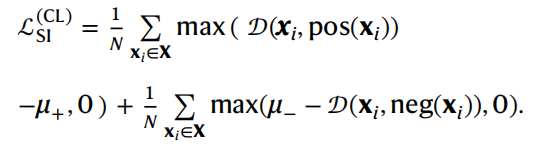论文地址:Structure-inducing pre-training
论文实现:https://github.com/mmcdermott/structure_inducing_pre-training
SIPT:通用的结构感知预训练框架
Abstract
本文分析预训练中怎么增加每个样本的隐空间结构感知能力,即预训练时怎么对embedding增加距离或几何的约束,提出了一个预训练框架。实验研究横跨三个数据模态和十个微调的任务。
Introduction
在NLP中,完整的评估一个文本的情感是一个样本间的任务,而比如识别局子里的实体属于样本内的任务。而在生物医学领域,样本间的任务比样本内的任务更多
目前有些方法忽略了整个样本空间中的几何loss,还有些方法是比较浅的约束,比如增加了辅助的分类PT目标,或是更深层次的基于数据增强或是去噪的对比学习loss
基于这些观察,我们提出了PT目标有两步:
- 利用语言模型样本内的关系的去噪目标
- 一个loss来正则化每个样本latent space的几何形状,来反映出特定领域的图预训练
本文主要三个贡献:
- 通过全面和详细的评估,指出目前PT目标缺少引入结构约束,也不够深和直白
- 建立了一个预训练框架
- 进一步对这个框架提出了理论结果
Results
General PT problem formulation
像BERT这样需要先预训练,并且不知道下游任务是什么,但是GPT这样的预训练就可以直接用于下游任务的生成
Defining explicit and deep structural constraints
假设的核心是,目前大多数nlp推导出的PT方法没有对(每个样本)的潜在空间几何施加明确的、深刻的约束。为了证明这一说法,通过以下定义定义了明确的和深层的结构约束
Definition 1 explicit versus implicit structural constraints
显式就是能直接推理出两个样本之间的关系,比如距离
Definition 2 deep versus shallow srtuctual constraints
一个预训练目标施加结构约束需要多少信息来满足
比如PT loss是分类,有一个集合y,可以把表征映射到这个分类上去使得产生结构约束。如果 $y_i=y_j$ 的话那么两个样本 $z_i$ 和 $z_j$ 之间的相对距离就很小
然而这样的方法是很浅层的,因为只把每个class嵌入到一个空间里唯一的position中,把所有的这个class的样本都聚集到这个position附近。此外,这种基于距离的约束可以在一个很低维的空间中完成,说明这个约束是很浅层的
还可以考虑对比学习的方法,把噪声样本和原始样本拉近,同时远离其他样本,虽然这种方法平滑了空间中的噪声过程,但是这是一种隐式约束,不能推断出两个样本的距离是怎么限制的。但是相比于分类约束,还是要更深层次一些,因为噪声引起的样本间的联系不一的在低维空间中捕获
Existing PT method constraints
为了表明现有的方法不能广泛地提供同时施加具有深度和明确的结构约束的方法,调查了90多个现有的PT方法,在Extended Data Fig.1和补充材料
这些方法几乎没有使用深层次的,显式的约束,大多方法
- 没有使用样本间的预训练目标,比如文本生成的模型
- 使用显式但浅层的有监督预训练目标,比如BERT的NSP,或是ALBERT的sentence-order prediction(SOP),或是其他的多任务目标
- 使用隐式但深层的无监督或自监督对比学习目标,比如contrastive sentence embedding loss或noising-based, augmentation-based方法
有四个工作是使用了显式且深层的约束:Knowledge Embedding and Pre-trained LanguagE Representation (KEPLER), Contrastive Knowledge-aware GNN (CK-GNN), XLM-K and WebFormer。都可以描述为样本间的图对齐,把样本对的embedding约束在反应关系的PT图里面,但这些工作不够通用
Structure-inducing PT
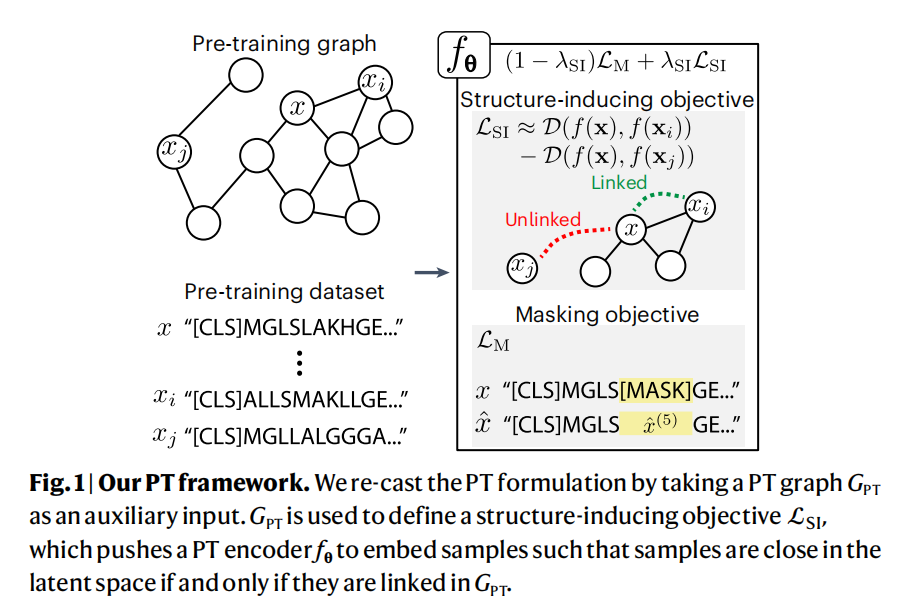
Datasets and tasks
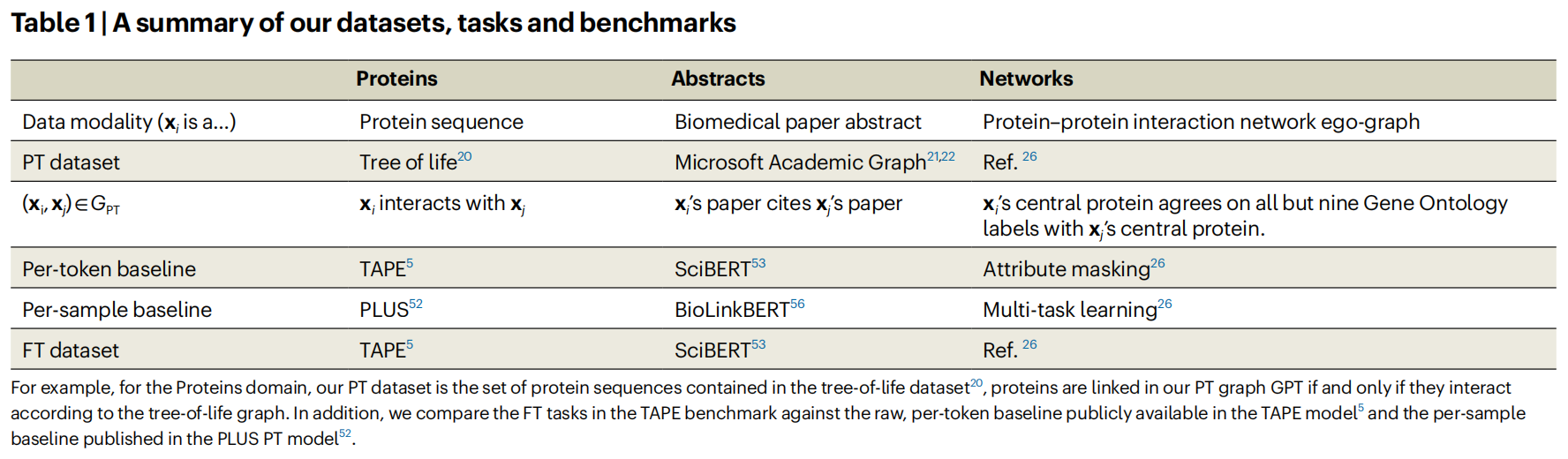
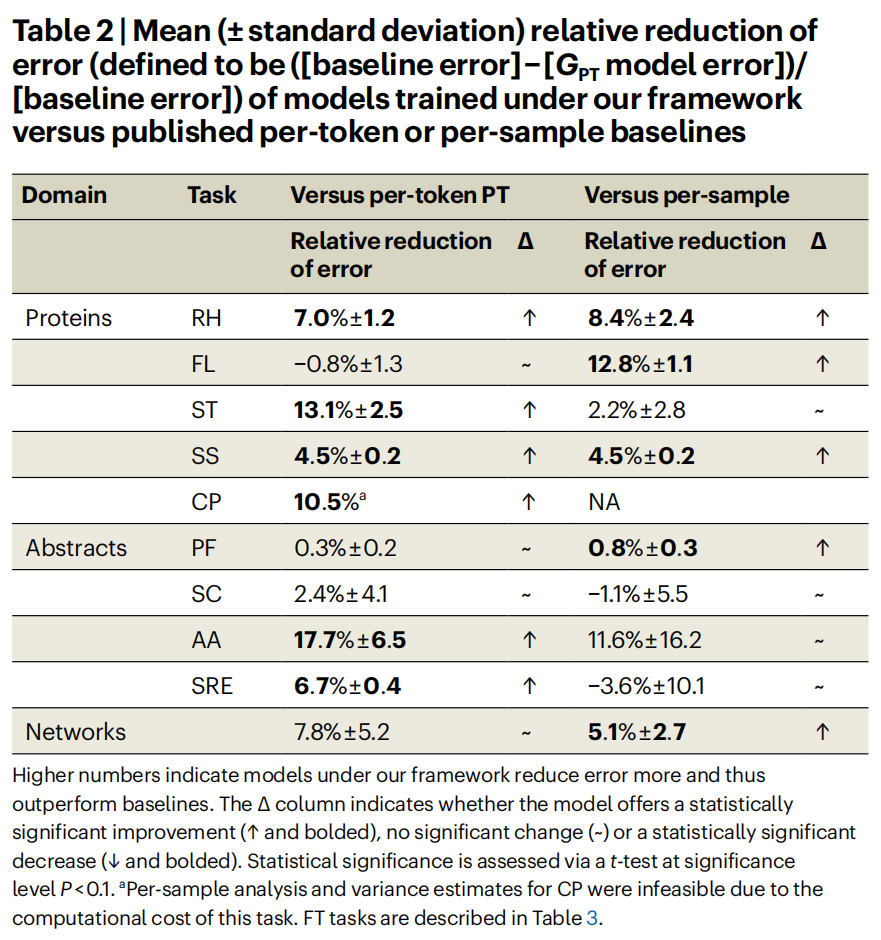
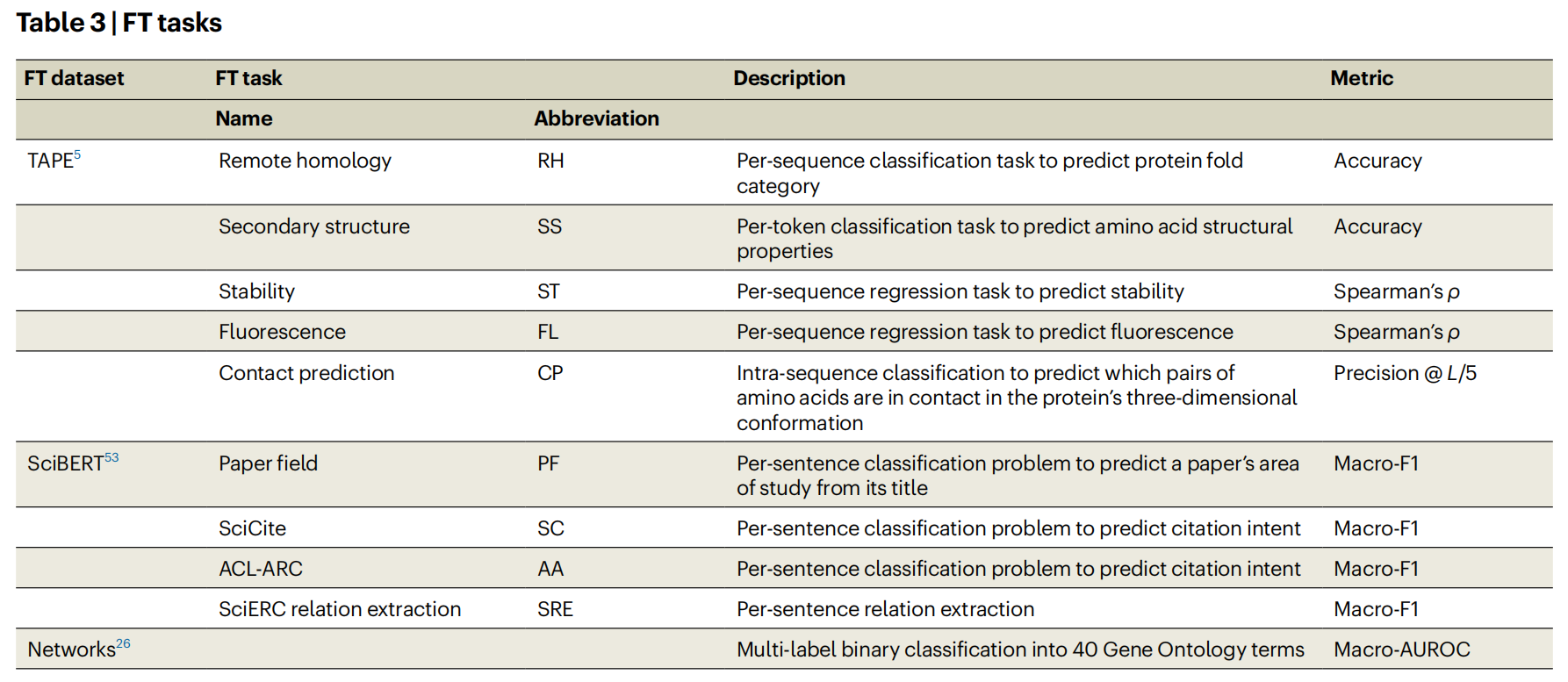
Methods
multi-similarity loss
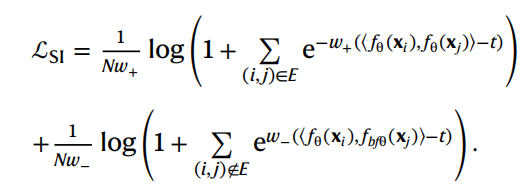
contrastive loss