论文地址:https://www.frontiersin.org/articles/10.3389/fmicb.2022.790063/full
iThermo:手工特征+特征选择+MLP预测
Abstract
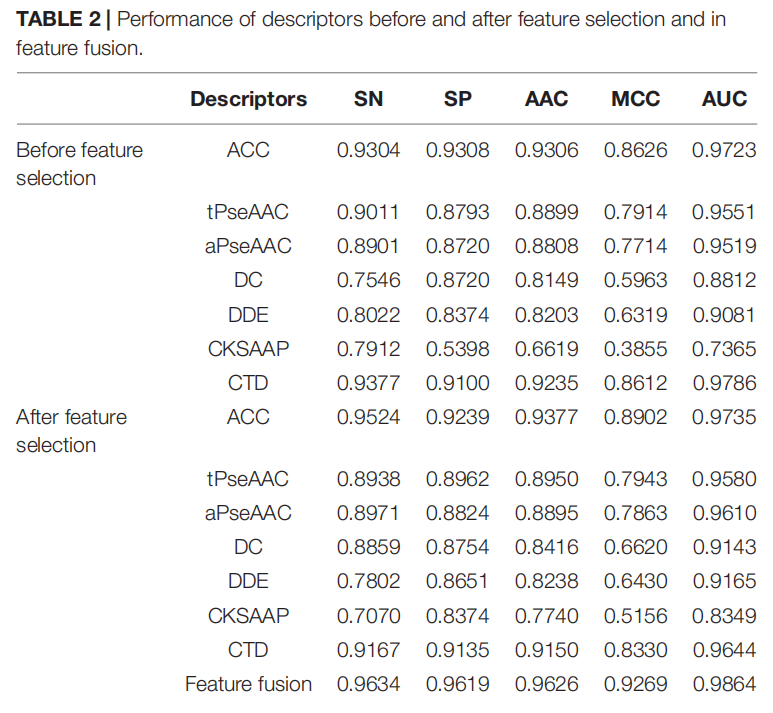
嗜热蛋白在生物技术和工业过程都有重要应用,因此需要一个快而准确的方法来识别嗜热蛋白。构建了一个1,368嗜热蛋白和1,445非嗜热蛋白的benchmark dataset,使用MLP和多特征融合策略来从非嗜热蛋白中识别出嗜热蛋白,准确度可以达到96.26%
Introduction
一般来说,在最佳生长温度(OGT)低于50◦C下生存的生物被认为是中温生物,而在50◦C或以上的OGT下生存的生物被称为嗜热生物,热稳定的蛋白质,甚至能有效抵抗高达120◦C的高温
关于嗜热蛋白的研究已经有很多了。研究发现,蛋白质的热稳定性与蛋白质中氨基酸的分布、二肽组成(DC)、疏水性、氢键、残基和残基间接触、螺旋极性表面、侧链相互作用和盐桥有关
Materials and Methods
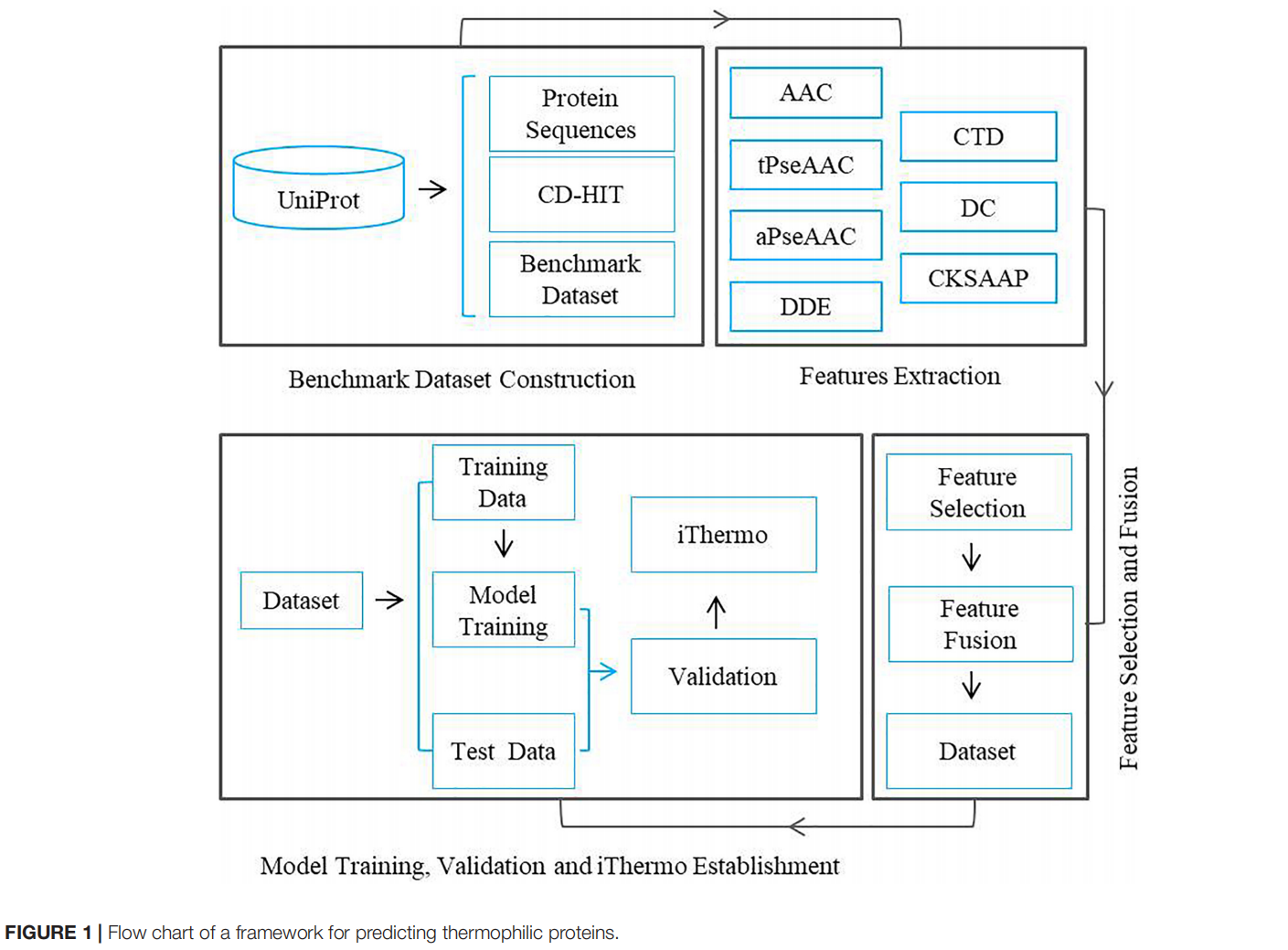
Dataset
在先前的研究中,学者把50°作为一个截止点来构建一个基准数据集。然而,这一标准似乎并不客观,因为蛋白质即使在微生物的OGT值以上也可能是稳定的,在50以下的负样本在60以上其实也能生存这就导致了混乱。例如,生活在45◦C的微生物产生的蛋白质在60◦C时可能不会变性
为了消除这种情况采用分类是60°以上嗜热,30°以下不嗜热
所有蛋白都是从UniPort里抓取的,随后,我们采用以下步骤来确保蛋白质数据的质量:
- 人工审查过的蛋白质保留下来
- 排除含ambiguous residue的蛋白质
- 排除其他蛋白质片段的序列
- 排除从预测或同源性推断出来的的蛋白质
- 为了消除冗余和同源性偏差,使用CD-HIT程序将序列一致性的截止点设置为30%
最终的基准数据集包含了1,443个非嗜热蛋白和1,366个嗜热蛋白,训练:测试=80:20
Feature Extraction
使用iFethare程序生成7种蛋白质特征
Amino Acid Composition
20种氨基酸在序列中出现的频率
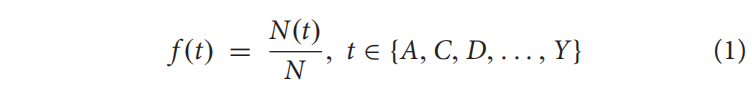
Traditional Pseudo Amino Acid Composition
根据其理化性质来描述残基的相关性,对于每个蛋白P,可以表示为20+λ维:
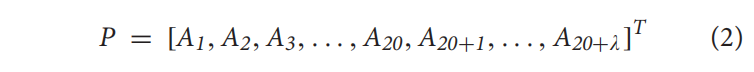
每个维度元素计算方法,$f_u$ 表示氨基酸出现频率,$\tau_k$ 表示k-tire序列相关因子:
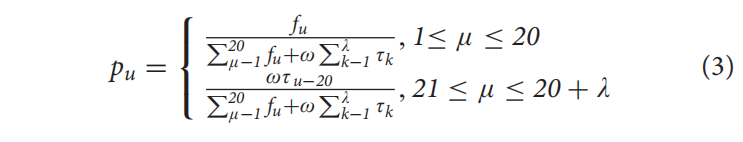
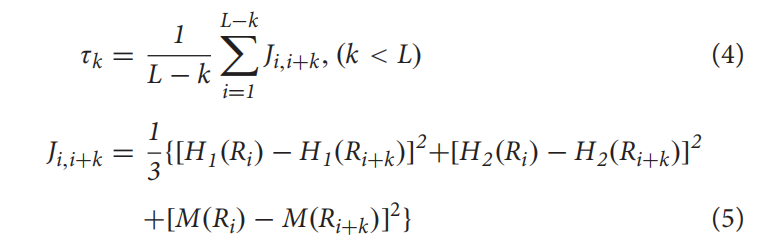
其中 $H_1(R_i)$ 是疏水性的值,$H_2(R_i)$ 是亲水性的值,$M(R_i)$ 是氨基酸Ri侧链质量
Amphiphilic Pseudo Amino Acid Composition
该描述符包含氨基酸基于疏水性和亲水性的部分序列顺序效应
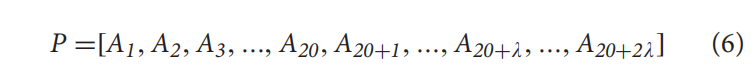
Composition of k-Spaced Amino Acid Pairs
CKSAAP描述了由任何符号为k的氨基酸分隔的配对氨基酸的频率。k的值可以从0到5不等
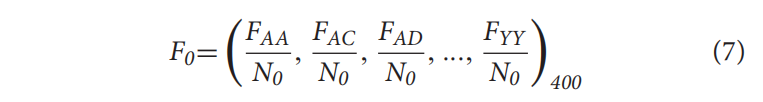
其中F0表示(k = 0)的CKSAAP,F表示零间隔的氨基酸对的频率,n0表示总的零间隔的氨基酸对
Dipeptide Composition
二肽组成是指蛋白质序列中二肽组成的频率
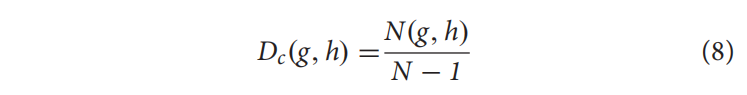
Dipeptide Deviation From Expected Means
提出的二肽偏离预期平均值,包括二肽组成(DC)、理论平均值(Tm)和理论方差(Tv)的组合
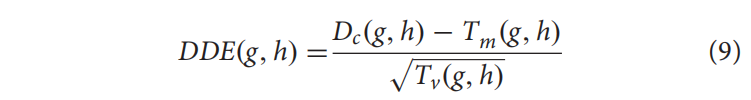
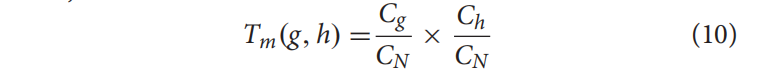
其中,Cg为氨基酸g的总密码子编码,Ch为氨基酸h的总密码子编码。CN是除终止密码子外的密码子数。
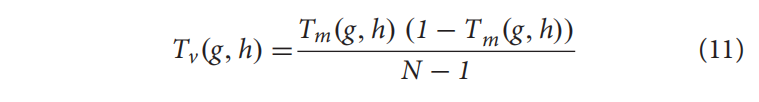
N是序列长度
Composition, Transition, and Distribution
根据氨基酸的特性,20个氨基酸可以分为极性、中性和疏水。根据CTD的定义,Composition©为极性、中性和疏水残基的出现百分比;Transition(T)表示转移的频率;Distribution(D)是每组前25、50、75、100%氨基酸的位置

Feature Selection
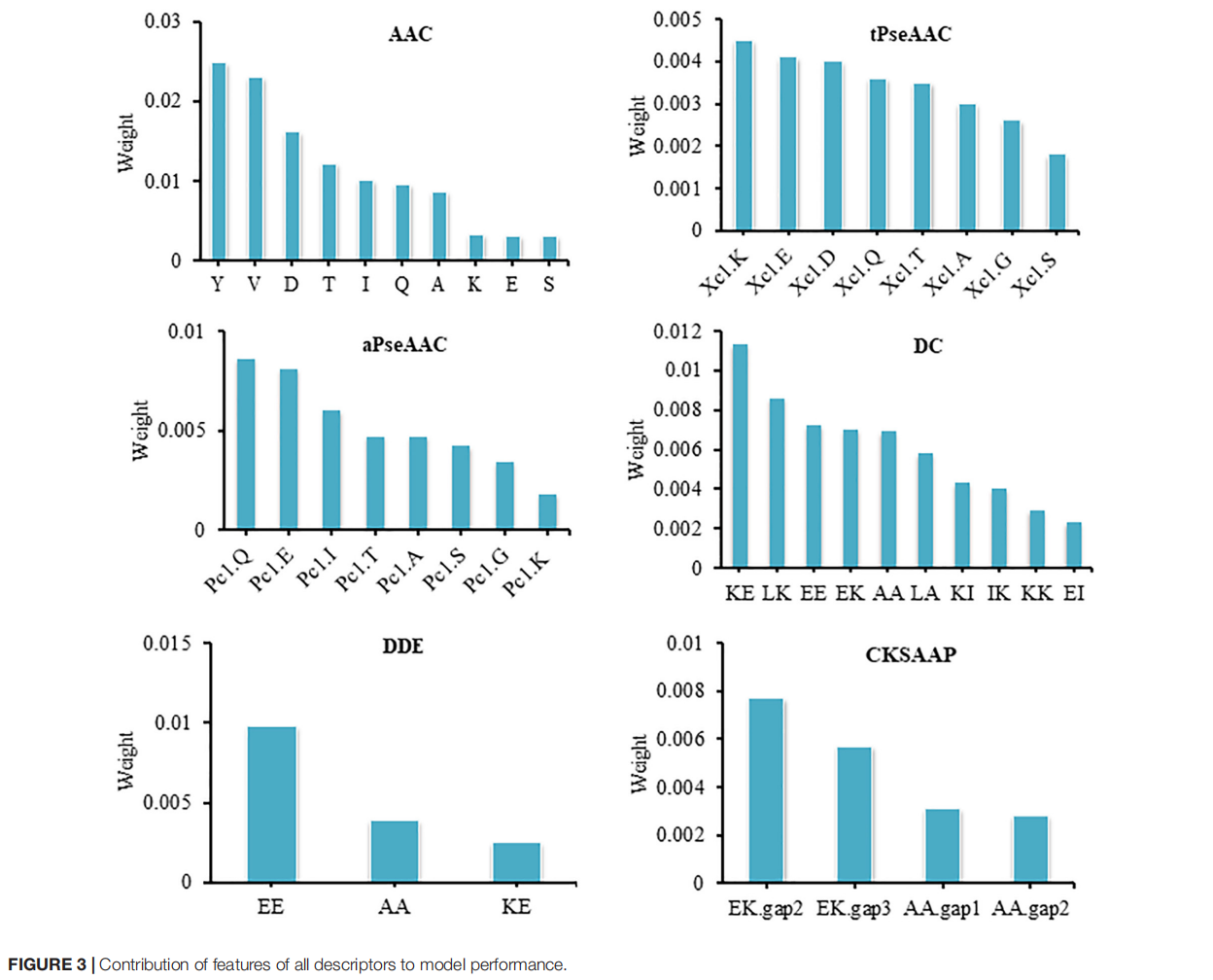
方差分析(ANOVA)可以用于基于F-value选择最佳特征子集。F值为样本类型之间的方差与样本内的方差之比。一个特征的F值越大,就意味着该特征对区分正样本和负样本的贡献越大
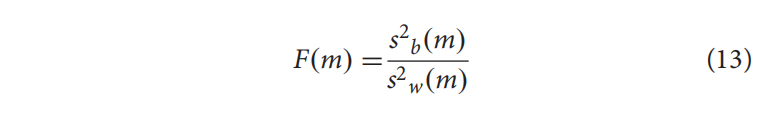
$s^2_b$ 是特征之间的方差,$s^2_w$ 是每个特征样本间的方差
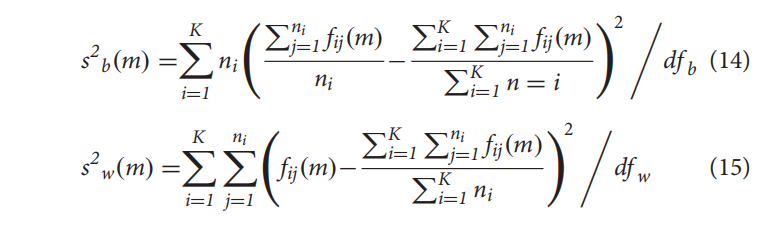
K表示总的特征,N表示总的样本
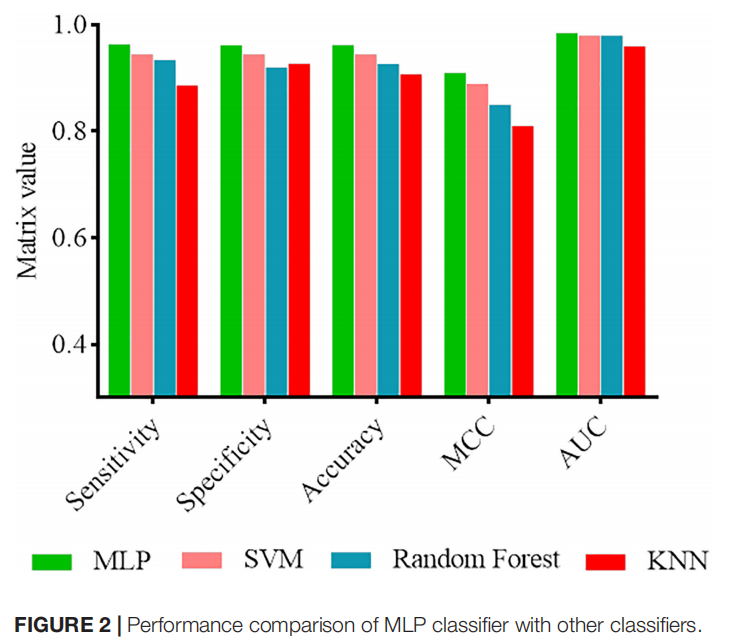
Classification
SVM,随机森林,K近邻,多层感知机
Performance Evaluation

Results and Discussion