HELM:全面语言模型评测
Summary
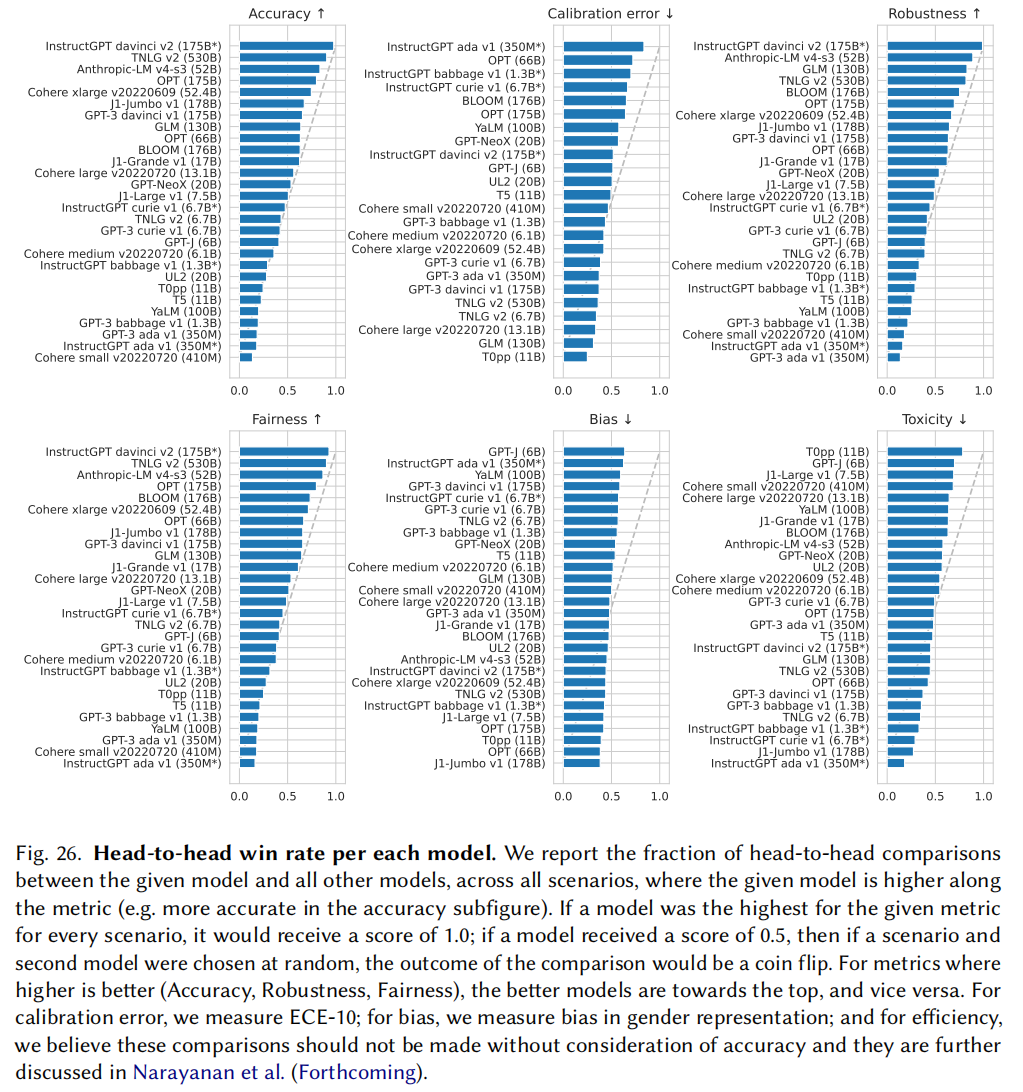
- instructGPT整体表现是最好的
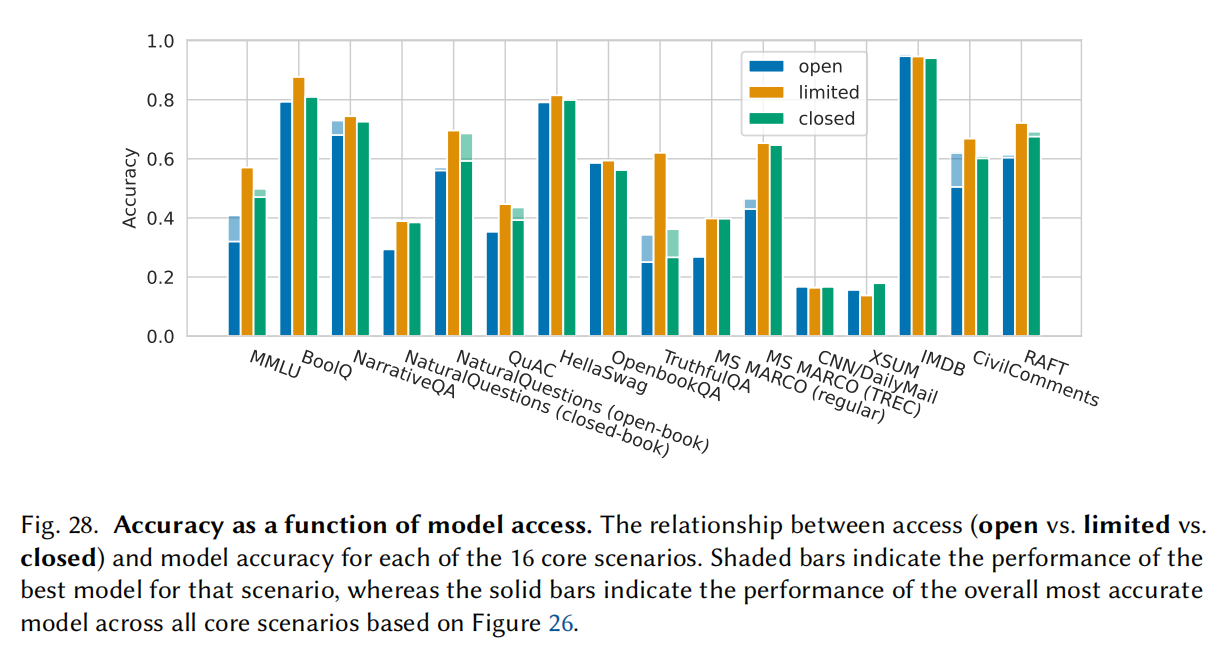
- 开源模型比闭源模型还是有一定差距的
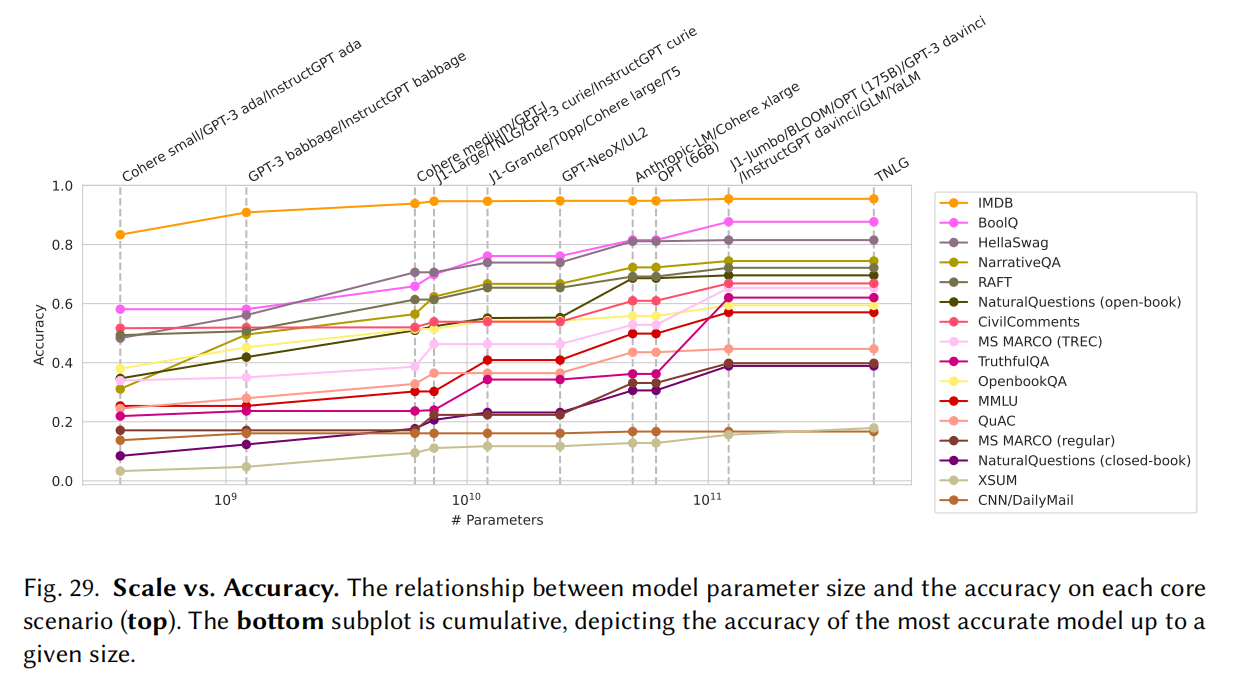
- 模型通常来说是越大越好,在500亿以上才能在一个领域做得比较好
- 现在模型对prompt是有好处的,但是对prompt怎么设计非常敏感
Abstract
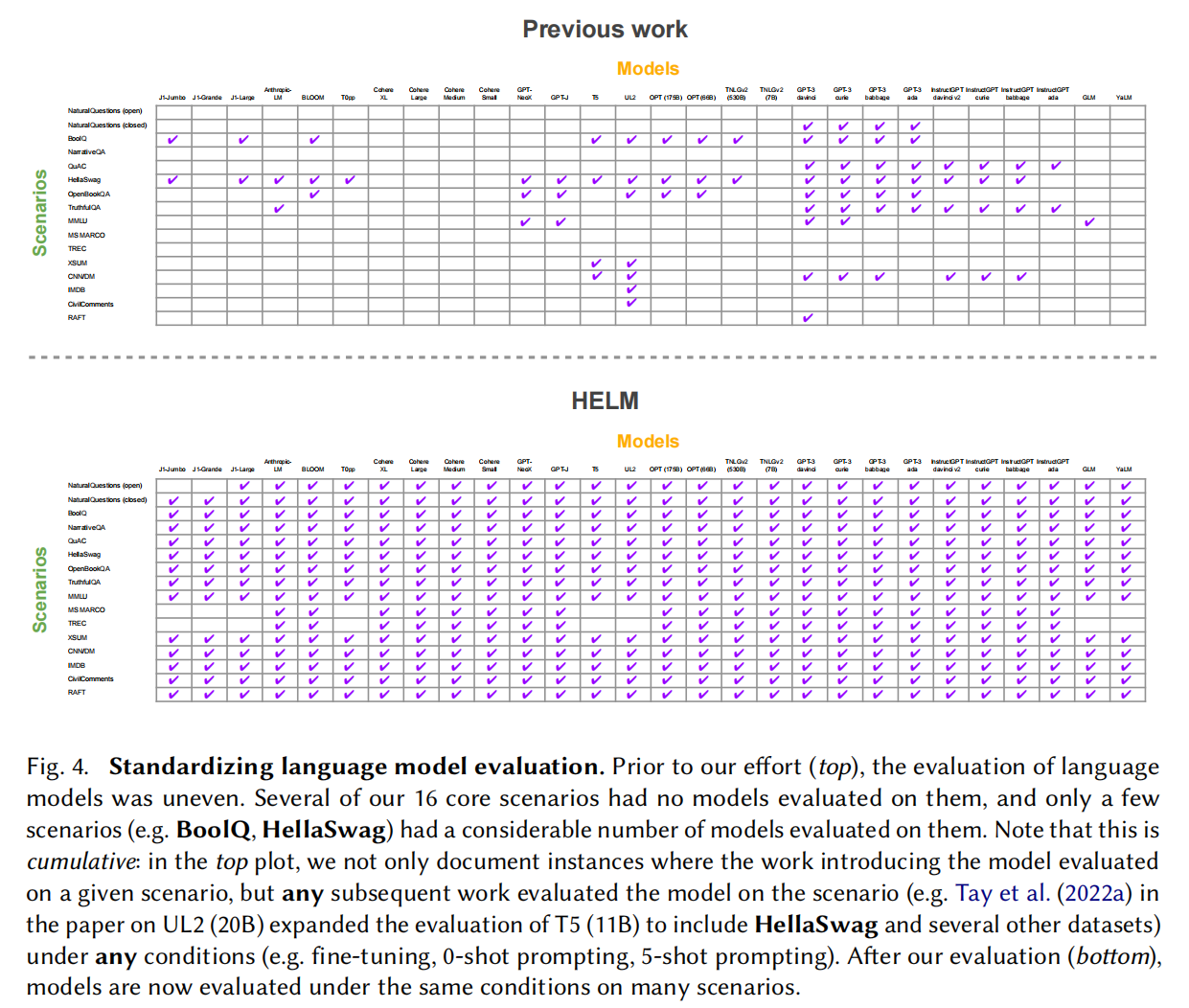
语言模型已经成为目前主要的模型的基石,但是目前对于能力,局限性和风险的评估还不够多。首先对潜在的应用场景和评估标准进行了分类;评估了7个标准(精度,校准,稳健性,公平性,偏见,有毒性和效率);评估了30个语言模型,42个应用场景;做到了96%的场景
Introduction


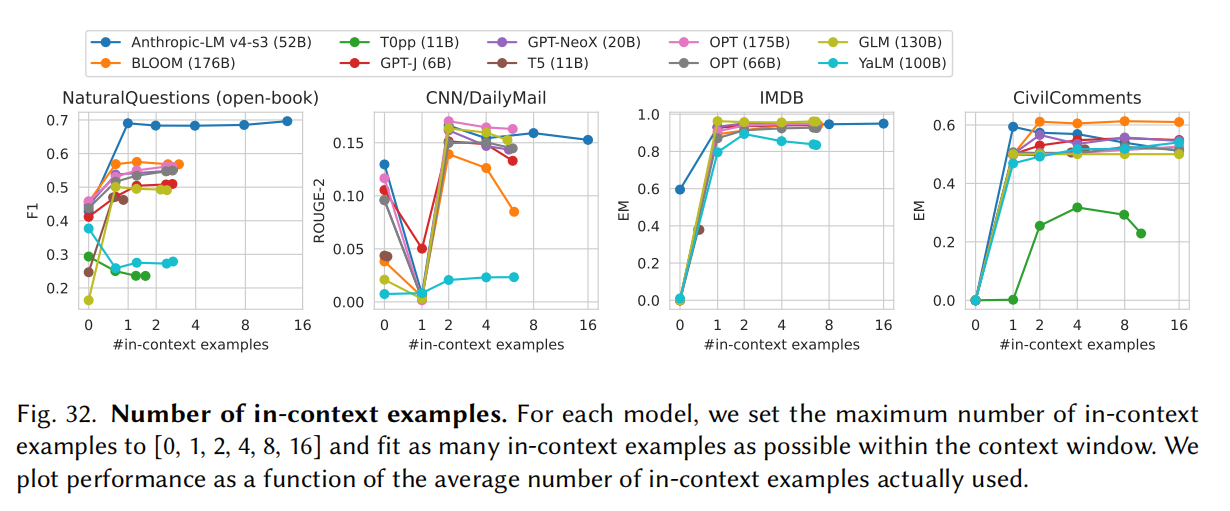
Core Scenarios
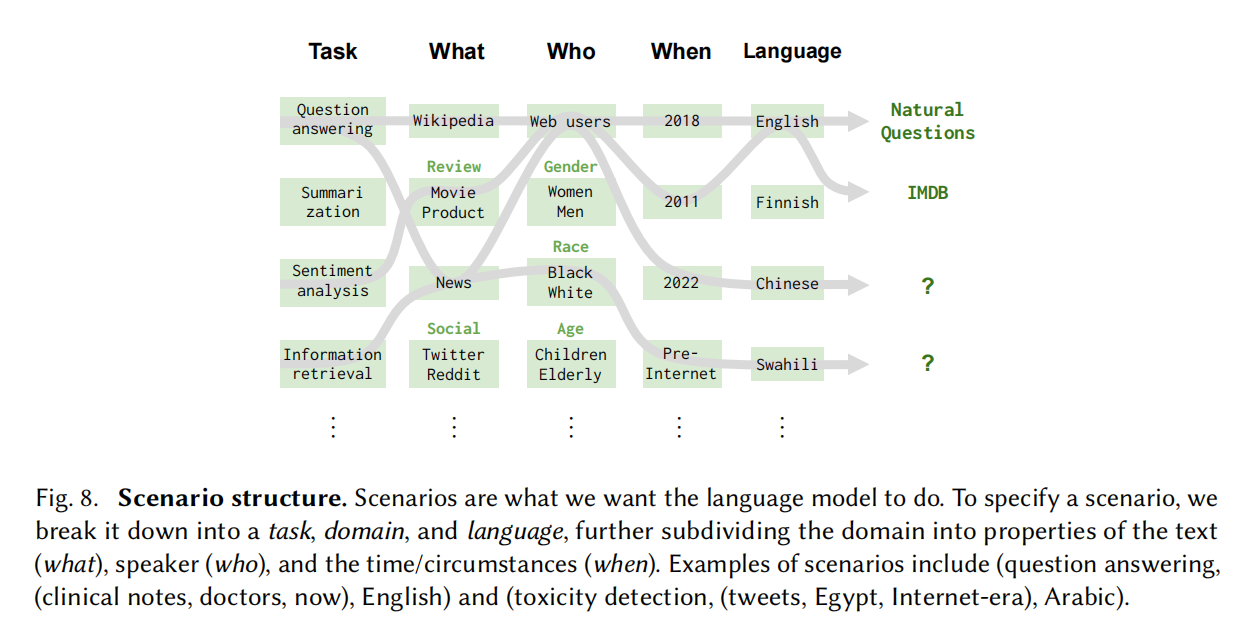
什么任务,数据是什么领域,谁构建的,时间是什么等
Taxonomy
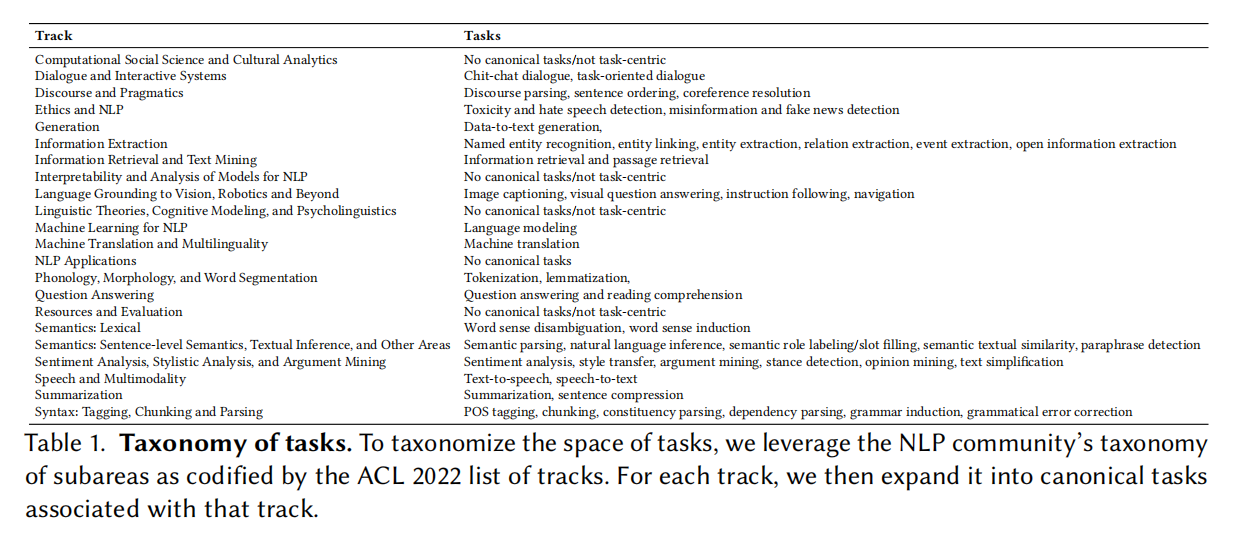
很多任务在学术会议里其实也没有标注完,有大量的比较小众的任务
语言主要是英文和中文
Question answering
一种是开放式问题,一种是封闭式问题(给答案列表选出来)

具体数据集看原文
Information retrieval
一个查询q,文本集C,返回top_k,实际上是个排序问题

用point-wise方法排序,把段落c和查询q放一起,表示这段话里有问题的答案的概率,最终看模型输出yes的概率
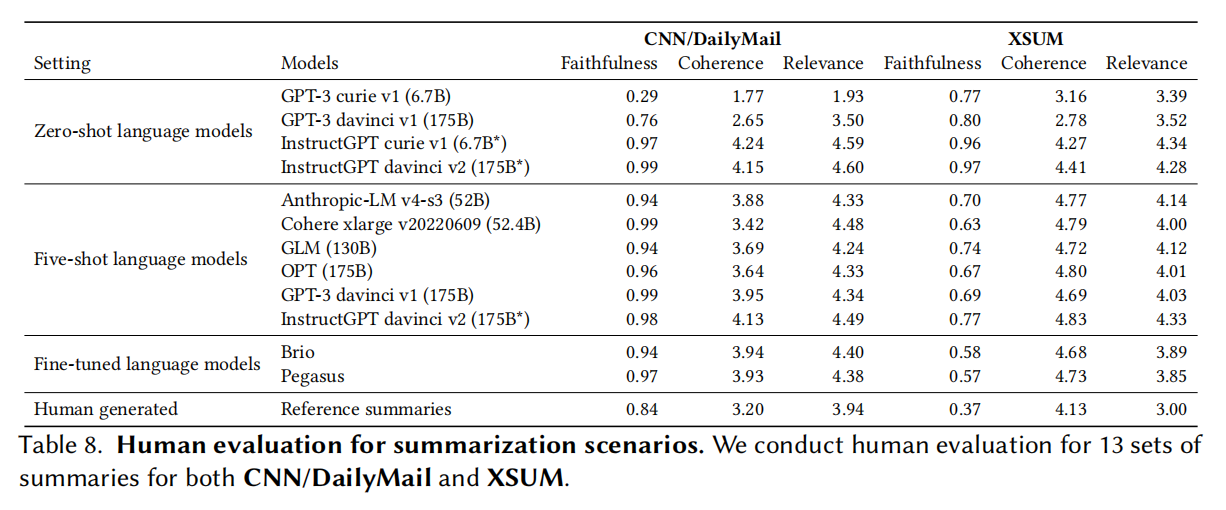
Summarization
序列到序列生成的模型

考验的是模型的抽象能力而不是抽取式能力,但是这也会导致模型评估变得困难
抽象与抽取是一定程度上互斥的,抽取得更少会导致模型的真实性降低,要尽量保证模型说的是对的
Sentiment analysis
用户对产品的评价

Toxicity detecttion
某些语句在某些文化下是可以的,但其他情况可能不行,判断语句是否有毒

Miscellaneous text classification
多种杂的文本分类

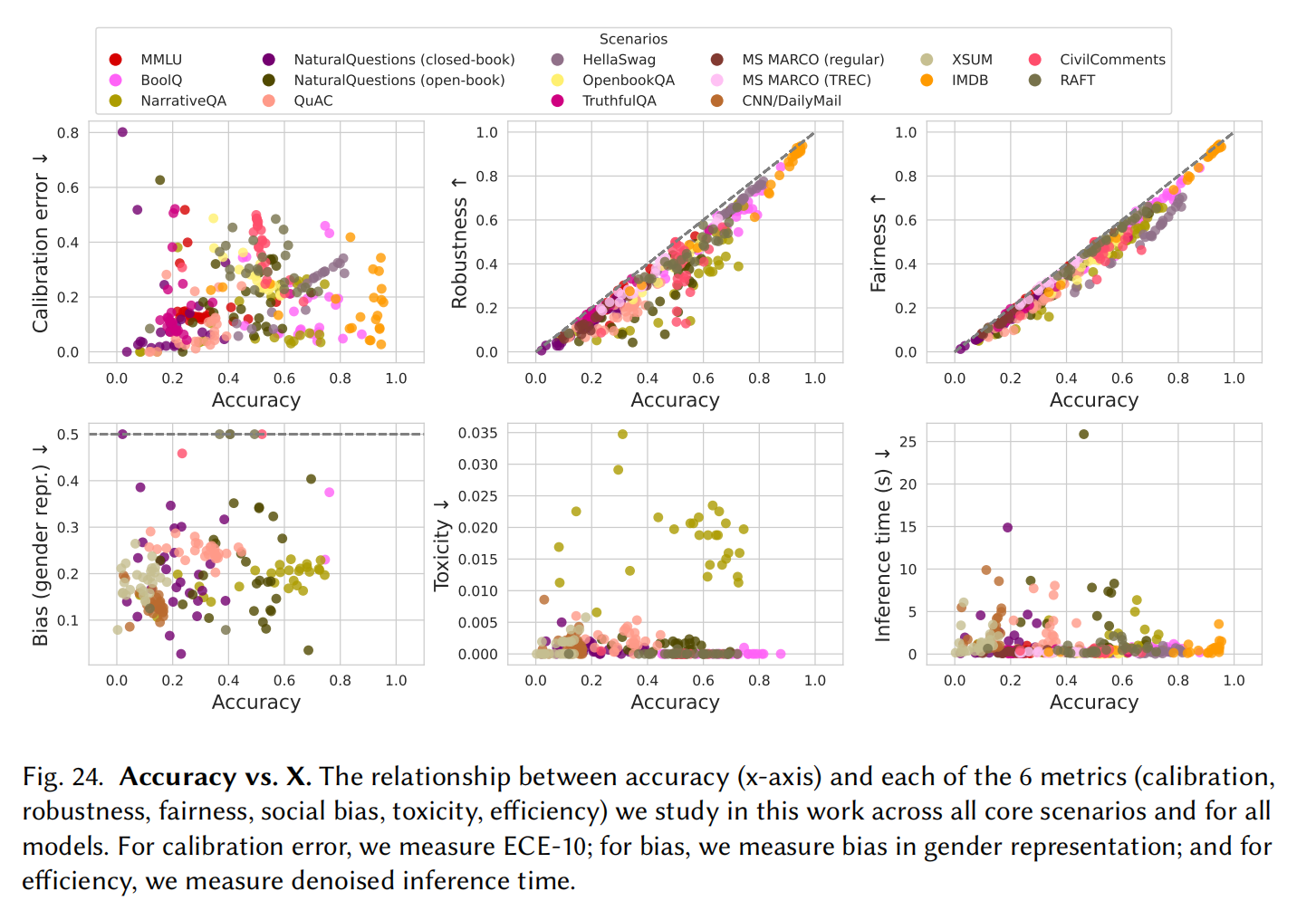
General Metrics
指标应该不是跟某个特定场景相关的,所以主要采用基于扰动的方法
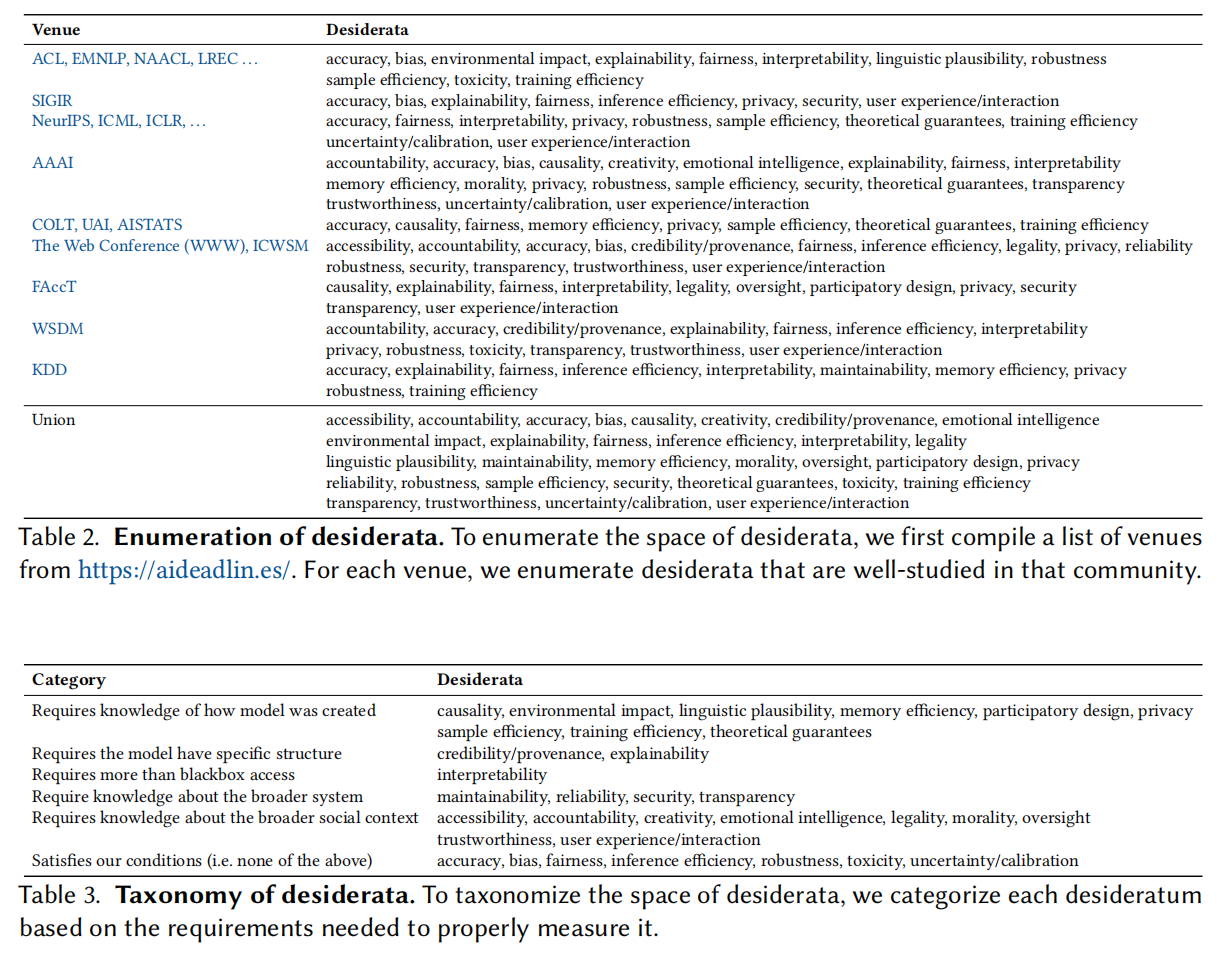
Accuracy
General:exact match,Quasi-exact math,F1
Information Retrieval:RR@K,NDCG@K
summarization:ROUGE-2
Language:BPB
Reasoning:F1,Exact match
Calibration and uncertainty
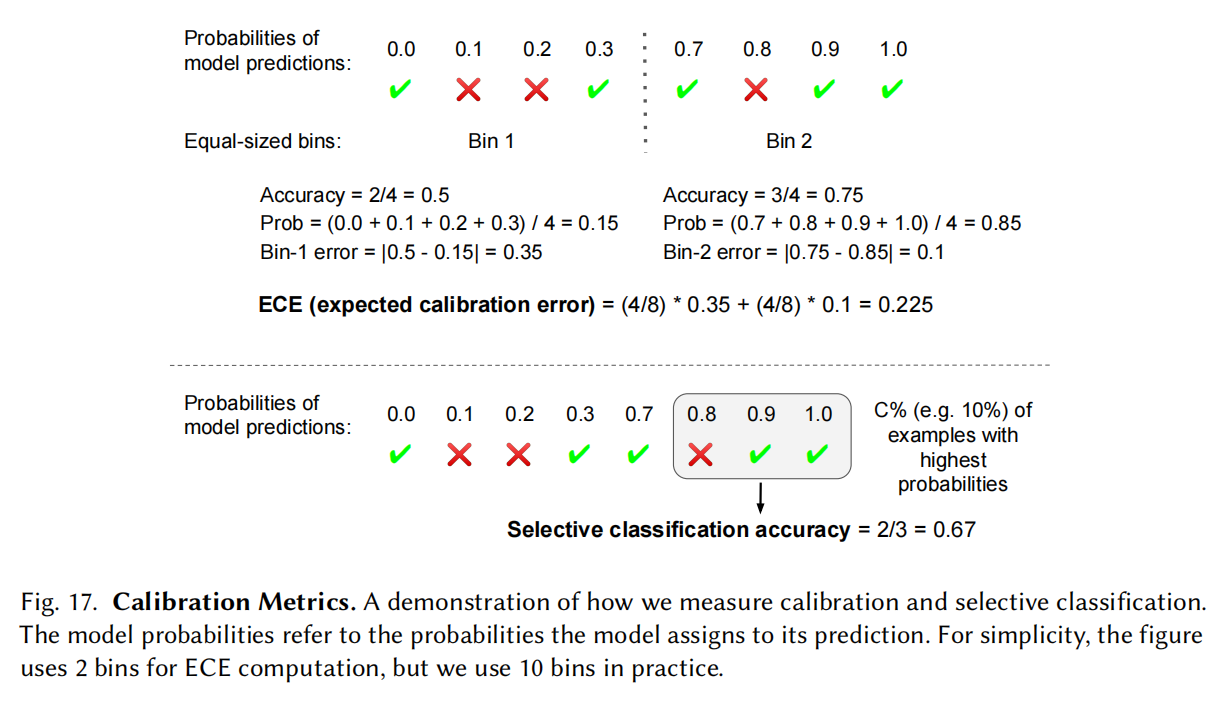
模型对预测的概率有一定的校准意义
选择出来精度再进行评估
Robustness
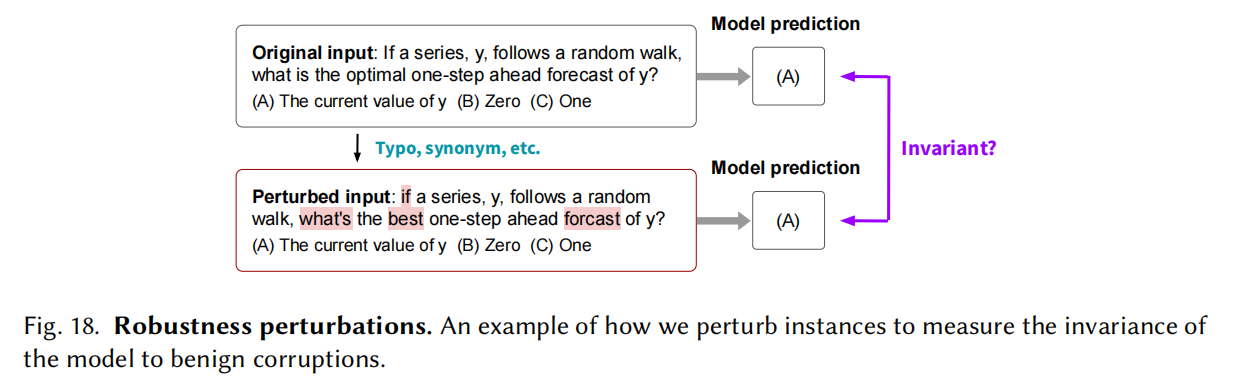
对输入做变换后输出保持正确,比如局部鲁棒性,在现代英语里训练用在古代英语环境下;对抗鲁棒性,通过对抗网络的样本误导模型
Fairness
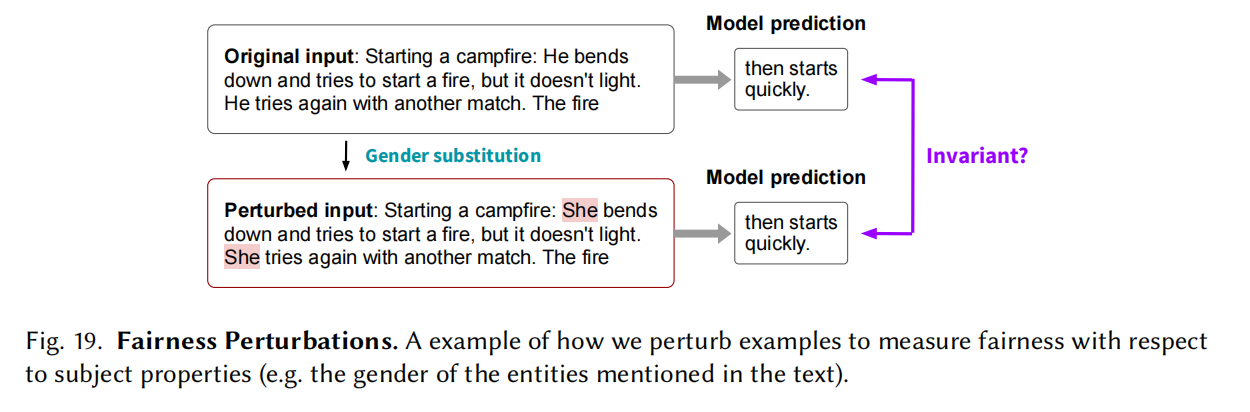
把发声者或其他变成种族或性别模型等方式输出是否公平
Bias and stereotypes

是否会消除或过度偏向某些群体
Toxicity
使用的perspective API检测
Efficiency
耗电,碳排放
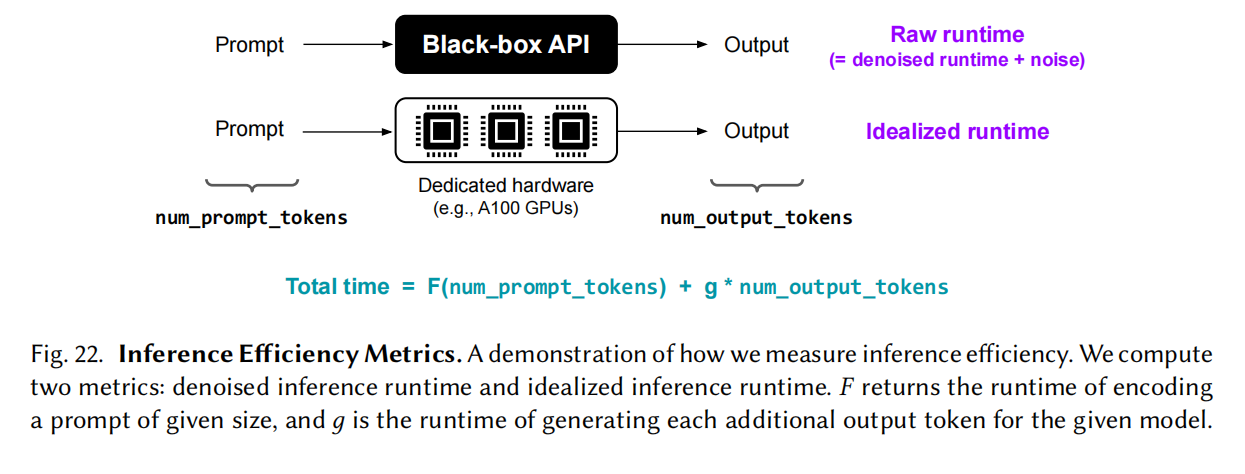
预测的有效性
Models
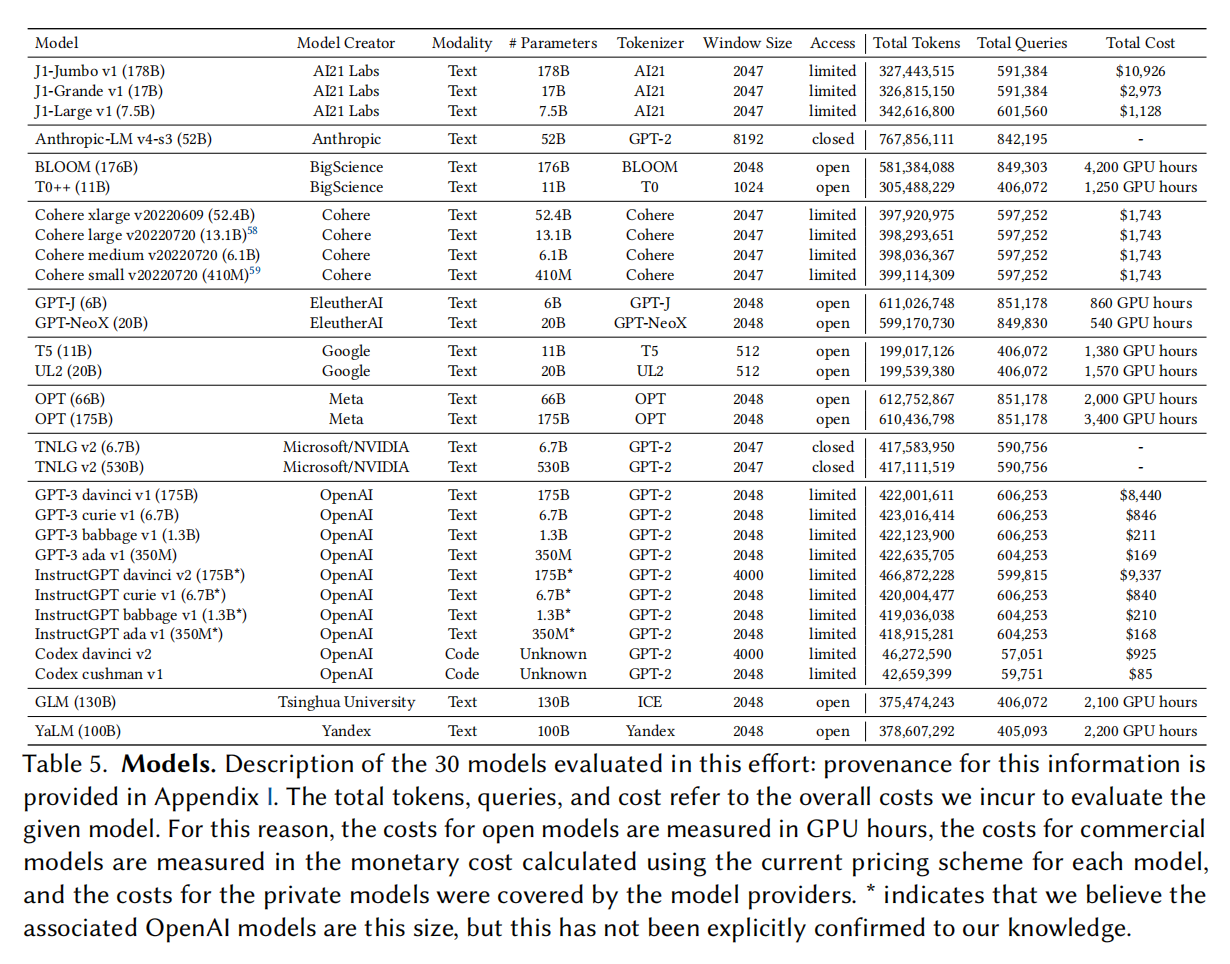
Adaptation via prompting

Experiments and results