AIM:冻住image模型增加adapter做视频动作识别
Abstract
在图像上训练的模型在视频领域做full finetune非常昂贵,本文提出一个简单的adapter,把预训练模型冻住就能获取很好的结果。因为adapter简单,所以也能有很好的泛化性
Introduction
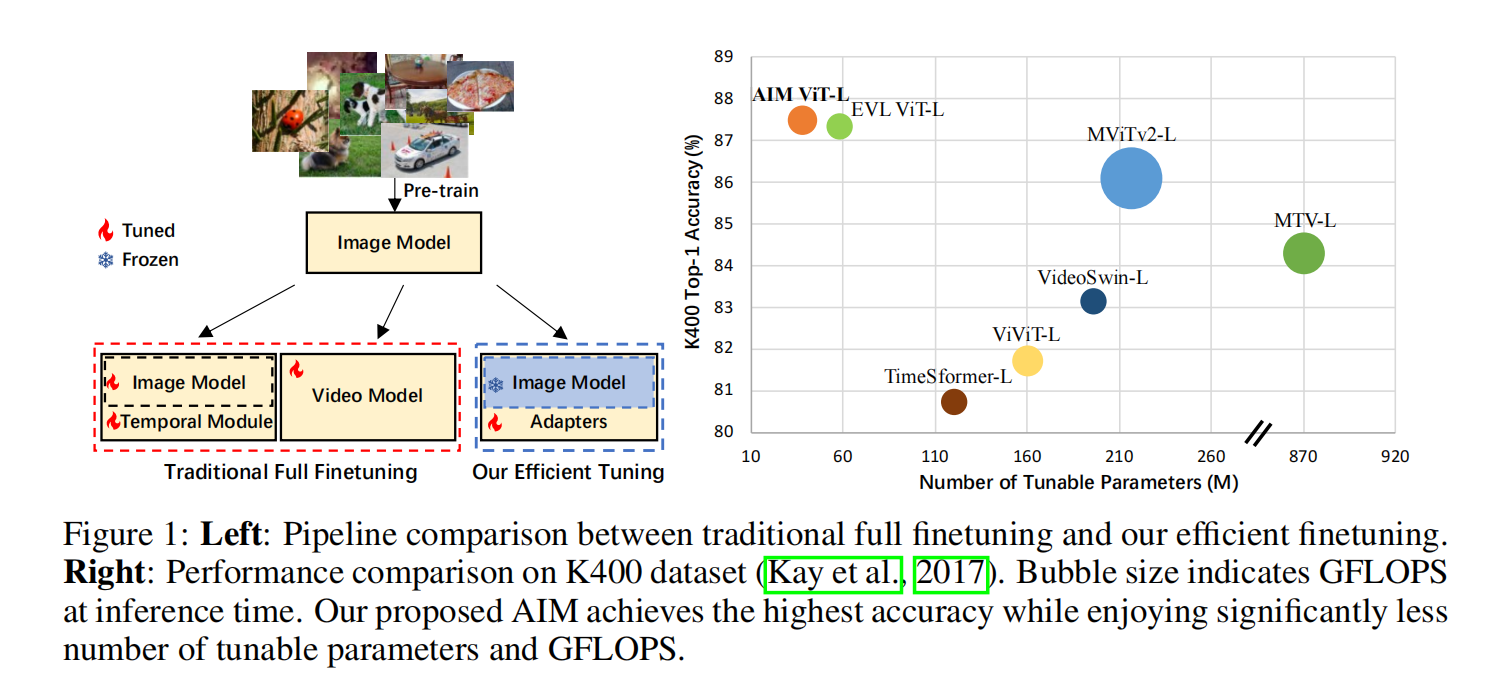
视频理解的工作简单可以划分为两类,一类是时间和空间上的处理尽量分开来做,一类是时空一起来做。但这些模型的计算代价都比较大,整个模型所有参数需要在视频数据集上full finetune,数据集大模型大训练的cost非常昂贵
一个训练好的图像模型直接抽特征也是非常具有泛化性的,比如像CLIP直接做zero-shot已经做的很好了。未来的foundation model肯定也会越来越有效,不需要finetune部分了。而且也是为了防止灾难性遗忘,当下游数据集不够好不够多的情况下硬去finetune大模型往往效果不好或是overfit不能用,或是原本大模型的特性就丢失了,泛化性也丢失了
本文的思路就是修改大image模型周边的环境(锁住参数),通过添加一些目标函数或是时序处理模块来使得图像模型能直接做视频理解的任务
Methodology
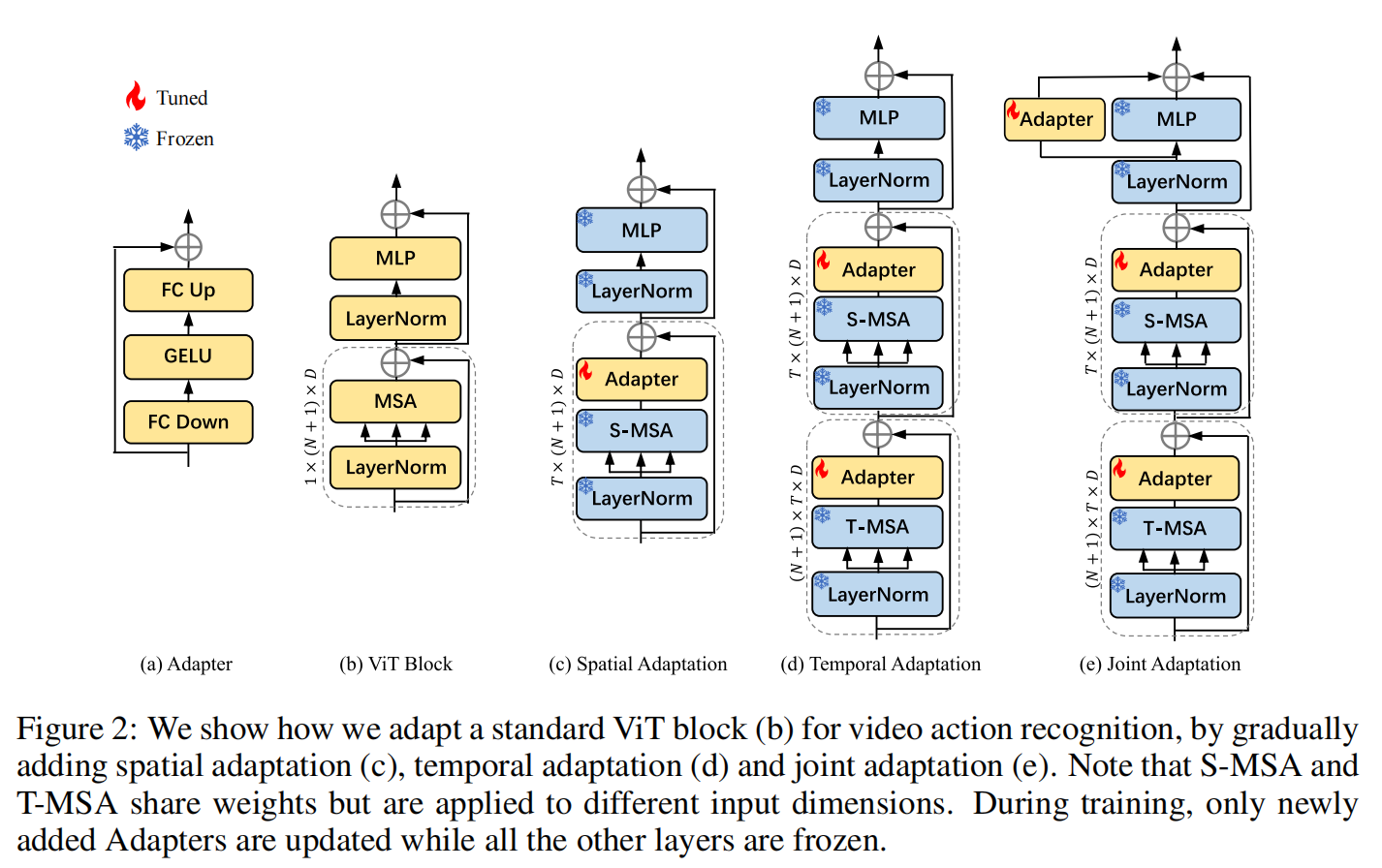
- Spatial Adaptation:就是在ViT上面加一层adapter
- Temporal Adaptation:复用一下self-attention,两个参数一致且完全锁住,中间做了一下reshape操作让attention层分别对时间和空间进行注意力操作
- Joint Adaptation:三个adapter各学各的,最后一个做fusion
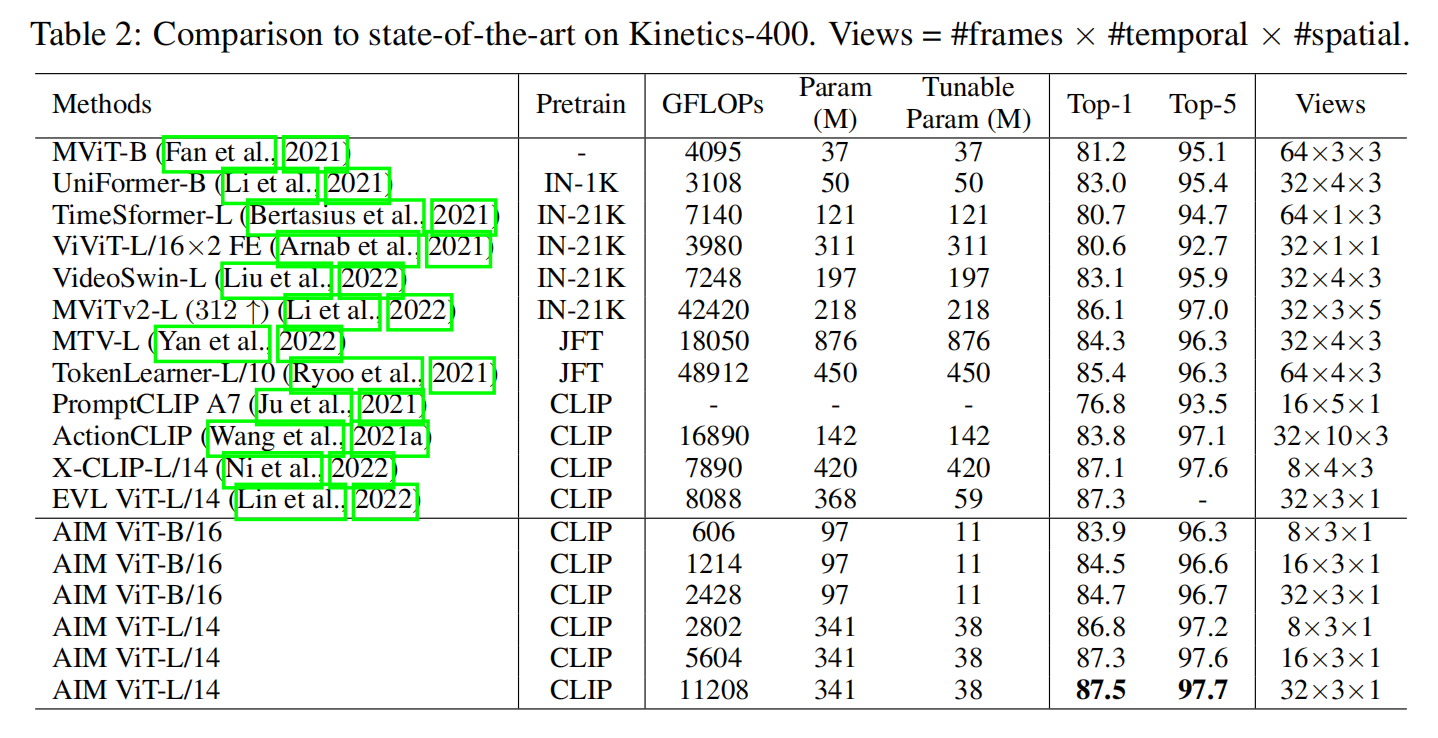
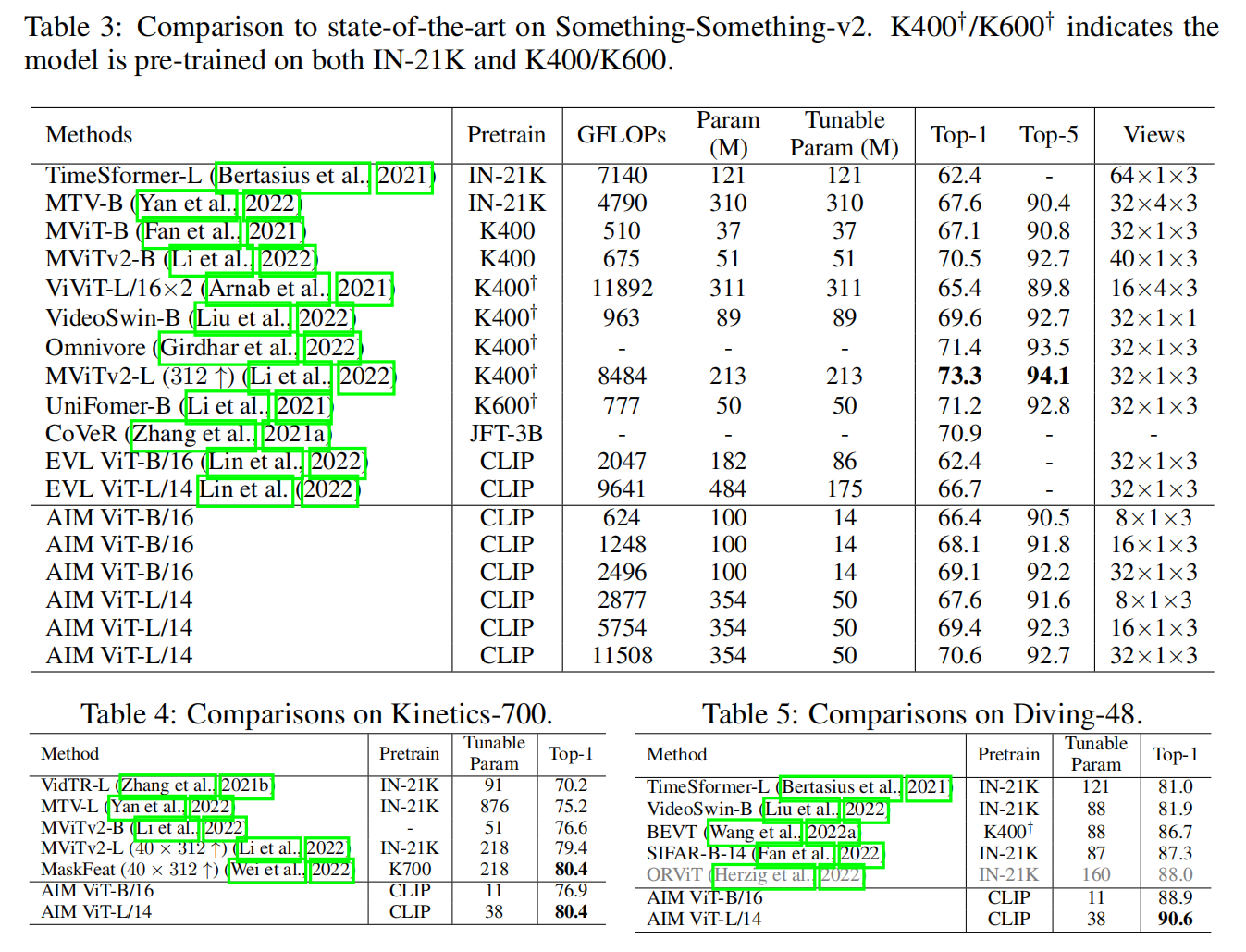
Experiments
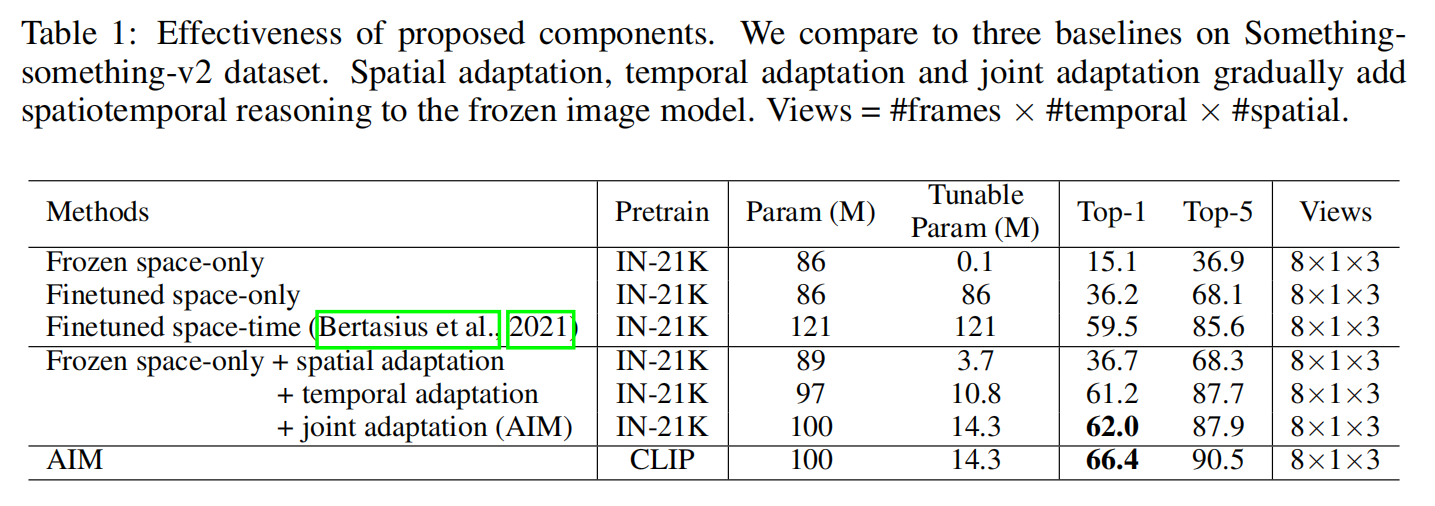
模型优化在视频理解领域还是一个很好的方向