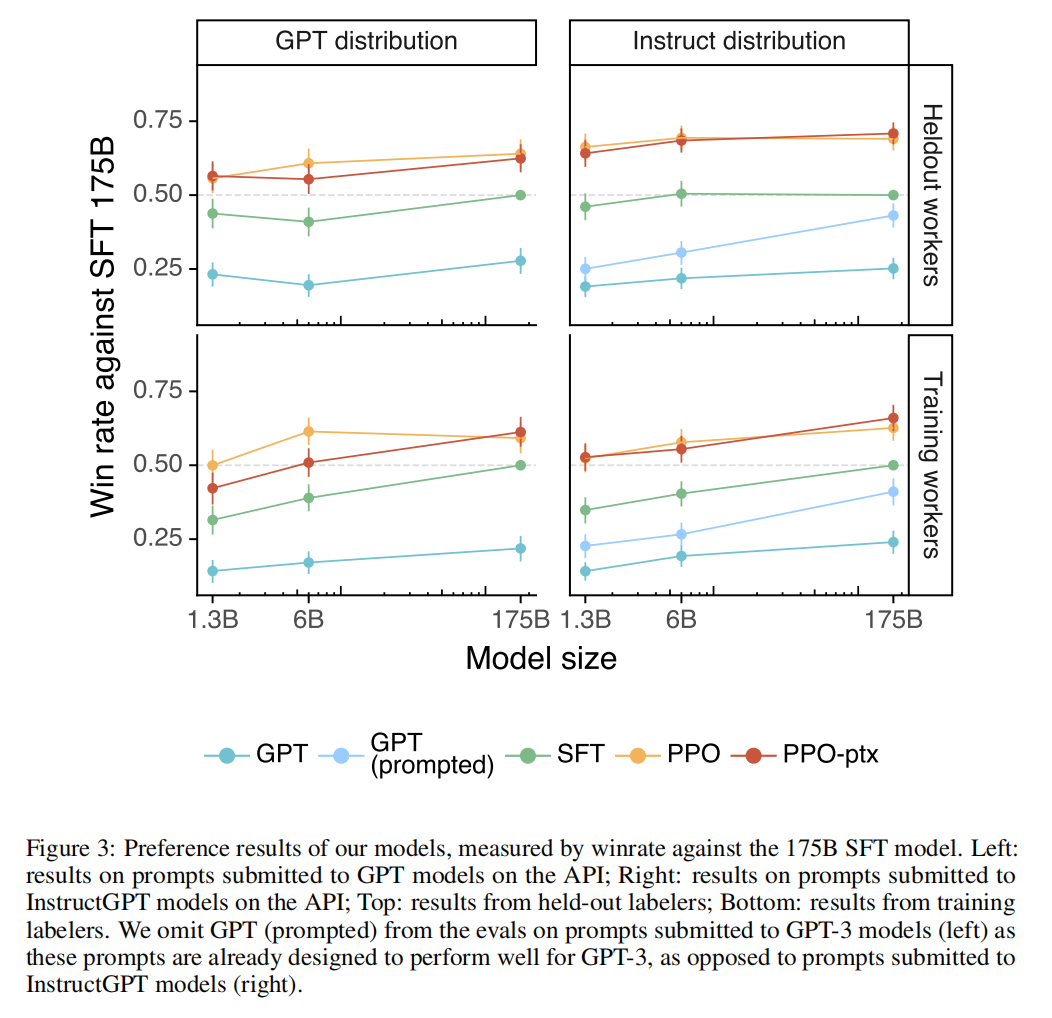
Discussion
Implications for alignment research
model alignment相对于预训练的代价是比较低的,因为样本少
Limitations
标注数据是40个合同工,以及90%数据都是英语,模型上面也不是完全安全,以及到底该align到什么程度

