BLIP:ALBEF+VLMO+captioner+filter
Abstract
BLIP通过引导字幕来有效地利用有噪声的网络数据,其中captioner生成合成字幕,filter去除有噪声的字幕,用更干净的数据训练出模型
Introduction
现存的方法主要有两个局限性:
- 模型角度:现有方法用transformer encoder,或是encoder-decoder结构。这个encoder only的模型没法直接应用到文本生成的任务;而encoder-decoder的模型没有统一的框架不能直接做image text retrieval任务
- 数据角度:都是大规模的网上爬下来的image-text对,把数据集变大是有好处但不是最优解,所以提出了一个captioner和filter
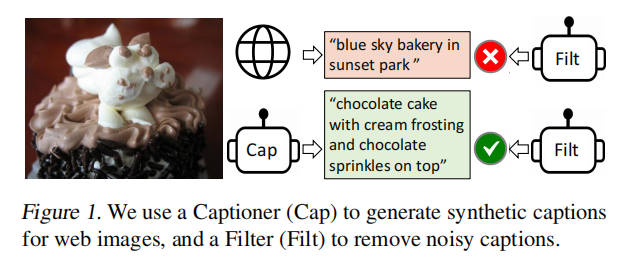
爬下来的网络数据有大量噪声,一个captioner module生成字幕,filter选择用哪个文本数据进行训练
Method
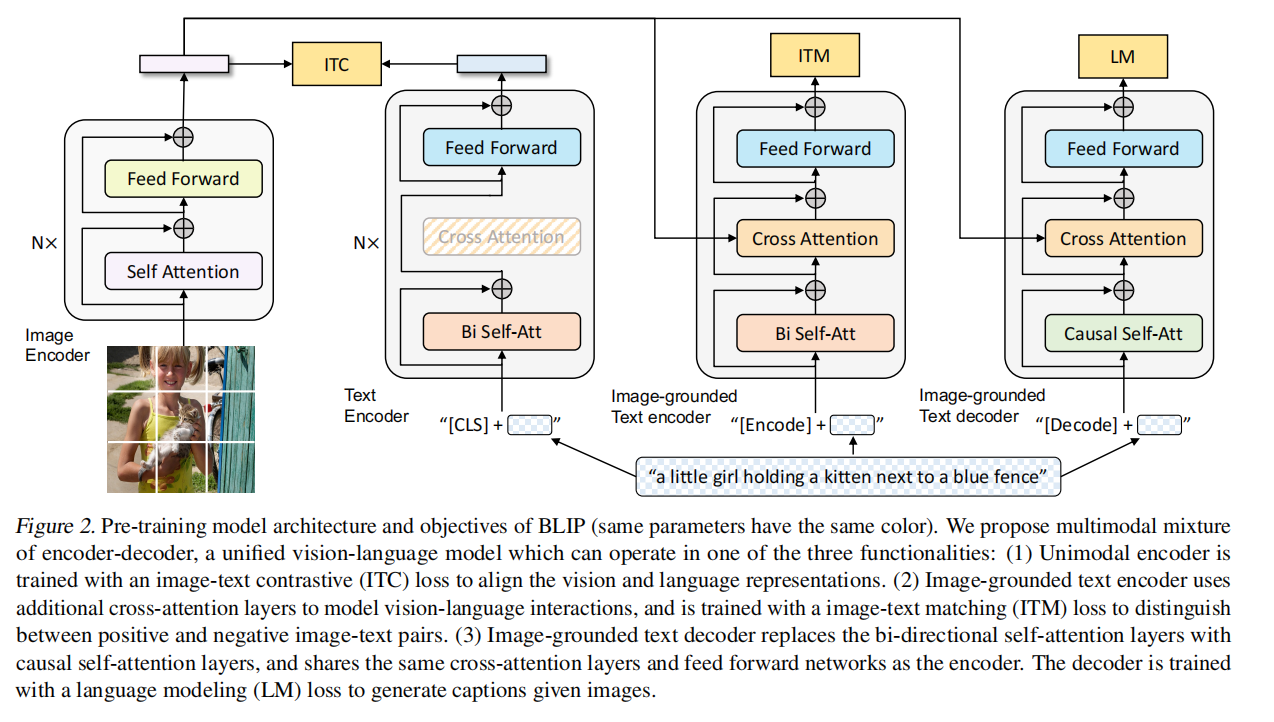
图像一个VIT编码器,文本三个模型算三个目标函数,把编码器解码器混在一起叫MED模型,其中同样的颜色同样的参数
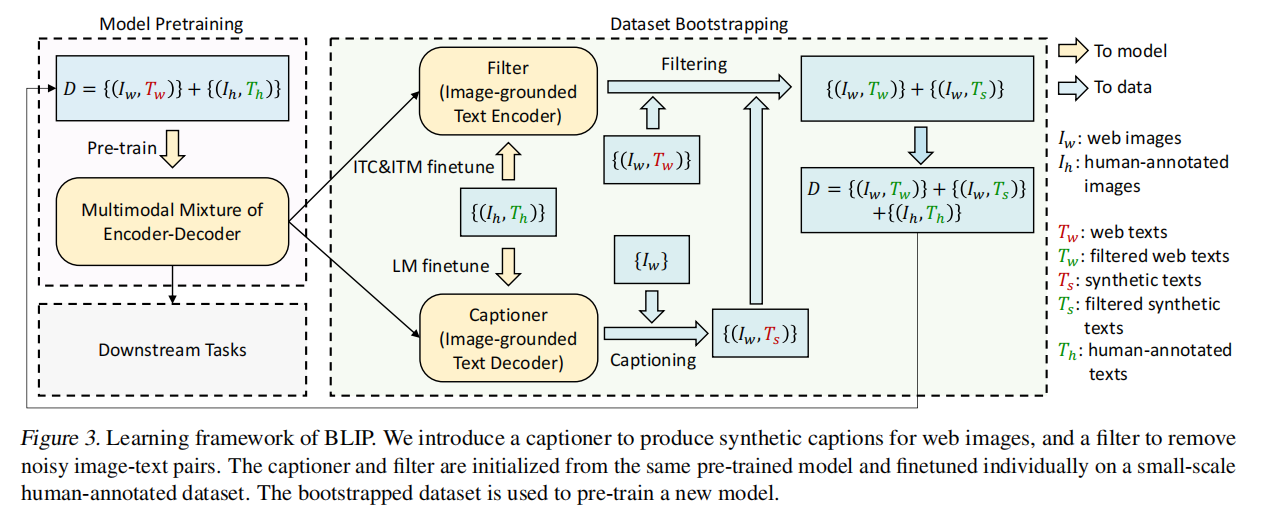
数据集D有网上爬下来的 ${(I_w,T_w)}$ 和手工标注的 ${(I_h,T_h)}$ ,最大的问题是爬下来的数据集有图片文本不匹配的,用红色表示,绿色就是匹配
把已经训练好的MED模型部分拿出来在干净的数据集上微调,ITC&ITM微调得到Filter,LM微调得到Captioner,captioner合成的数据再丢给filter得到干净数据集;最终的数据集就是过滤的,合成的和现实有的
Experiments and Discussions
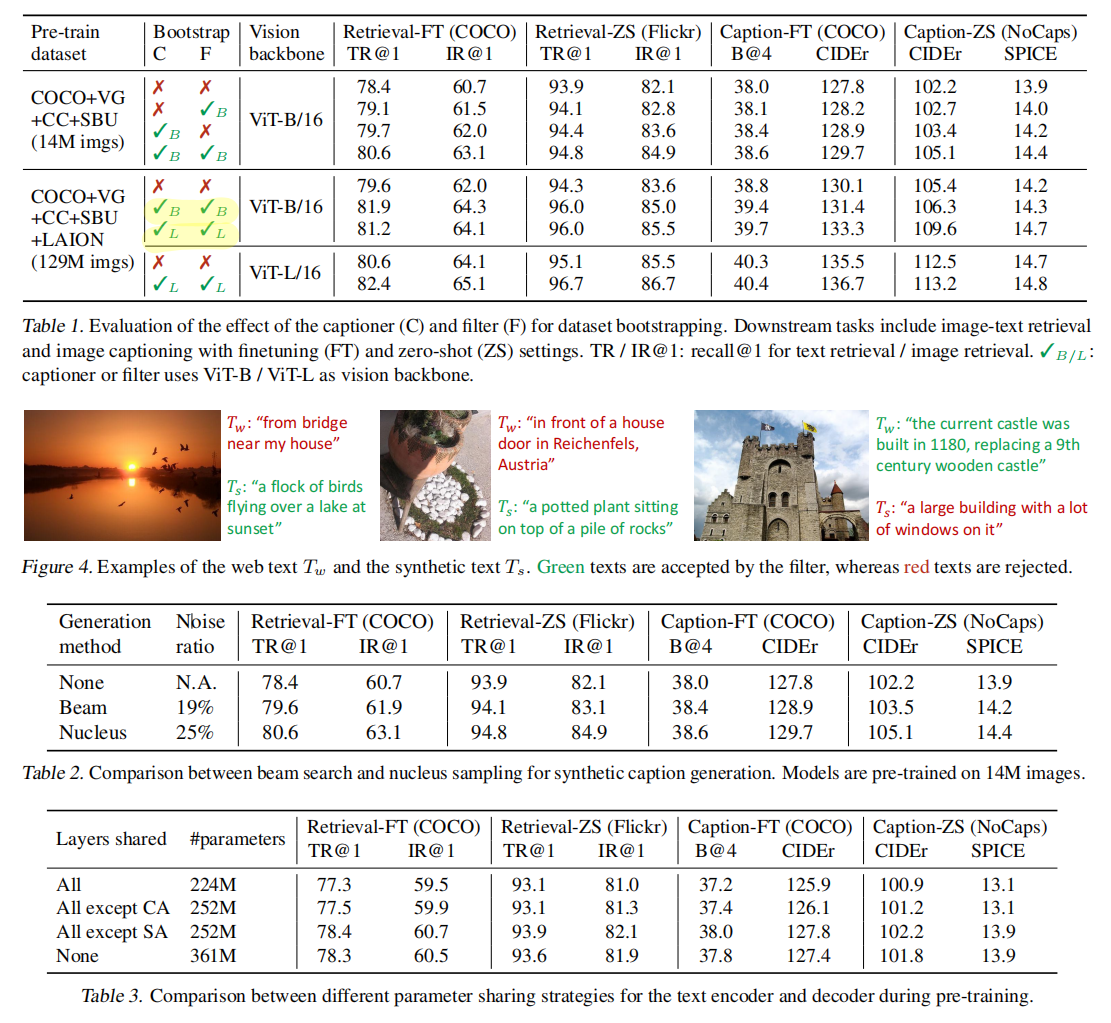
表1看到模型变大或数据大都能够得到更好的结果,用了captioner和filter效果很不错,而且用captioner和filter不一定模型是base就用base设置,也可以用large的模型来做captioner和filter,是一个比较通用的工具
生成的数据有好有坏,但是过滤比较强大,能够挑出更匹配的

