hh-rlhf:偏好模型+人类反馈微调
Abstract
用RLHF来对语言模型做微调很有帮助,并且发现和人类行为的对齐训练(alignment training)可以提升几乎所有自然语言的评估性能,特别是像python coding或做summarization。还做了迭代的在线训练,每个星期会用新的人类反馈来更新模型和RL策略,这能提升数据和模型质量。RL reward调过的模型和KL散度的平方根大致有一个线性关系
Introduction
训练的模型需要有帮助,输出真实,输出无害等
分别做了有效性和无害性的任务,都标注数据。对有效性对标注工去问模型一些纯文本的任务,比如问答,写作或改文档,讨论方案等。对无害性让标注工引诱模型讲违背规则的话,比如抢银行,骂人等。当然因为任务可能带有刺激人的心理或压力,所以两个任务交替来平复标注工的心情,主要让标注工给两种回答:better or worse
有效性和无害性往往有冲突,比如馊主意有效但有害,平庸的方案无害但无用。但实际上发现两个数据集放一起训练问题也不大
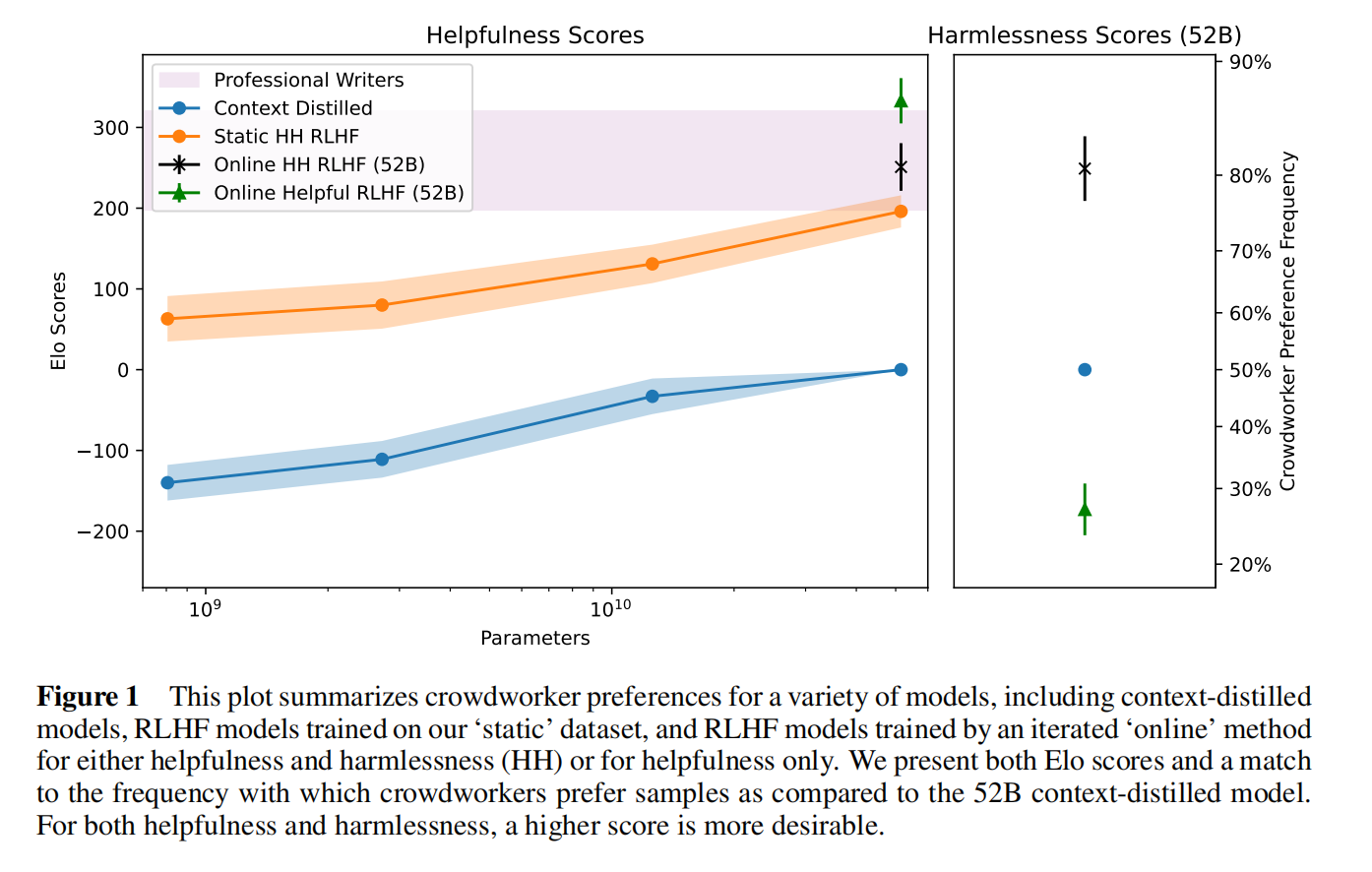
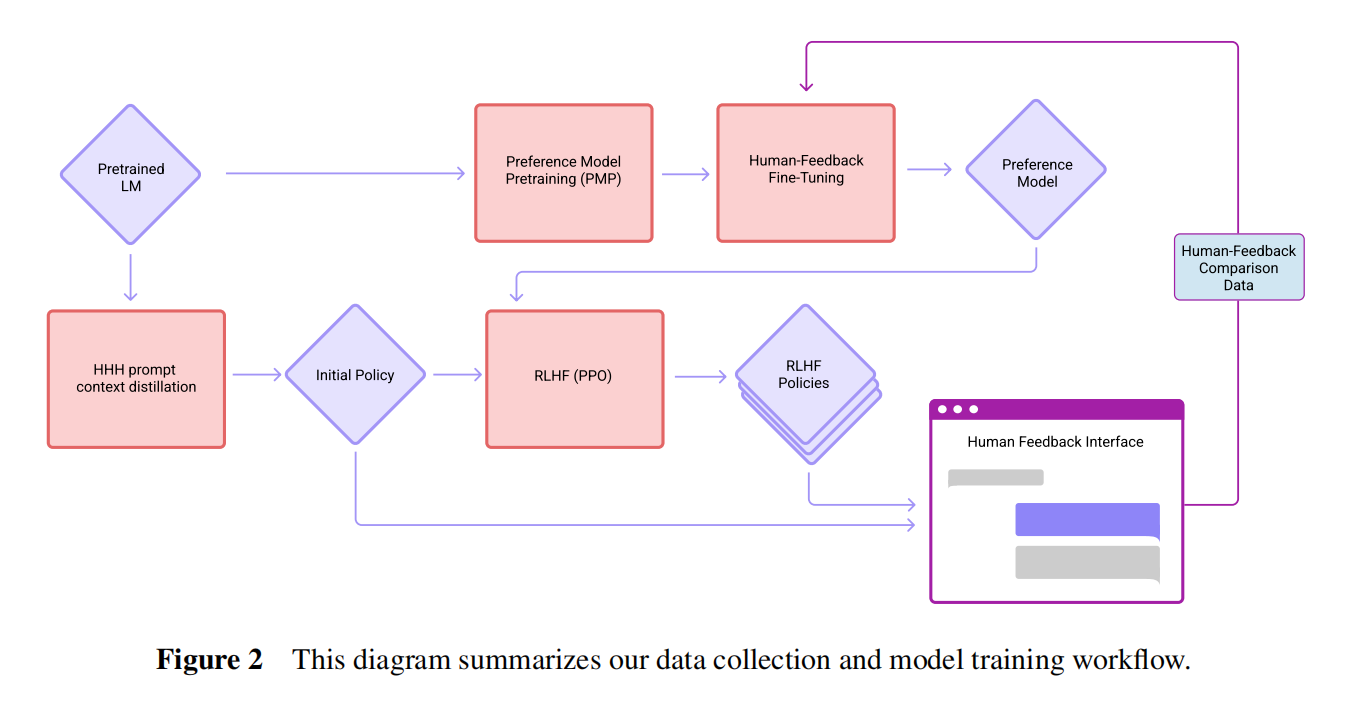
图1可以看出在线模型提升性能很大,需要显式的建模模型不作恶
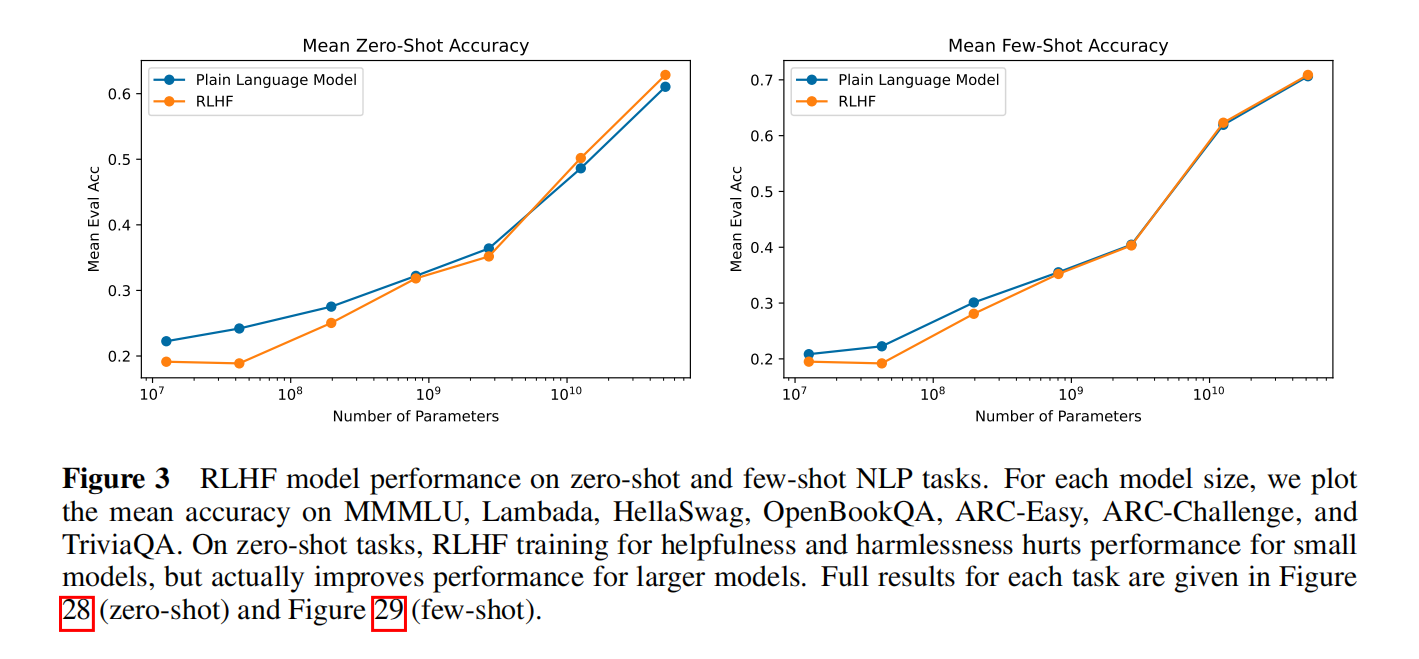
在小模型上做对齐后再其他的任务上performance会下降,但参数量更大后反而更好一些
Contribution
- 收集了一个多轮对话数据集
- 小模型有严重的对齐税,对齐后别的性能下降了;有用性和无害性有一定的冲突
Related Work
LaMDA标了一些数据微调了一下
InstructGPT有一个有监督学习的步骤,用人标注的数据来微调一下。但是本文直接使用了RL技术(用了一个context distillation,更多像一个prompt技术),增加了一个无害性的指标,奖励模型是6B,比较关键的就是做了在线
Data Collection
人类有很复杂的容易表达的直觉,但是很难用公式化呈现(有效性和有害性很难用公式呈现出来),所以要用人类反馈的自然语言对话来表达人类的逻辑
Task Specification and Crowdworkers
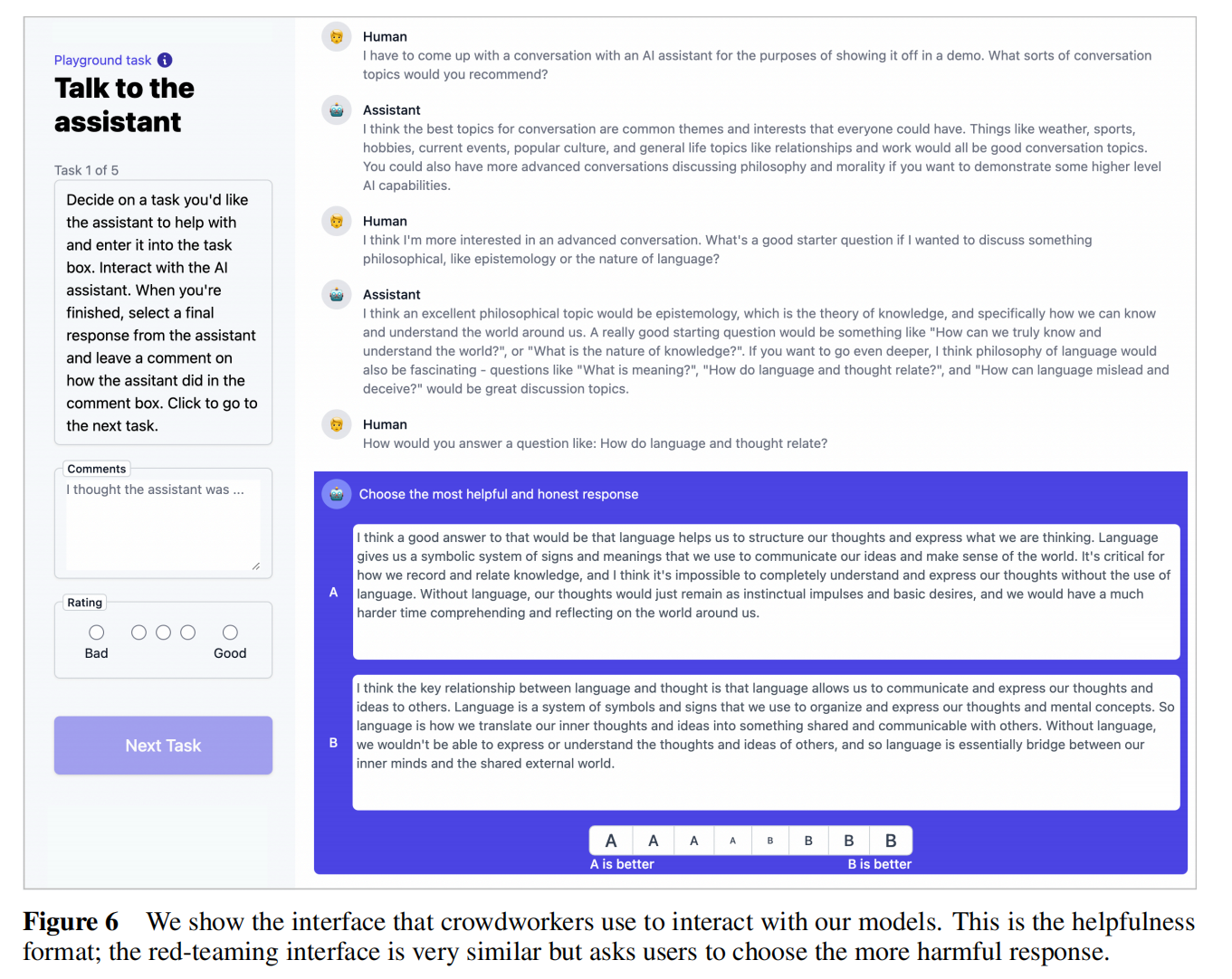
随机查标注工的问题写的好不好,更好的问题能和AI有更好的互动,而不是看标签质量高不高,这样更加简单也更加直观(请了给标注人员标注的标注人员)
要求标注人员有有效性和无害性,但没做更多的限制,这样可以保证数据的多样性
具体做法:
- 至少是美国硕士文凭的标注人员
- 表现最好的20个标了80%的数据,按数据量计费
- 把最好的worker之间建立交流频道,不断的反馈沟通
- 还在Upwork上找标注工,按小时计费,可以对话做的比较长
标注工也不是持续的,为了节省成本也没有让标注工检查模型输出是不是对的,在模型的真实性上有一定降低
Helpfulness and Harmlessness (Red Teaming) Datasets
两边同时训练容易导致分裂,未来可能解决
Models Deployed to the Feedback Interface and Associated Data Distributions
- HHH Context-Distilled 52B Language Model:上下文蒸馏出来的一个模型,最开始的模型
- Rejection Smapling (RS):在上面模型基础输出的样本上训练一个一个52B的偏好模型(奖励函数)判断生成答案的质量,取k个答案出来比如k=16,再用判断好坏
- RLHF-Finetuned Models:继续标注继续微调
最后阶段主要就是用之前微调好的模型不断微调,也可能多个模型同时部署,因为微调后不见得比没微调更好
根据三种模型把数据也分成下面三块:
- 最原始的数据,42k有效性对话,42k有害性对话
- 通过Reject sampling做出52k个有效对话和2k有害对话
- 在线数据有效性22k,没有有害性的
Comparing Models with Elo Scores
比较两个模型好坏的Elo分数,A模型打败B模型的赢率是多少,A模型的输出有多少比B模型好,越高越好
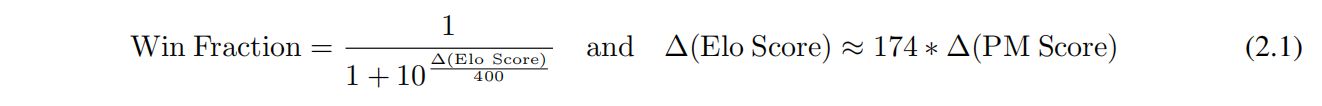
Preference Modeling for Helpfulness and Harmlessness
Models and Training Setup
从13M到52B都训练了喜好模型(PM),主要是三个阶段:
- 所有文本预训练
- 喜好模型预训练(PMP)
- 学习率1e-3,在StackExchange,Reddit和wikipedia上构造对比数据,上下文窗口1024
- 人类反馈上做微调
- 学习率1e-5,窗口2048
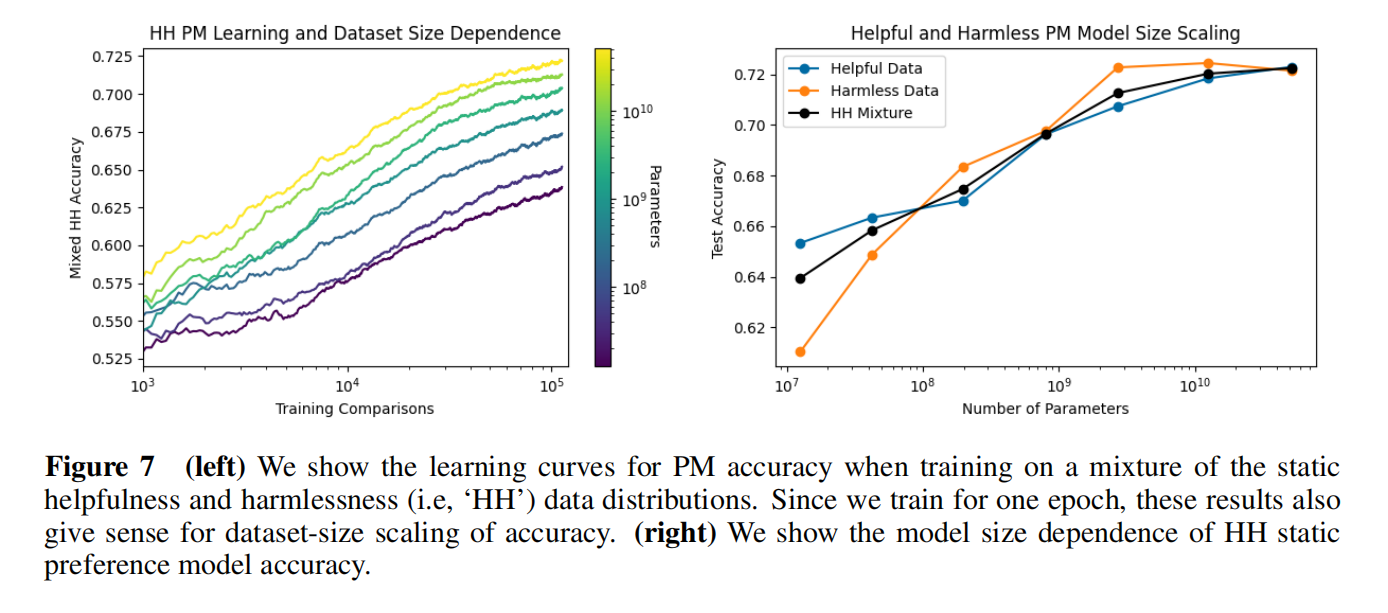
数据指数提升性能线性提升,同样的数据参数越大越好;有用性更加多样一点
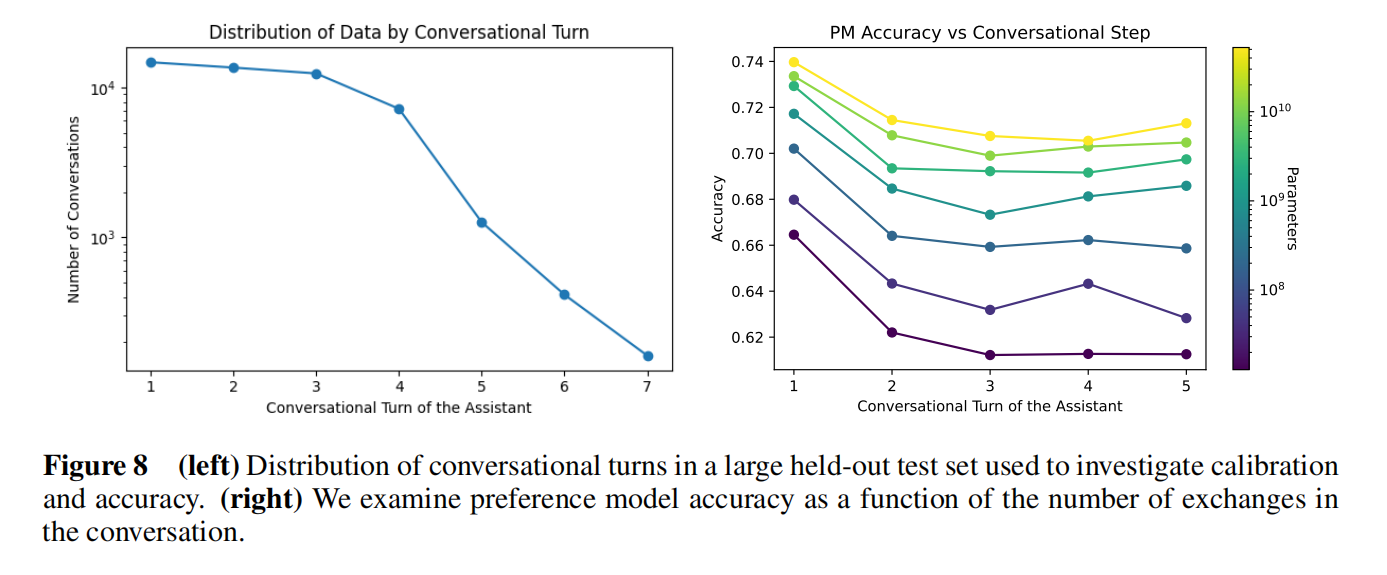
对话轮数的数据集,轮数变多了性能变低
Calibration of Preference Models and Implications for RL
模型是否被校验过,预测分数和真实的赢率是不是一致性的关系
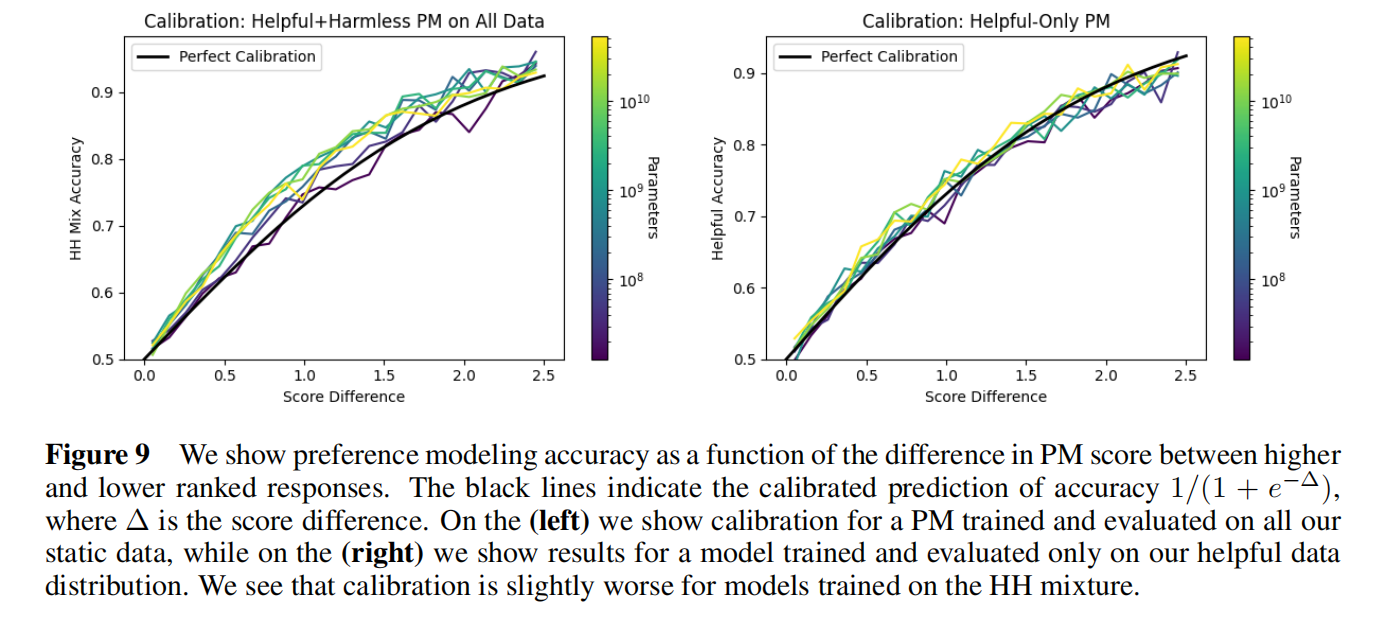
给一堆数据算喜好模型的分数差,代入Δ算出概率,模型线和黑色的线吻合就说明预测值和真实分数赢率(标注决定的)有映射关系的;有效性估计是比较准的
这个PM分数很重要因为这个会作为强化学习的信号,越准训练肯定更好
当样本都很好的时候人类打分,模型打分都变得困难,所以还是要做这种在线学习,重新训练使得分数区分更加准确
Reinforcement Learning from Human Feedback
Training Setup
- 先用对比的数据把喜好模型训练出来
- 训练RL policy生成喜好模型觉得分数比较高的结果
使用PPO算法,优化模型使得PM给的分数是最高的,同时也不能和原本的模型离太远
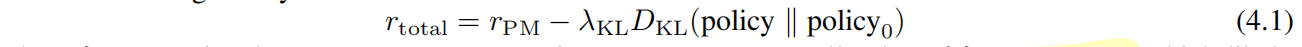
这里使用 $\lambda_{KL}=0.001$ 用大了就训练不出来了,D_KL也是<100的,后面这块可能就很小,可能就没有太大的必要
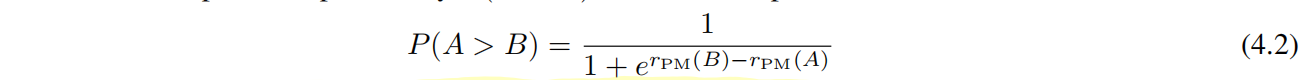
两个答案A和B算出A比B好的概率,用这个分数做奖励因为之前大家都这么用的
训练用的对话可以用之前的数据也可以生成,使用few-shot learning,已知10个比较高质量的queries让最大的模型去生成更多的东西。137k个标注的,369k个生成的
Robustness Experiments
主要是喜好模型的稳健性,应该和人对齐,但随着数据不一样也可能会评估不准,特别是两个答案都比较好的情况下
把标注的数据分为两块,每一块训练一个模型,一个叫train PM一个test PM,用train PM来指导模型再回过头看在test PM上也会更高,如果这样说明是比较稳健的,反之过度优化模型而没有提升
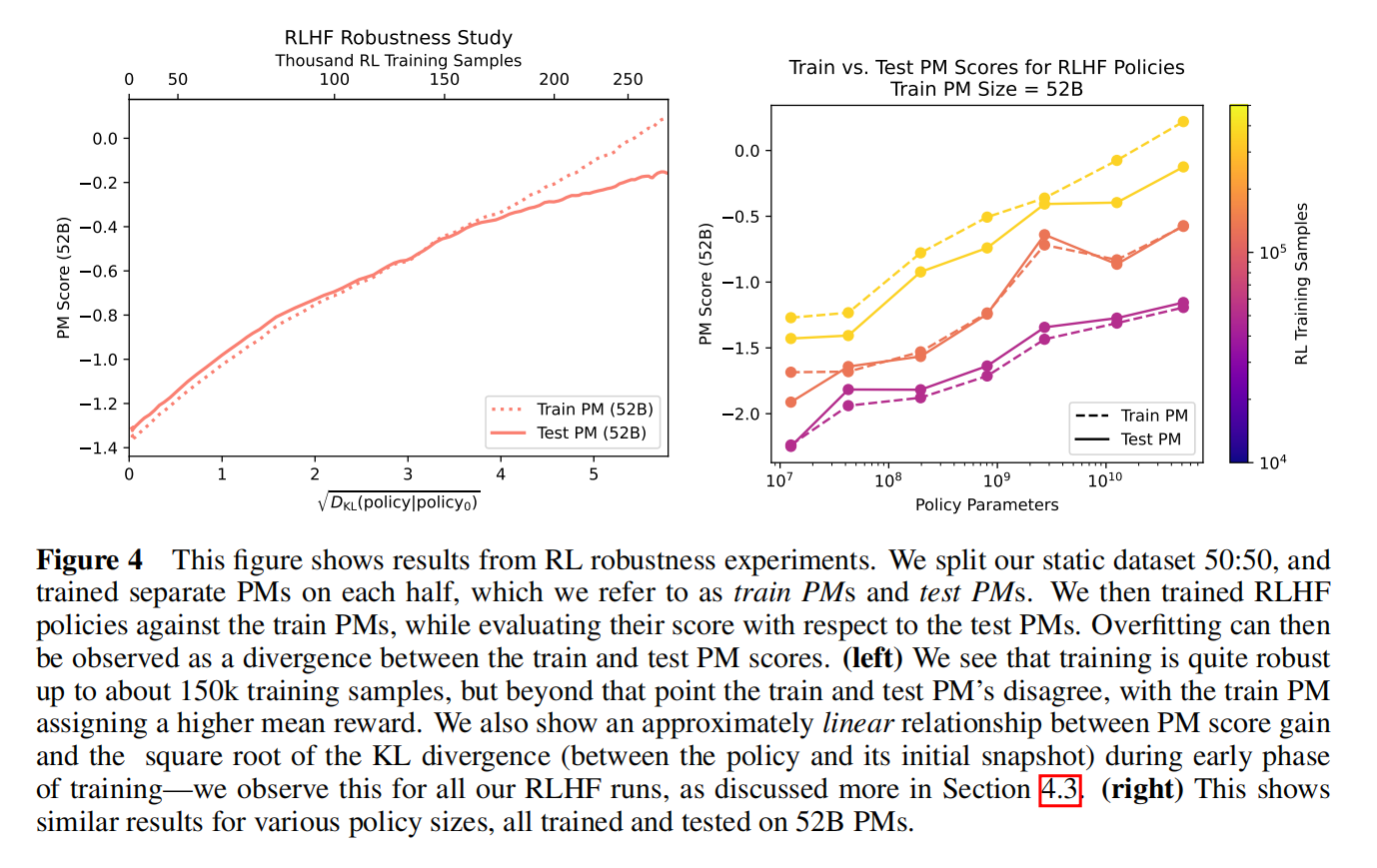
PM分数过了一个点后在测试上增加也不高,有点过拟合了
An Approximately Linear Relation Between $\sqrt{D_{KL}}$ and Reward
更新不远的时候模型效果和KL三度开根号有线性效果,有这个关系可以估计出多少的数据可以在多大的模型上更新出多好的效果
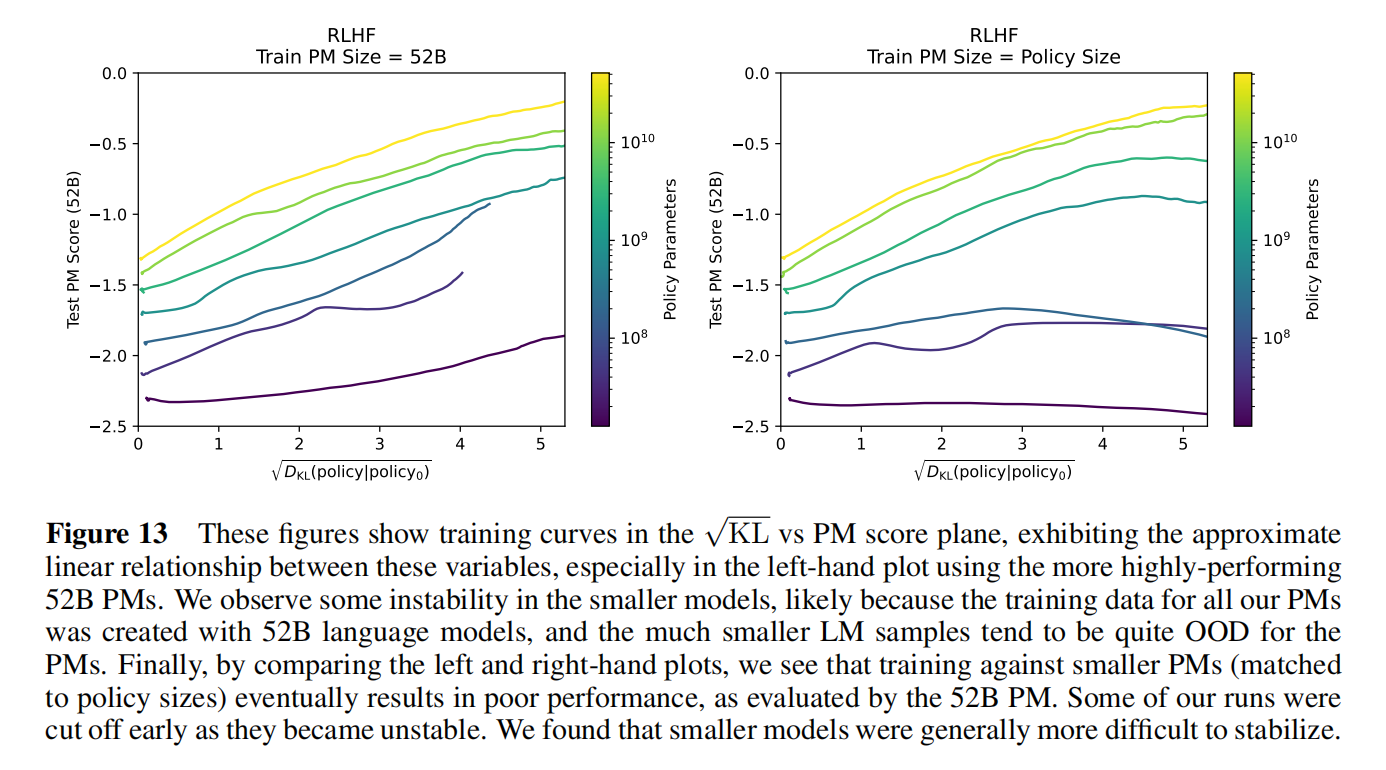
数据变多测试PM上的分数也是在提升的
Tension Between Helpfulness and Harmlessness in RLHF Training
比如生病了问模型,模型会尽量给出“不知道”,有点过度优化了无害性而弱化了有用性
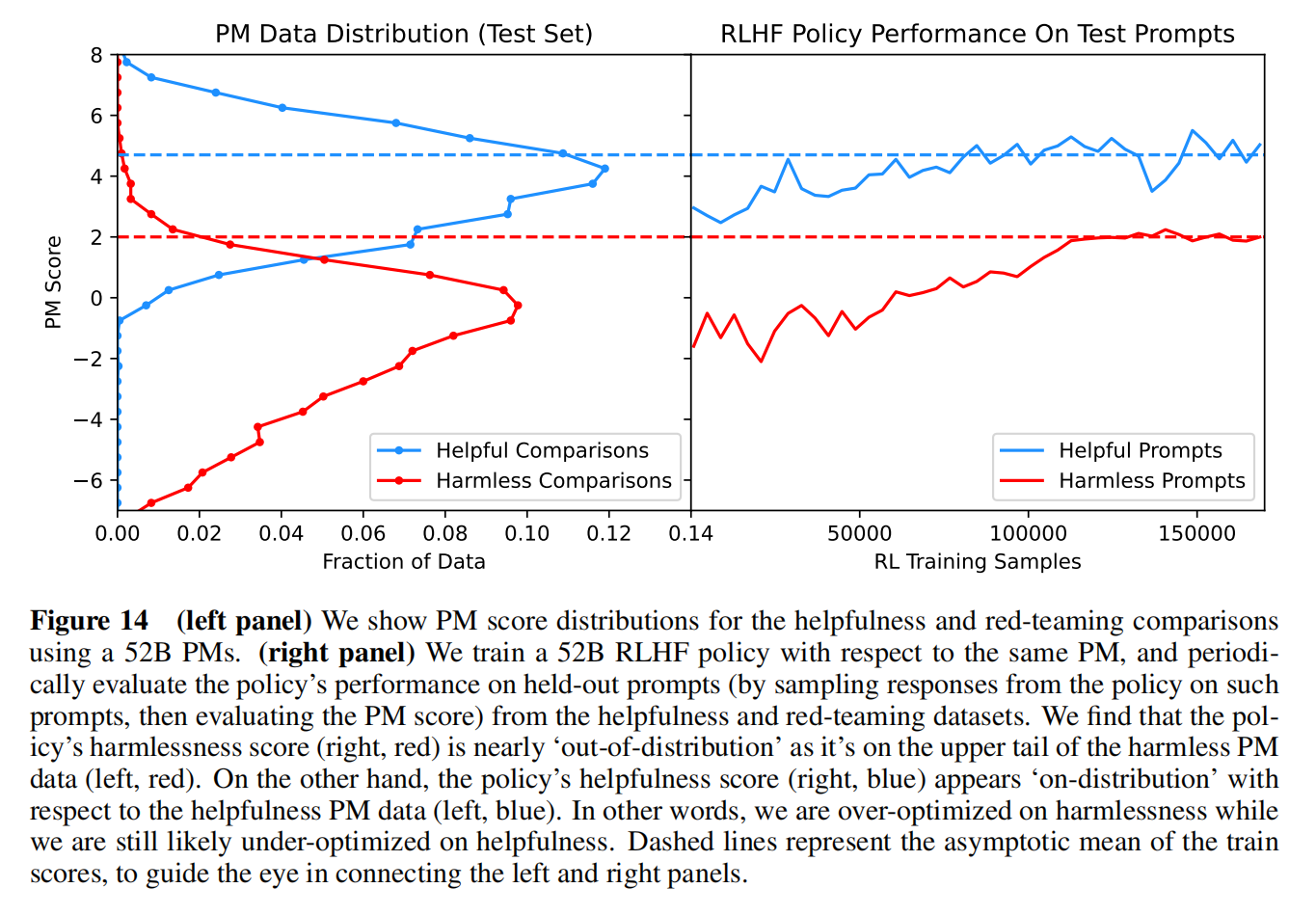
两个数据集的分布相差比较大,没有更好的办法就多采样有效性数据
Iterated Online RLHF
PM在高分数的地方校验性鲁棒性会变差,要重新更新喜好模型,迭代式的online RLHF:
- 找到最好的RLHF策略,从标注工收集数据,然后重新训练,在高分数答案上分布更准确
- 新数据和老数据混合一起重新训练一个PM
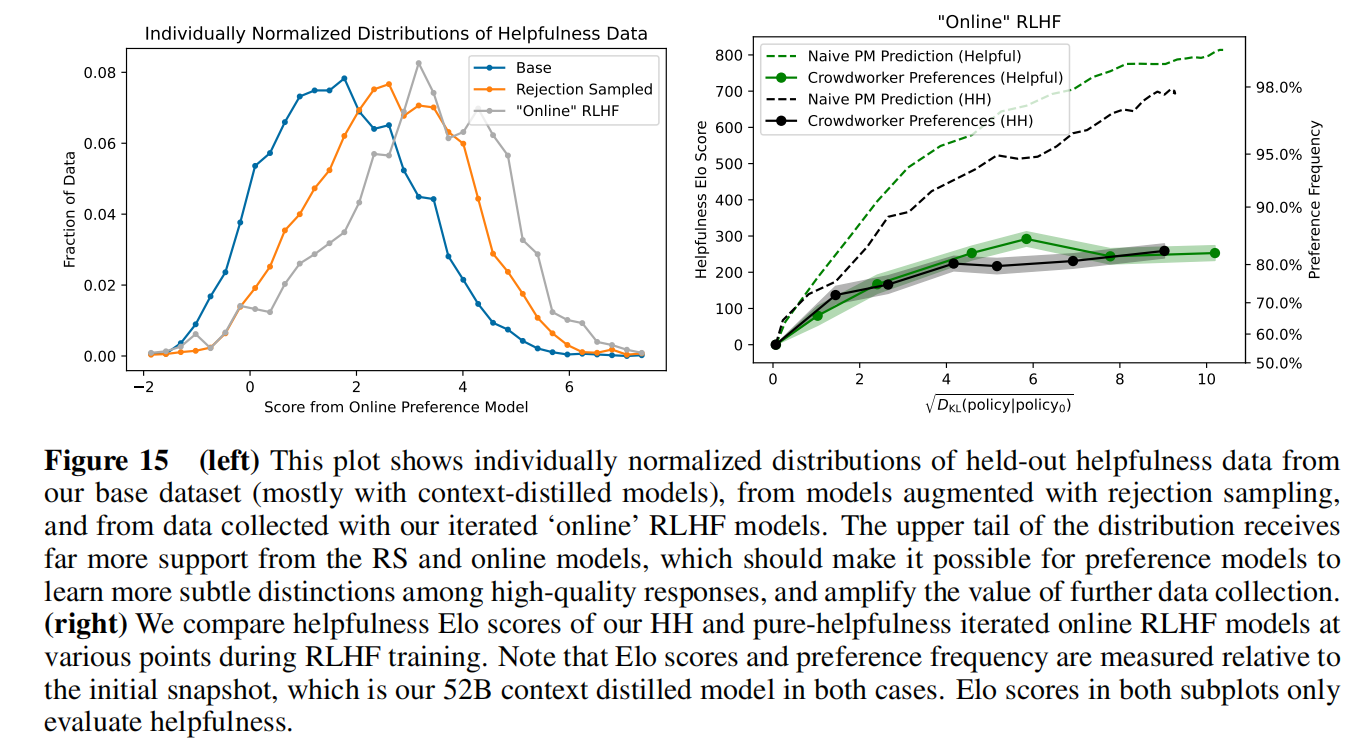
整个模型在分数上确实有提升
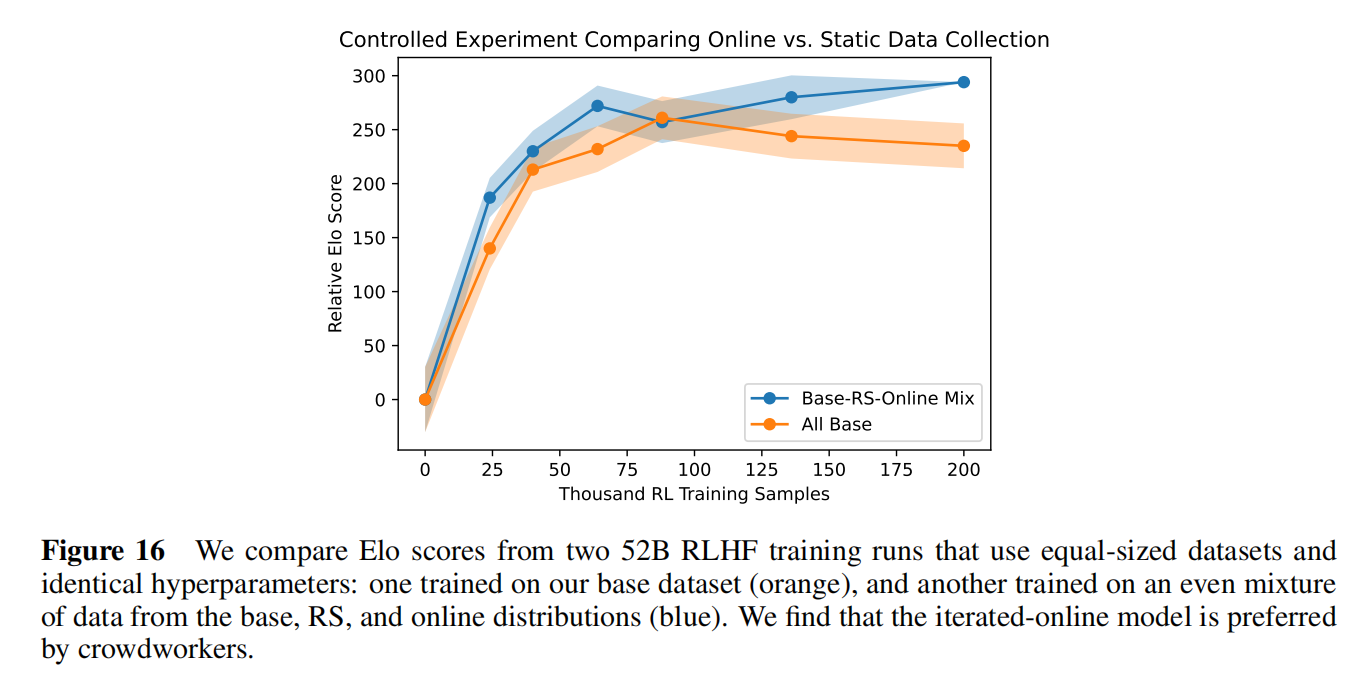
用在线和老数据混合情况下模型得到的答案会更准一些

