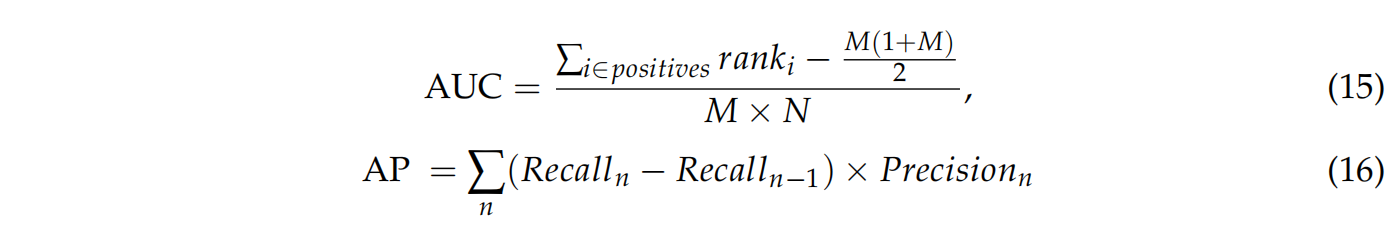论文地址:https://doi.org/10.3390/ijms24032217
DeepTP:特征选择+特征融合做热稳定蛋白二分类
Abstract
提出了一个基于自注意力机制和多通道特征融合技术来预测热蛋白质称为DeepTP。首先提出新数据集20,842个蛋白质,然后用卷积和双向LSTM网络提特征
Introduction
蛋白质工程和生物技术研究及依赖于蛋白质的热稳定性。嗜热蛋白的高热稳定性使其在工业生产中具有突出的优势。从家禽堆肥中分离的嗜热放线菌中纯化了一种细胞外等温角质酶(KERAK-29),具有耐热性高、催化反应速度快的优点。来自嗜热真菌的恒温木聚糖酶在食物、饲料和木质纤维素的生物转化中具有广泛的作用。
通过生物实验区分嗜热蛋白和中温蛋白是耗时、劳动密集型和昂贵的。然而,计算方法可以从大量的蛋白质序列信息中快速准确地识别嗜热和中温蛋白,这是蛋白质热稳定性领域的一个重要课题
蛋白质的热稳定性与氨基酸组成、氢键、盐桥、二硫键等生物特性密切相关。结果发现,嗜热蛋白比嗜中温蛋白具有更多的疏水残基、带电残基和芳香族残基。不同二肽的不同含量和不同类型的氢键也会影响蛋白质的热稳定性。在一些实验中,发现盐桥、二硫键等因素可以提高热稳定性。蛋白质的生物学特性对于嗜热蛋白的预测非常重要
嗜热蛋白预测的计算方法大多基于传统的机器学习方法。在早期基于较少数据集的研究中,研究人员使用蛋白质序列的一级结构来获得氨基酸对、氨基酸分布和基本特征,然后使用逻辑模型树算法、支持向量机(SVMs)等经典算法来预测嗜热蛋白质
像iThermo这样的工作只考虑了序列而没有考虑关于蛋白质序列本身的信息,所以本文用CNN提取蛋白质序列的局部信息,BiLSTM提取长短依赖信息
Results
Cross-Validation Performance of DeepTP
为了建立能够准确识别嗜热和嗜中温蛋白的模型,我们提取了6组蛋白质(氨基酸组成[AAC]、二肽组成[DPC]、组成-过渡分布[DPC]、准序列顺序描述符[QSO]、伪氨基酸组成[PAAC]和两亲性伪氨基酸组成[APAAC])的797个特征
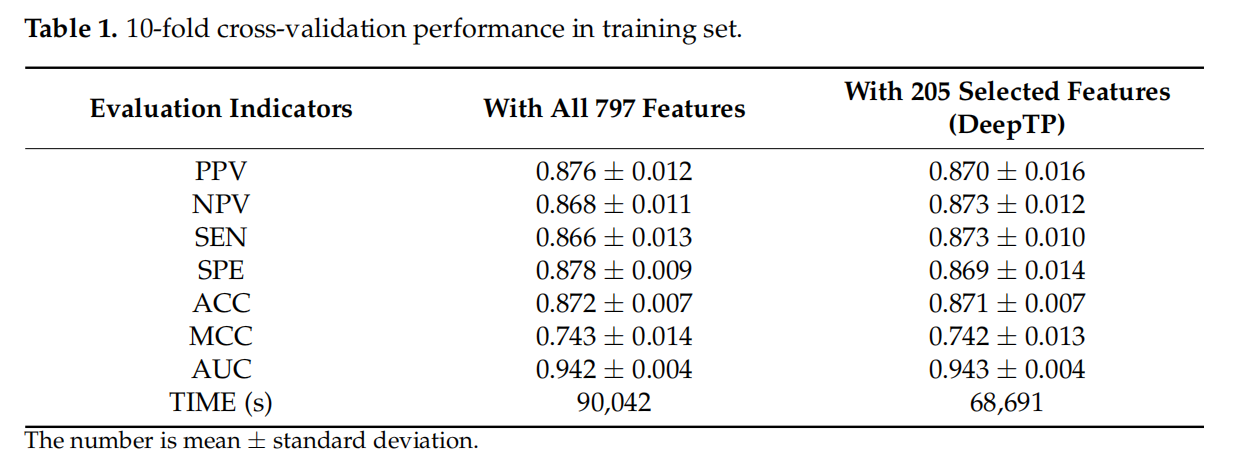
特征太多了用LightBGM来递归筛选,最后只留了205个
Performance Comparison of DeepTP with Other Methods in the Independent Test Set and Validation Set
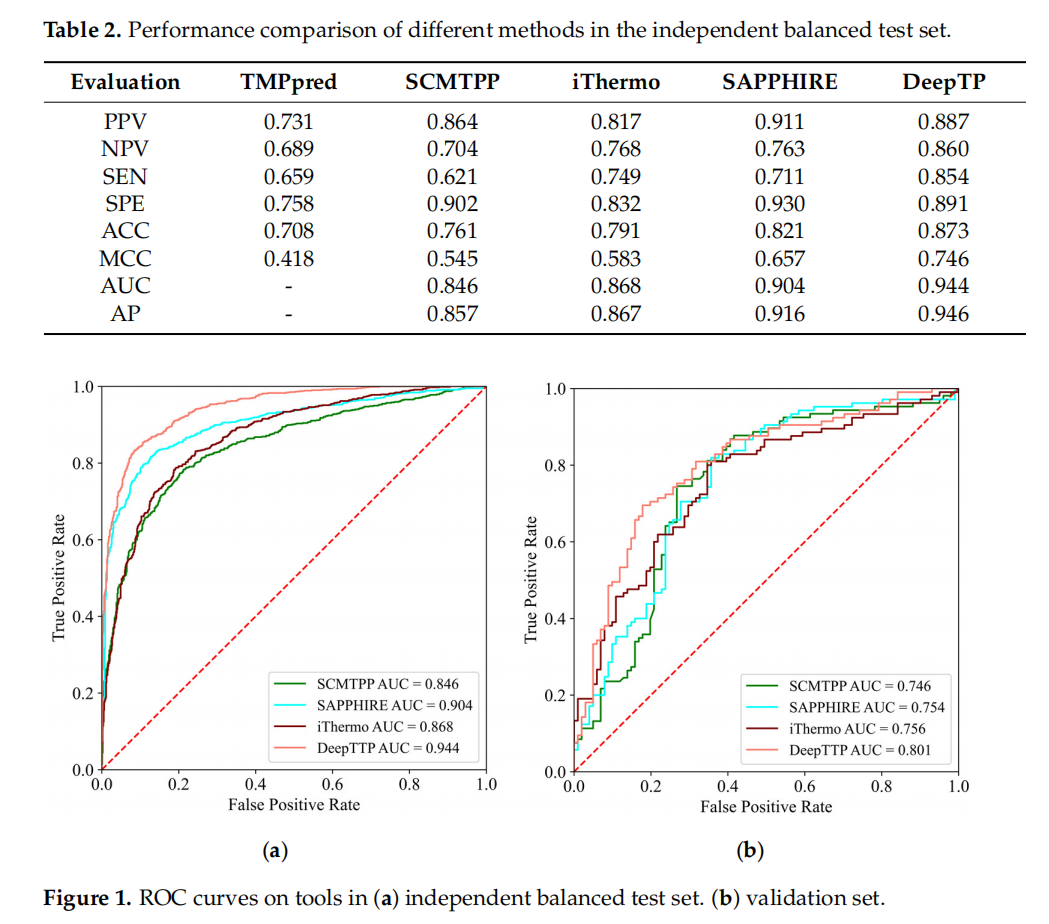
TMPpred是传统机器学习方法(SVM),用了7个特征
Algorithm Comparison
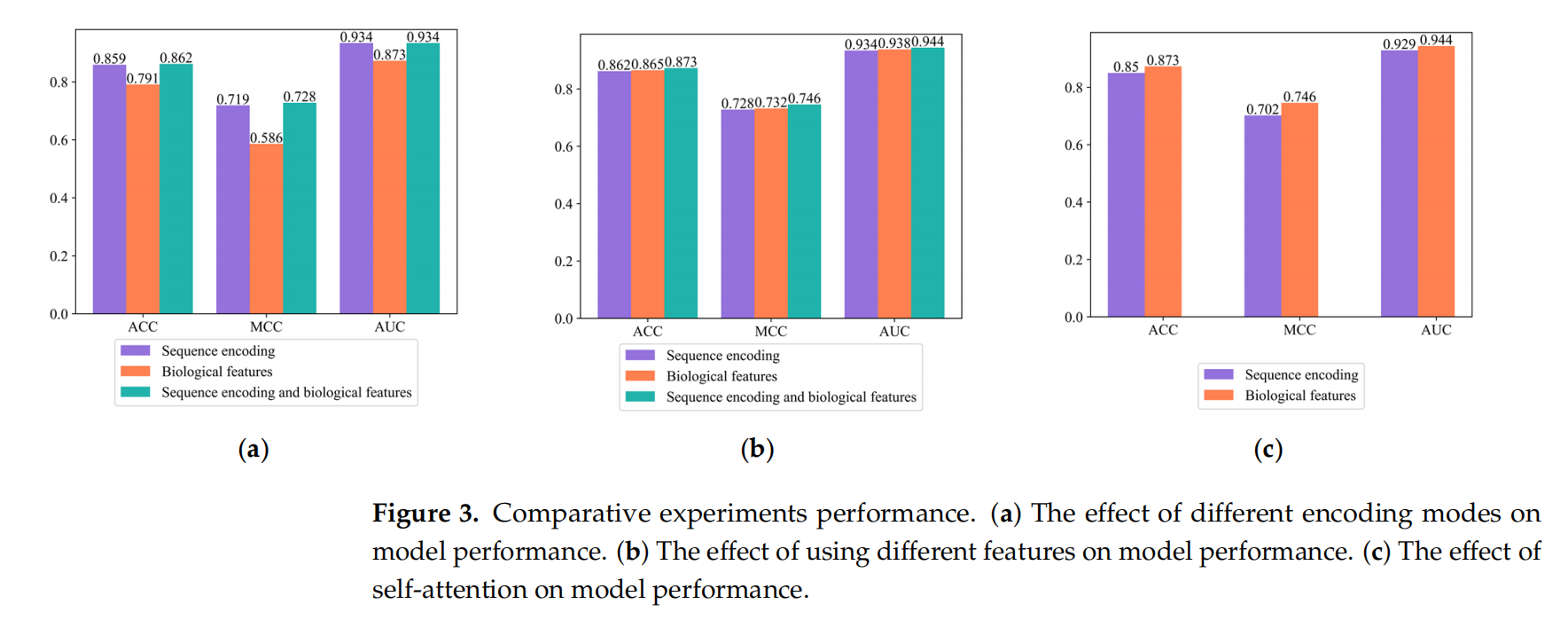
编码模式,使用的特征,自注意力消融实验
Discussion
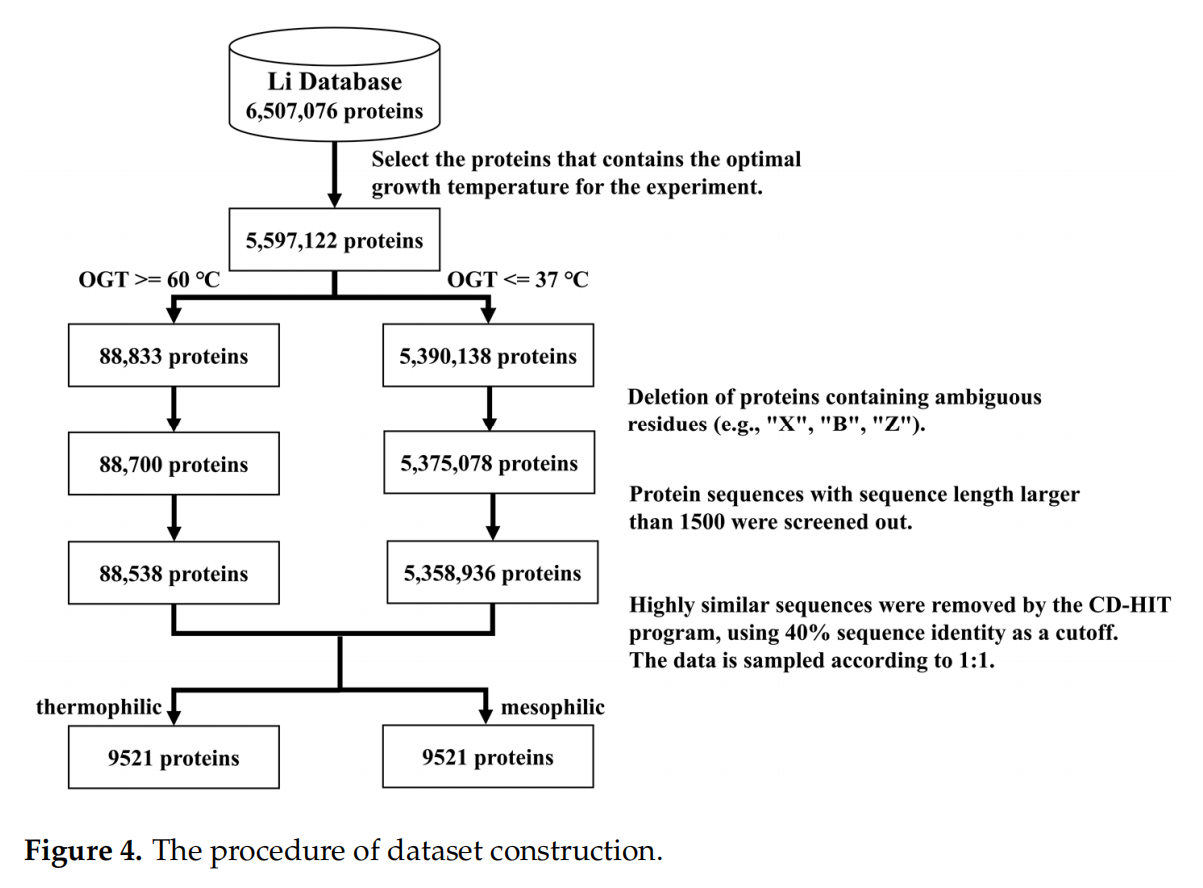
目前还没有用于嗜热蛋白预测的大规模公共基准数据集。因此,作者构建了一个可靠的大规模基准数据集,计算了6组生物特征,并使用RFECV过滤出最优特征子集
由于缺乏基准数据集,构建了两个独立的测试集,并获得了TMPpred提供的数据集作为验证集
Materials and Methods
Datasets
Features

Feature Selection
过多的维度会导致训练时收敛困难
参考ProTstab使用的特征选择方法,采用LightGBM算法,选择基于交叉验证(RFECV)的递归特征消除算法进行特征选择。递归特性消除(RFE)需要指定所需特性的数量,但通常不可能确定有多少特性是有效的。采用交叉验证算法和RFE算法对不同的特征子集进行评分,并选择最优子集,是一种有效的特征选择方案。最后,除了通过深度学习获得的特征表示外,还选择了205个生物特征来训练模型
Model
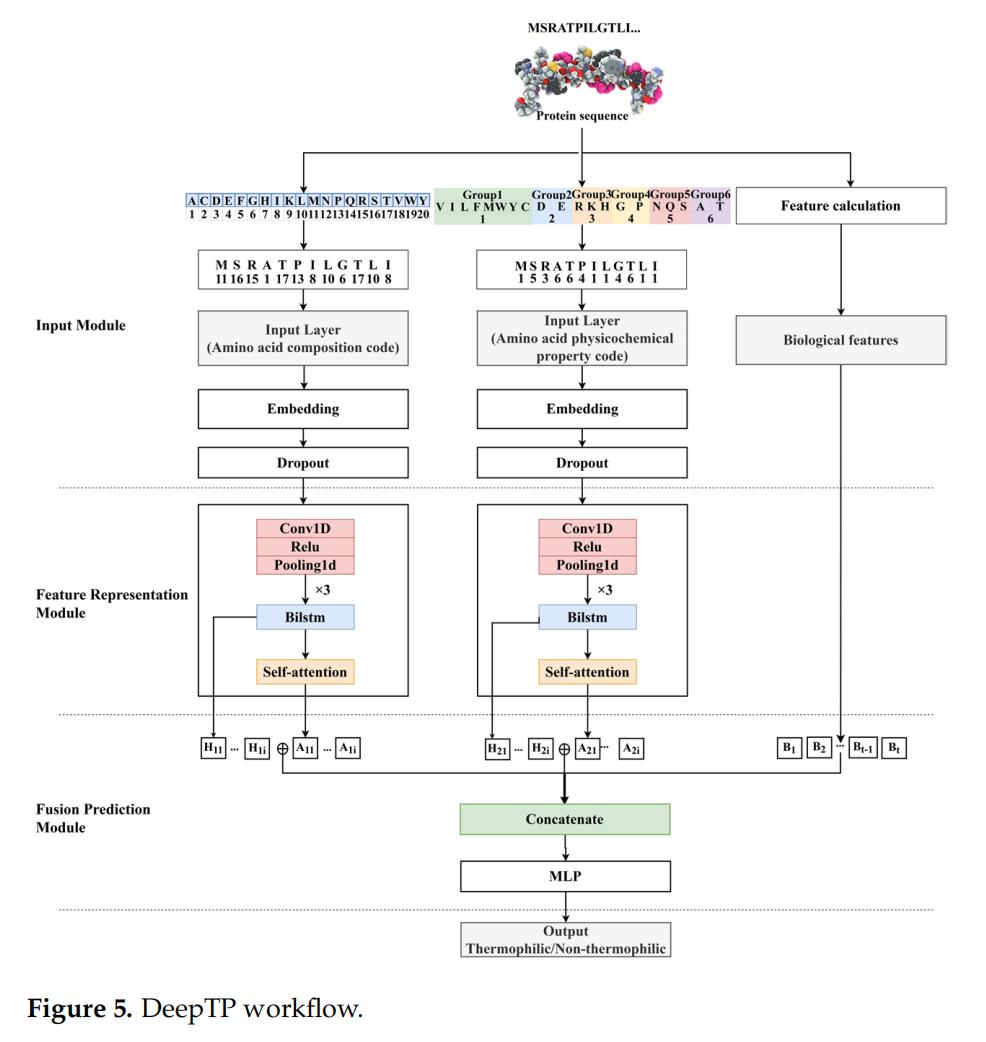
输入:
- Amino acid composition encoding:氨基酸字母编码
- Amino acid physicochemical property encoding:将氨基酸的物理化学性质分为六类:疏水性(V、I、L、F、M、W、Y、C)、负电荷(D、E)、正电荷(R、K、H)、构象(G、P)、极性(N、Q、S)等性质(A、T)
- Protein sequence-based biological features:205维特征
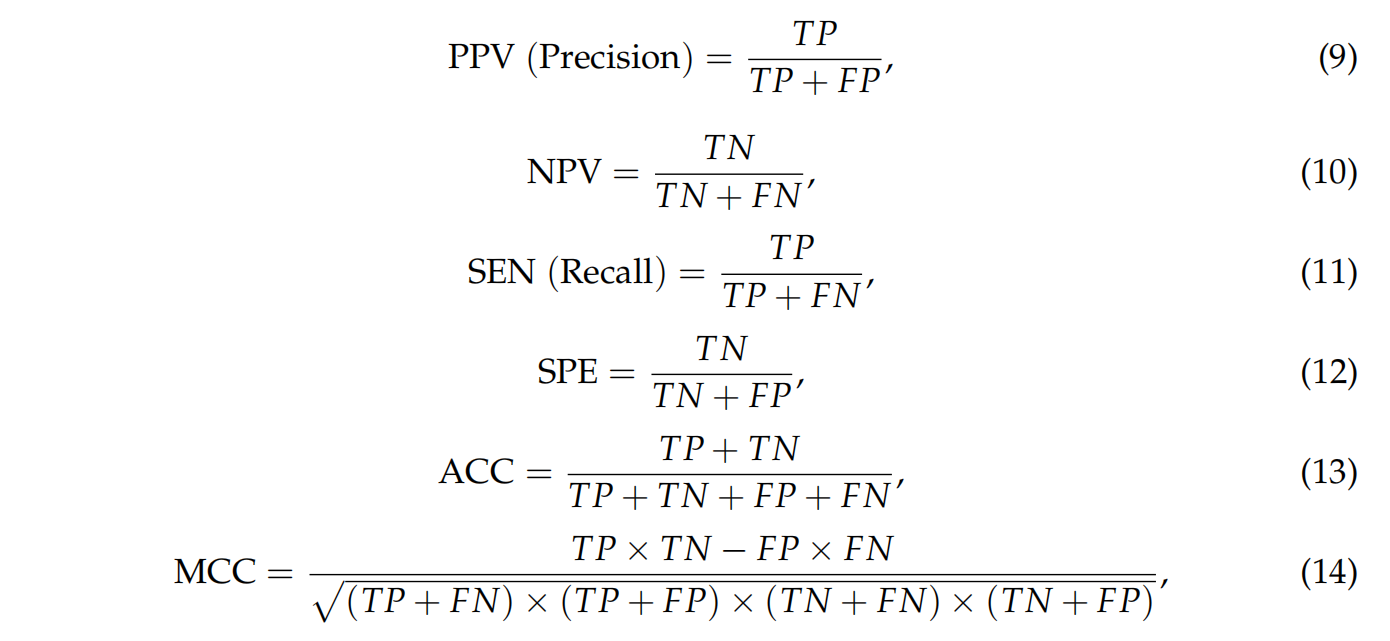
Evaluation Metrics