论文地址:Perceiver IO:A General Architecture for Structured Inputs & Outputs
Perceiver IO:多模态统一架构
Abstract
提出perceiver IO,可以处理不同形态数据的通用模型,并且是随着输入和输出规模线性增长。模型通过一个灵活的查询机制,该机制支持各种大小和语义的输出,消除了对特定于任务的架构工程的需要。同样的架构再自然语言处理、视觉理解、多任务和多模态理解等任务都取得了很好的结果
Introduction

大多数机器学习研究集中于建立定制的系统来处理与单个任务相关的刻板的输入和输出,并且随着输入或输出的增长而变得更加多样化,这类系统的复杂性可能会急剧增加,而任务的输入和输出的结构可能会对数据的处理方式产生强烈的限制,从而使适应新的设置变得困难。难道为每一组新的输入和输出开发特定于问题的模型是不可避免的吗?
Perceiver使用注意力将各种模式的输入映射到一个固定大小的潜在空间,这个潜在空间被一个深度的、完全的注意网络进一步处理。这个过程将网络的大部分处理与输入的大小和特定于模态的细节解耦,允许它扩展到大型和多模态数据
但是Perceiver只能处理简单的输出空间,比如分类。这项工作中,开发了一种解码结构化输出的机制——语言、光流场、视听序列、符号无序集等。直接来自感知器的潜在空间,它允许模型处理大量的新领域,而不牺牲深度的、与领域无关的处理的好处
为此,为了实现这一点,通过使用一个指定该特定输出的语义的输出查询(output query)来关注潜在数组来生成每个输出
- 比如想要模型预测一个特定像素上的光流,我们可以从像素的xy坐标加上光流任务嵌入组成一个查询
- 然后模型将使用查询参加并产生一个单一的流向量。该体系结构可以产生许多输出,每个输出都具有任意的形状和结构,但是模型中的潜在特征仍然与输出的形状和结构不可知
Perceiver IO使用一个完全注意的读-过程-写架构来做到这一点:输入被编码(读)到一个潜在的空间,潜在的表示通过多层处理被细化(过程),并且潜在的空间被解码(写)以产生输出。使用了Transformers最好的特征,领域无关的Nonlocal processing of inputs和编码器-解码器架构,这种方法可以把元素输入大小和输入空间大小解耦,降低复杂度
The Perceiver IO Architecture
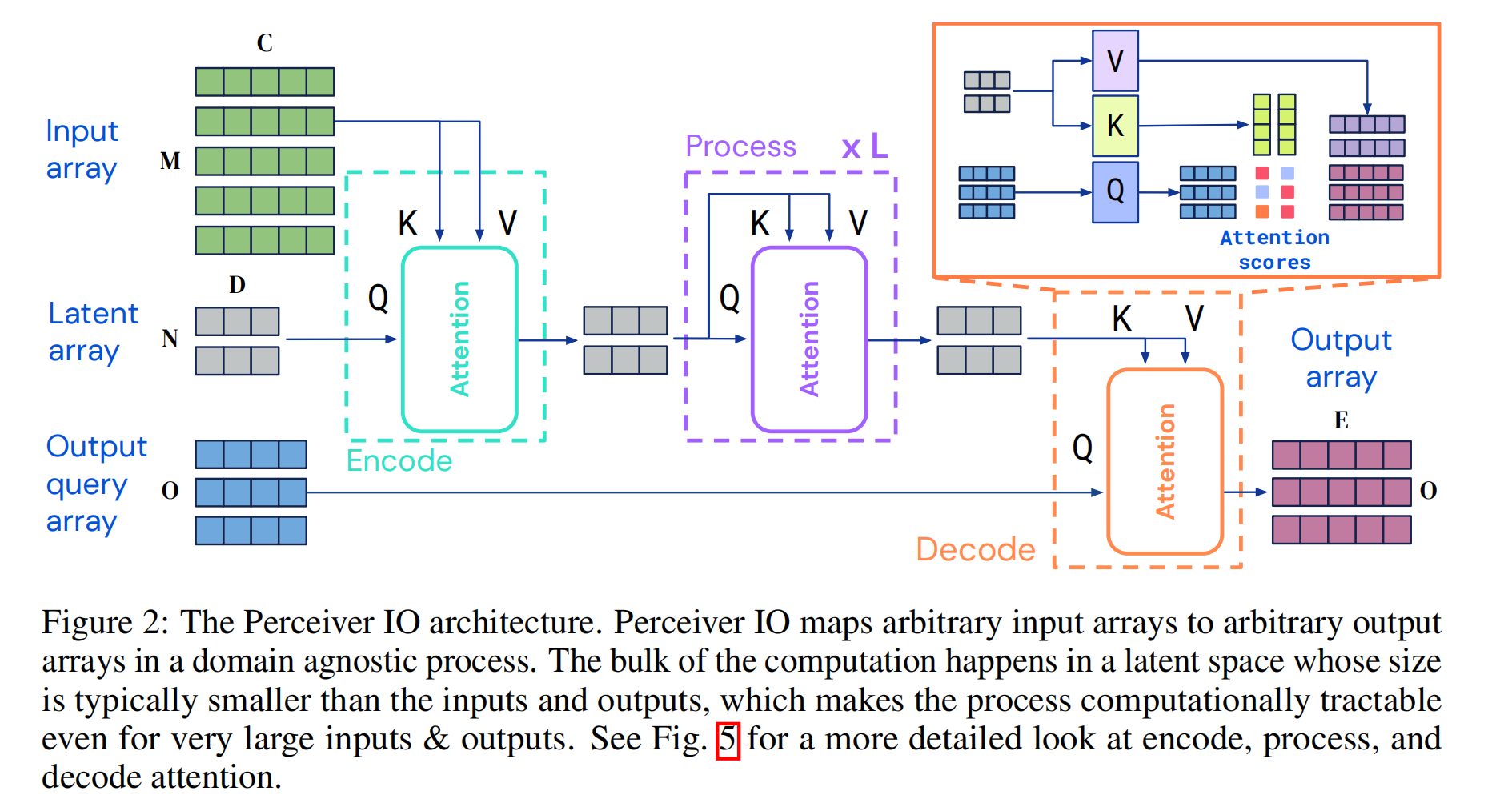
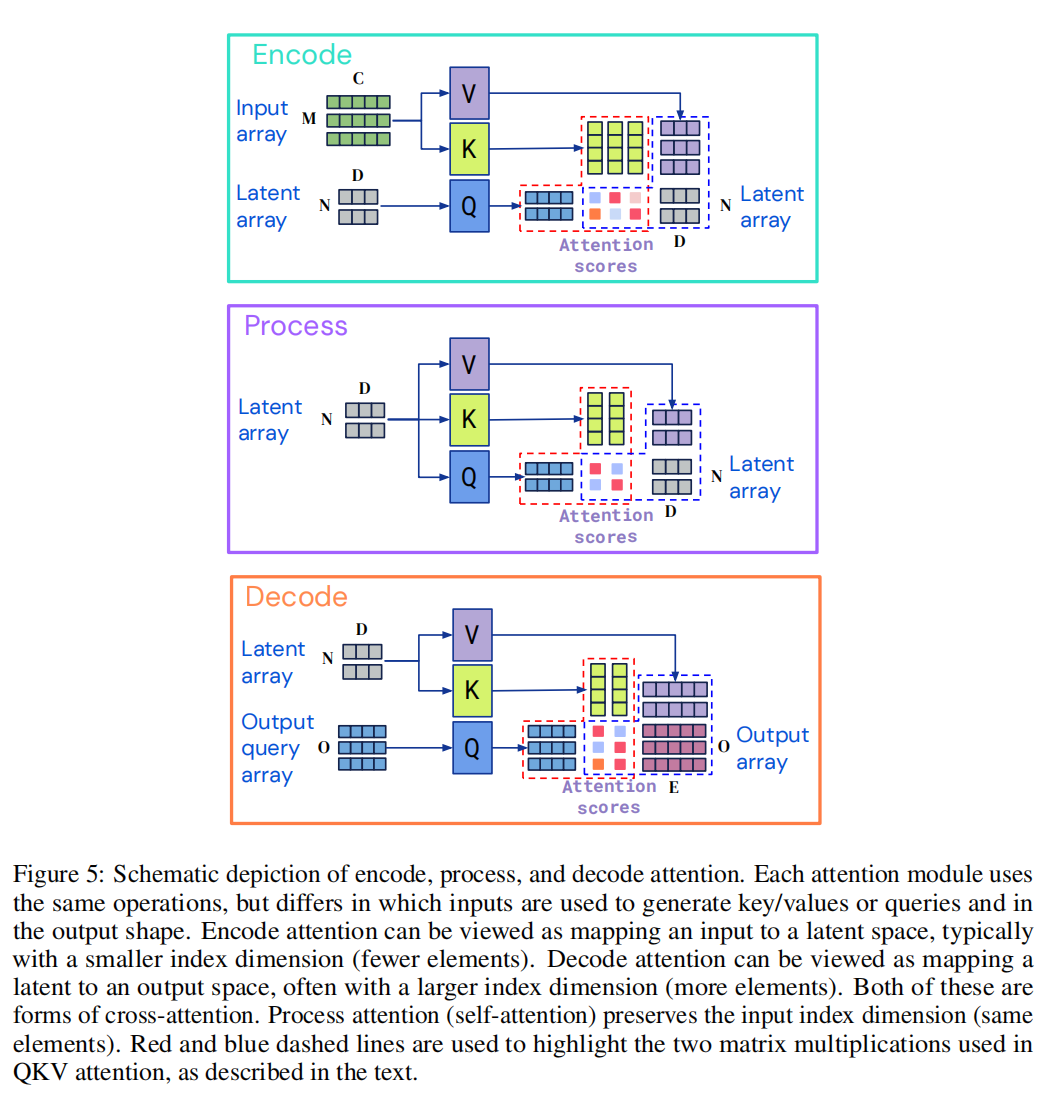

Encoding, Processing, And Decoding
每个模块都是用一个全局query-key-value(QKV)注意力操作,然后是一个多层感知器(MLP)。在Transformer的架构中,通常将MLP独立地应用于索引index维度的每个元素。
编码器和解码器都接受两个输入矩阵,第一个用作模块的key和value网络的输入,第二个用作模块查询网络的输入。模块的输出具有与query输入相同的索引维度(即相同数量的元素),这也是编码器和解码器模块能够产生不同大小输出的原因。
那为什么不直接用Transformer?
Transformer在计算和内存方面的扩展性都很差,Transformer需要在其整个架构中全部署注意力模块,使用其全部输入在每一层生成query和key,这也意味着每一层在计算和内存中都是二次时间复杂度的,像图片这种输入比较长的数据,不预处理的话根本没法训练。
相比之下,Perceiver IO非均匀地使用注意力,首先使用它将输入映射到隐空间,然后在该隐空间中进行处理,最后使用注意力映射到输出空间。
最终这个架构对输入或输出大小没有二次时间复杂度的依赖性,因为编码器和解码器注意模块分别线性依赖于输入和输出大小,而隐注意力独立于输入和输出大小。
并且这个架构需要更少的计算和内存需求,Perceiver IO可以扩展到更大的输入和输出。虽然Transformer通常用于输入和输出最多几千维的设置,但这个新模型在输入和输出维度数十万的数据上都显示了不错的结果。
Decoding The Latent Representation with a Query Array
第二步是将隐空间中的表示向量进行解码,目标是在给定大小为N×D的隐表示的情况下,生成大小为O×E的输出矩阵,这意味着query信息应该反映下游任务,并能够捕获输出中所需的任何结构,可能也包括图像中的空间位置或序列中输出字的位置
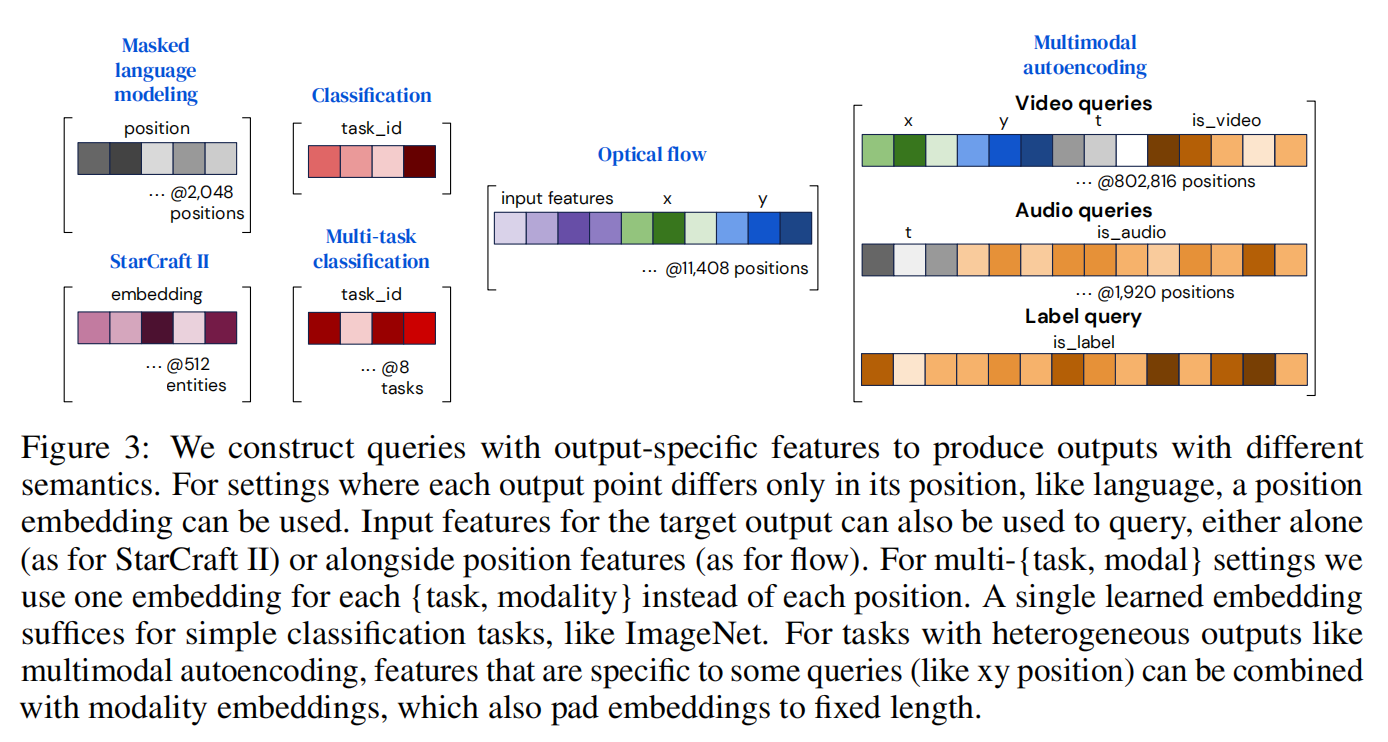
通过组合(连接或添加)一组向量到一个query向量中来构造queries,该查询向量包含与O个期望输出之一相关的所有信息。
对于具有简单输出的任务,例如分类,这些query可以在每个示例中重复使用,并且可以从头开始学习。对于具有空间或序列结构的输出,例如,学习的位置编码或傅里叶特征,则额外包括表示输出中要解码的位置的位置编码。对于具有多任务或多模态结构的输出,学习每个任务或每个模态的单个查询,该信息允许网络将一个任务或模态查询与其他任务或模态查询区分开来,就像位置编码允许注意区分一个位置与另一个位置一样。
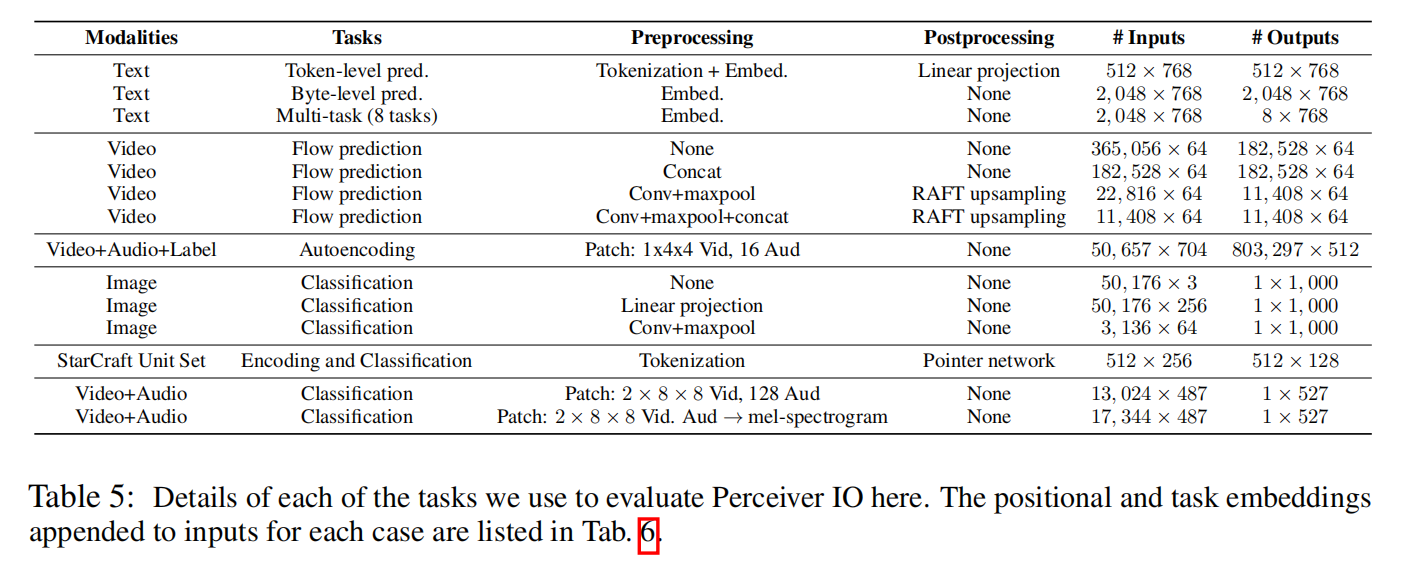
为了评估Perceiver IO的通用性,研究人员在多个领域、多种数据的任务中对其进行评估,包括语言理解(masked language modeling和下游任务微调)、视觉理解(optical flow和图像分类)、游戏符号表示(星际争霸II)以及多模式和多任务设置。
Experiments
为了评估Perceiver IO的通用性,研究人员在多个领域、多种数据的任务中对其进行评估,包括语言理解(masked language modeling和下游任务微调)、视觉理解(optical flow和图像分类)、游戏符号表示(星际争霸II)以及多模式和多任务设置。

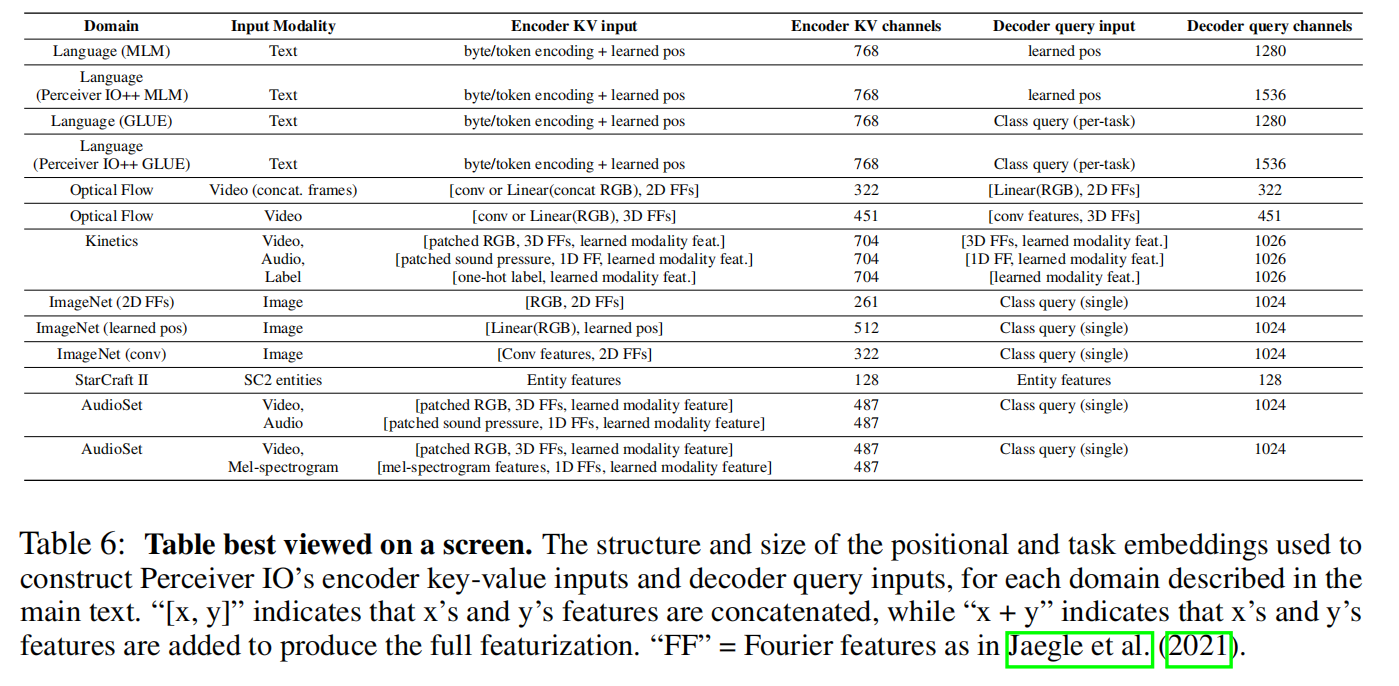
更多实验见原文

