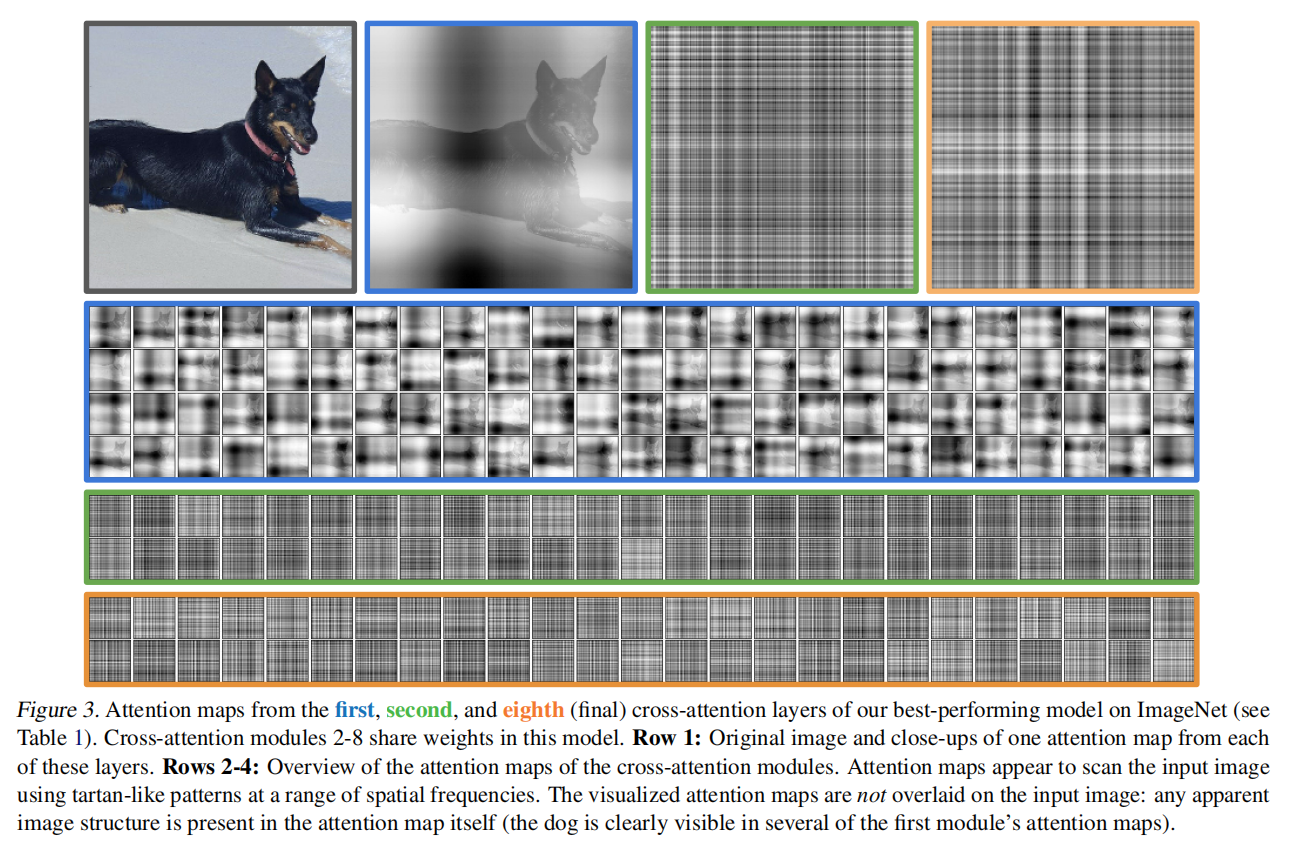
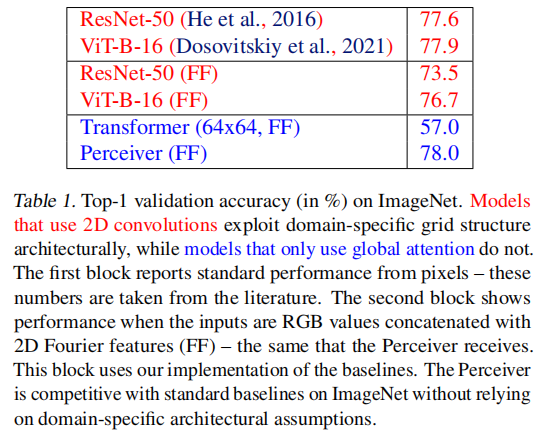
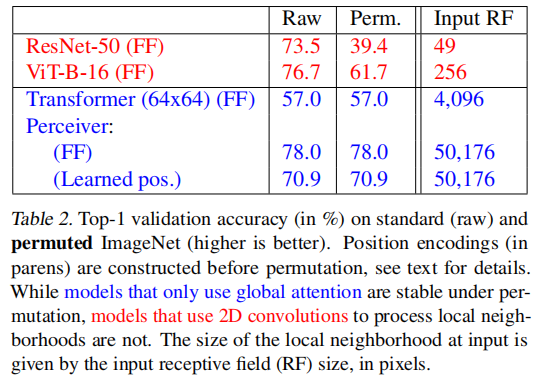
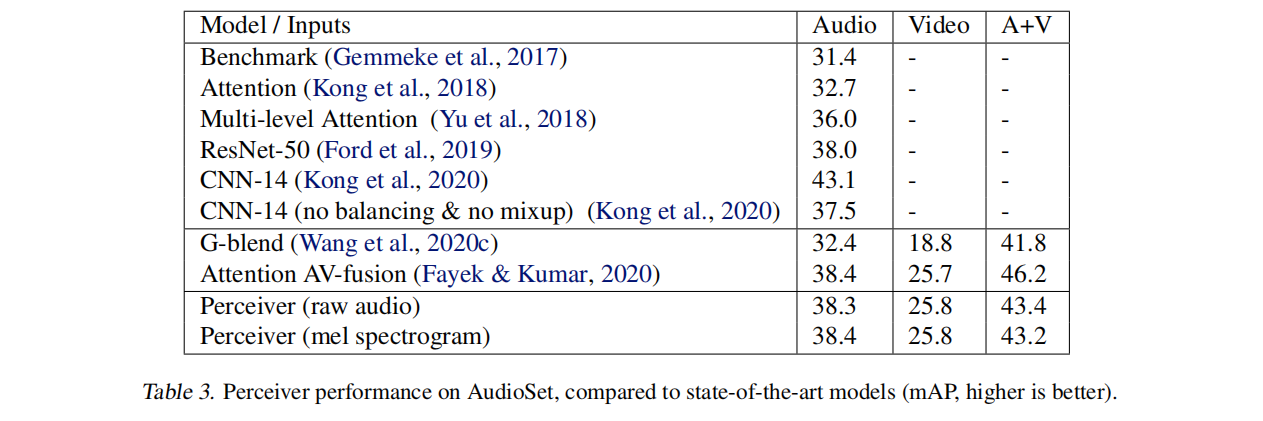
Perceiver: 不对称注意力多模态蒸馏压缩
Abstract
该模型利用非对称注意机制迭代地将输入压缩到一个紧密的潜在瓶颈中,允许其扩展以处理非常大的输入,这种架构在各种模式的分类任务上具有强大的专业模型:图像、点云、音频、视频和视频+音频。
Introduction
早期计算机视觉里面的空间局部性(spatial locality)这种归纳偏差对于提升性能是有益的,但是随着数据集的增加,继续把这种偏差引入模型是正确的吗?或者我们是否应该去鼓励让数据本身说话?
具有强烈先验知识的框架有一个显眼的问题,就是非常的modality-specific,比如在输入单个图片时可以使用2D网络架构,但是如果换到立体像对时,怎么从多个sensor中联合处理像素呢,concat或是sum?如果换到audio,那么2D网络就不适用了,1D卷积或LSTM可能是必要的
核心思想是引入一组潜在的单元,形成一个注意瓶颈,输入必须通过这个瓶颈
Methods
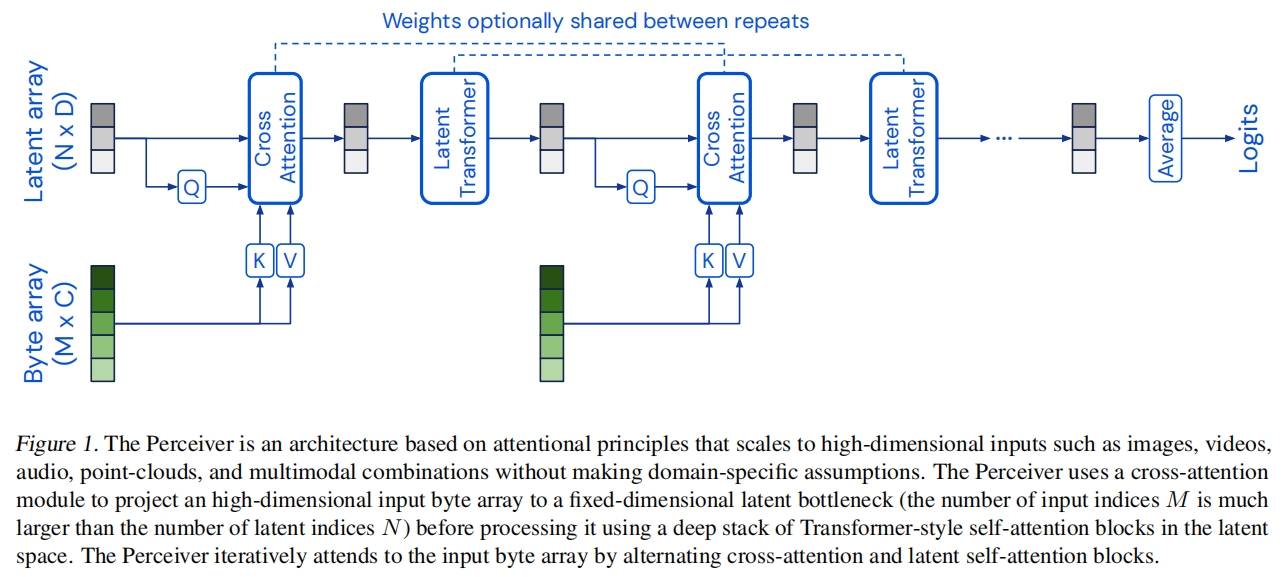

The Perceiver architecture
如果在transformer的每个block之间共享权重,模型就类似于RNN
Taming quadratic complexity with cross-attention
Q的shape为(N, D),其中N为当前序列的token的数量,H是hidden size;并且K和V的shape分别为(M, D)和(M, C),Q和K做乘积之后,得到的是(N, D) * (D, M) = (N, M)大小的矩阵,再右边乘以(M, C),就得到了(N, C)大小的矩阵
当N << M的时候,可以近似认为O(M)就是其复杂度了,把O(M*M)这种二次复杂度,降低到了一次复杂度
- asymmetric attention mechansim:N和M如果大小差别特别多
- distill inputs:query和Byte array做局部检索,把inputs信息压缩到一个小矩阵
- tight latent bottleneck:通过cross attention不断交互,得到新的低维度矩阵,用一个足够小的latent bottleneck表示复杂信息
Uncoupling depth with a latent Transformer
使用的GPT-2架构
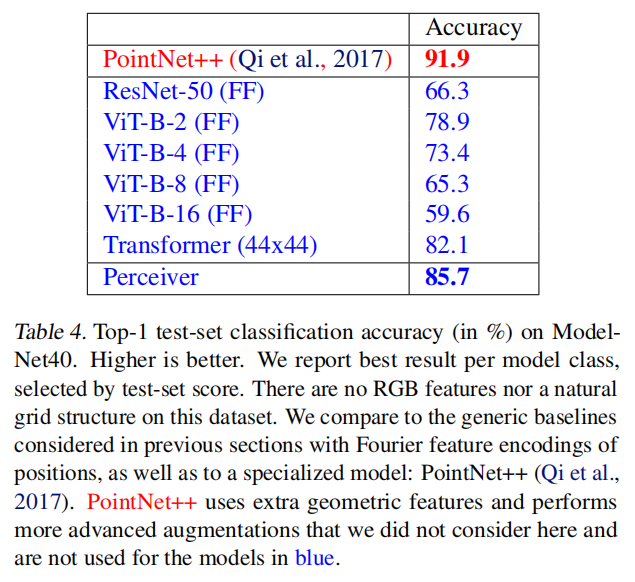
Experiments