T2I-Adapter:小组件控制信号对齐扩散模型
Abstract
建议学习简单和小的T2I-adapter,将T2I模型中的内部知识与外部控制信号对齐,同时冻结原始的大型T2I模型。在这种方法下根据不同的condition训练了不同的adapter来使语义丰富
Introduction

是否有可能以某种方式“挖掘”T2I模型已经隐含学习的能力,特别是高级结构和语义能力,然后明确使用它们来更准确地控制生成
作者认为一个非常小的模型可以实现这一目的,因为它不是学习这些能力,而是学习T2I模型中从控制信息到内部知识的映射。换句话说,这里的主要问题是“对齐”问题,即内部知识和外部控制信号应该对齐。因此,提出了T2I适配器,它是一个非常小的模型,可以用相对较少的数据量来学习这种对齐
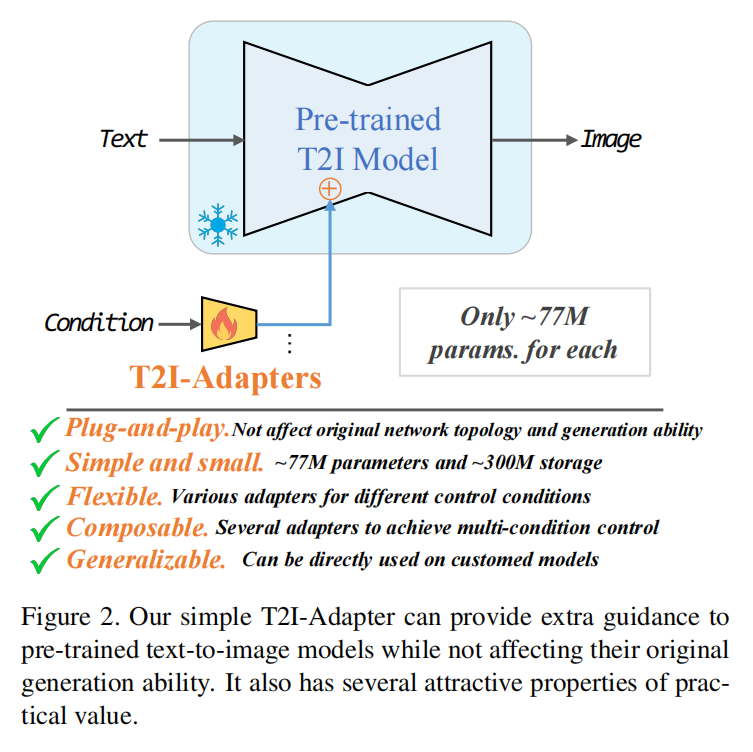
优点:
- 即插即用:不影响现有文本-图像模型网络和拓扑能力
- 简单小巧:训练成本低参数77M,存储300M
- 灵活:可以训练不同种adapter比如草图,语义分割,关键动作
- 可组合:组合多个adapter实现多种condition控制
- 可泛化:可以用于其他的定制模型
Method
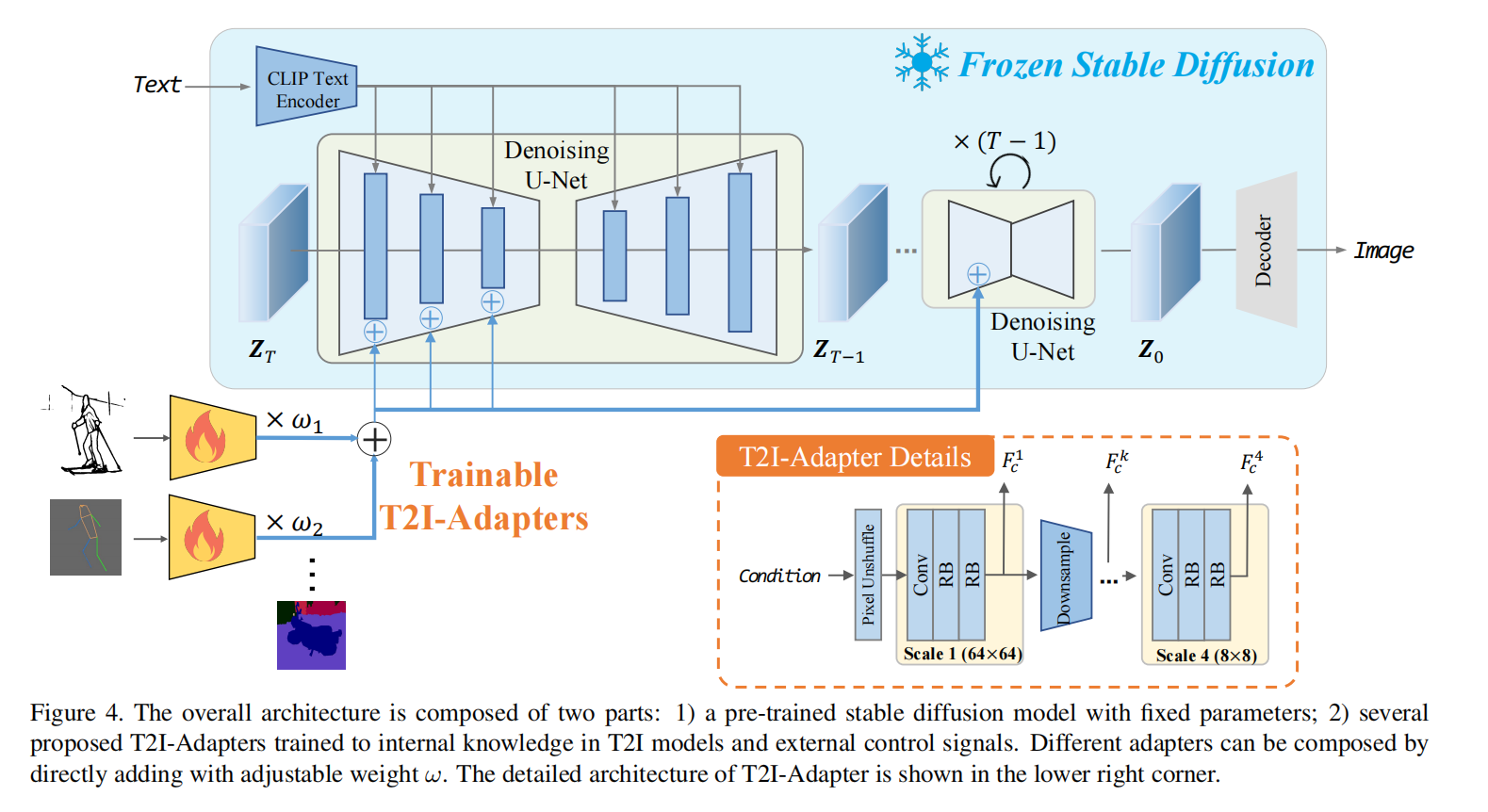
Preliminary: Stable Diffusion
在第一阶段,SD(stable diffusion)训练了一个自动编码器,它可以将自然图像X0转换为潜在空间,然后重建它们。在第二阶段,SD训练一个改进的UNet去噪器直接在潜在空间中进行去噪
在推理过程中,输入的潜在映射ZT由随机高斯分布生成的。给定ZT,它在每一步t输出一个噪声估计并减去它,到最后Z0的时候就是一个干净的潜在映射,然后丢给解码器生成图像
在conditional阶段,SD使用了预训练好的CLIP text encoder输出一个y,然后用几个cross-attention丢入denoising过程
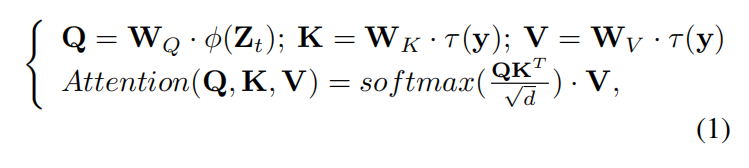
Overview of T2I-Adapter
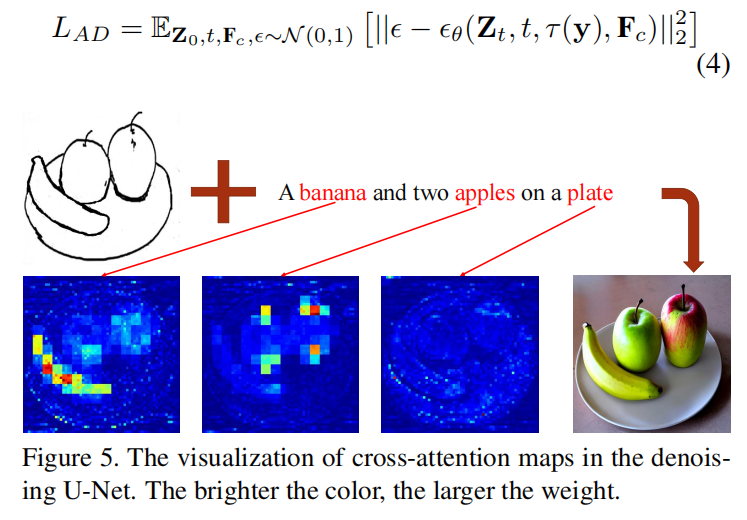
文本很难给图像的合成提供指导,这不是由于生成能力较差,而是因为文本不能提供准确的生成指导,以充分利用从巨大的训练数据中学习到的强大的生成能力
Adapter Architecture
它由4个特征提取块和3个下采样块组成,以改变特征分辨率。在每个块中,利用一个卷积层和两个残差块(RB)来提取结构特征
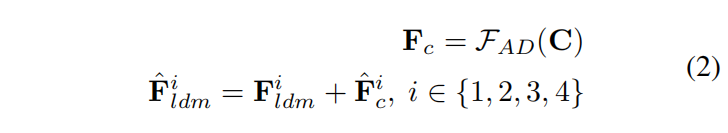
每个块的输出与U-net denoiser的编码器中间特征加起来
同时支持多条件控制
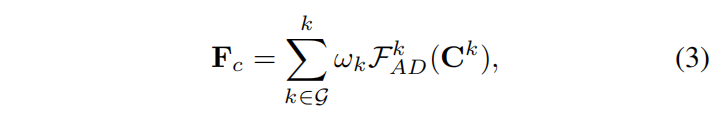
Model Optimization
Experiment
Implementation Details
batch_size=8,训练10个epoch,Adam,1e-5,4张v100-32g训练2天,三种结构condition:Sketch map,Semantic segmentation map,Keypoints map
Applications
各种条件控制情况看原文图像

