论文地址:Feature Reuse and Scaling:Understanding Transfer Learning with Protein Language Models
protein-transfer:探究预训练层数、参数、归纳偏置等对下游任务影响
Abstract
PLM的表征非常强大,但是目前人们对预训练学习到的特征如何与下游任务相关并有用知之甚少。本文执行了370次实验,包括不同的下游任务,架构、模型大小和深度,预训练时间等。虽然与朴素序列表示相比,几乎所有的下游任务都从预训练模型中获益,但大多数任务的性能与预训练无关,而是依赖于在预训练早期学习到的低水平特征。我们的结果表明,当前的PLM预训练范式和这些模型的大多数应用之间的不匹配,这表明需要更好的预训练方法
Introduction
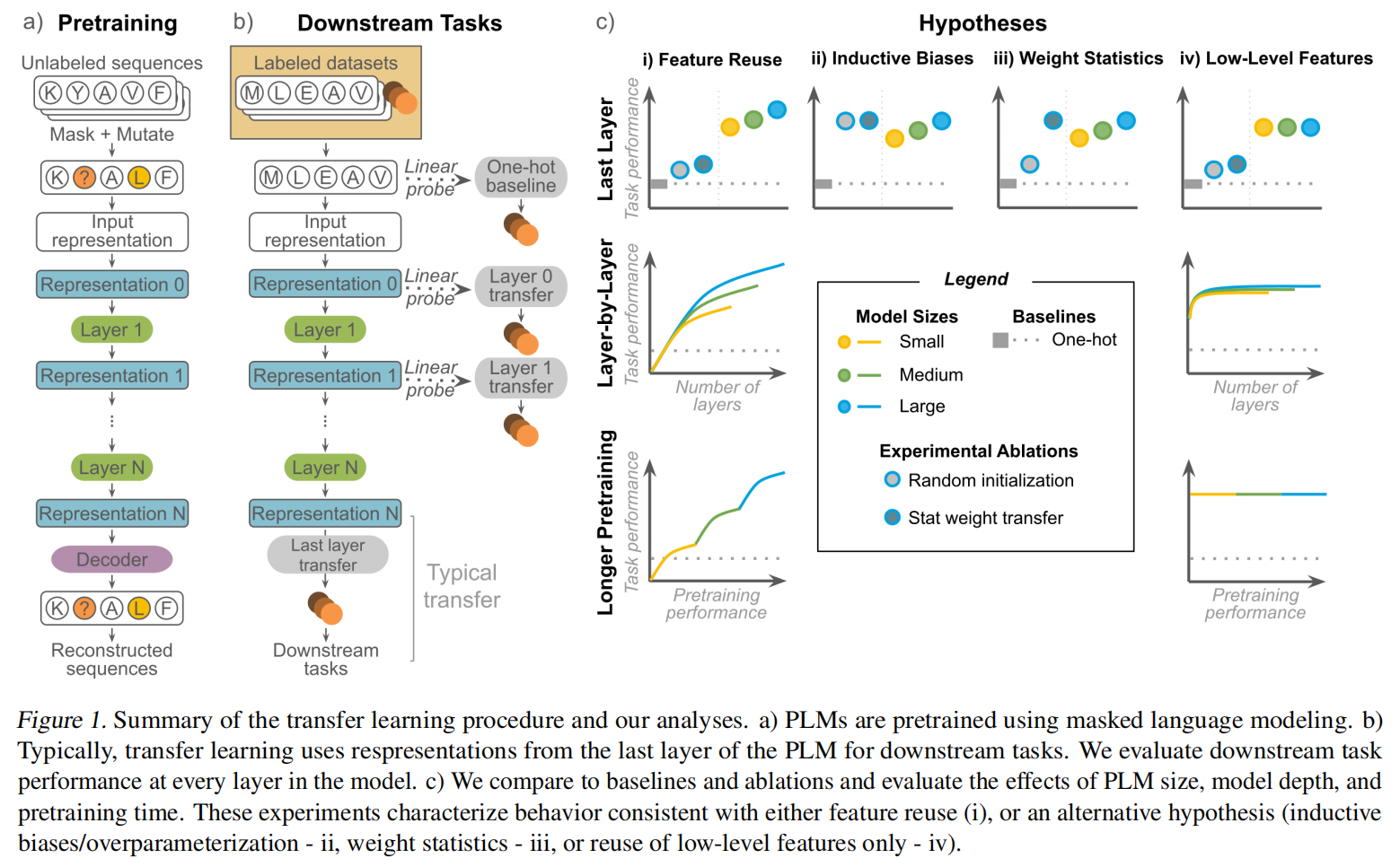
目前对于序列到功能的理解映射还是非常贫瘠,介于数据的稀少限制,采用迁移学习的方法是一个有效的解决方案
计算机视觉等其他领域对于迁移学习的研究更加成熟,因此我们综合了一系列可能的假设来解释下游任务的改进,并设计进行了一系列的实验来研究
Feature reuse (Fig1. 1c-i): 一个流行的假设是,MLM预训练学习蛋白质生物学的一般特征,这些特征可以在任务中重复使用
Inductive biases and overparameterization (Fig. 1c-ii):更大参数的预训练模型可能和一些有用的signal偶然对齐
Statistics of pretrained weights (Fig. 1c-iii):预训练的主要好处是可以初始化权重到一个合理的scale
Reuse of low-level features (Fig. 1c-iv):只有在预训练早期学习到不复杂的特征才有可能有利于迁移学习
主要贡献:
- 370次实验,全面的研究
- 目前的MLM训练范式不适合生物
- 系统证据表明,在许多蛋白质属性预测任务上的表现与PLM大小或预训练无关
Datasets and Pretrained Models

Transfer Learning with Protein Language Models
在UniRef50上训练的两个模型大小相当的蛋白质mlm家族,ESM和CARP
Experimental Setup
Baseline and ablations
- One-hot baseline:直接使用氨基酸的one-hot representation
- Random init:随机初始化‘
- Stat transfer:为了评估迁移学习的效果是否由于权重统计和/或将权值初始化到一个合理的尺度,随机初始化匹配预先训练的权值分布的PLM的权值的影响
Scaling experiments
Model size
⚪是CARP,×ESM
Model depth
-是CARP,–是ESM
Model checkpoint
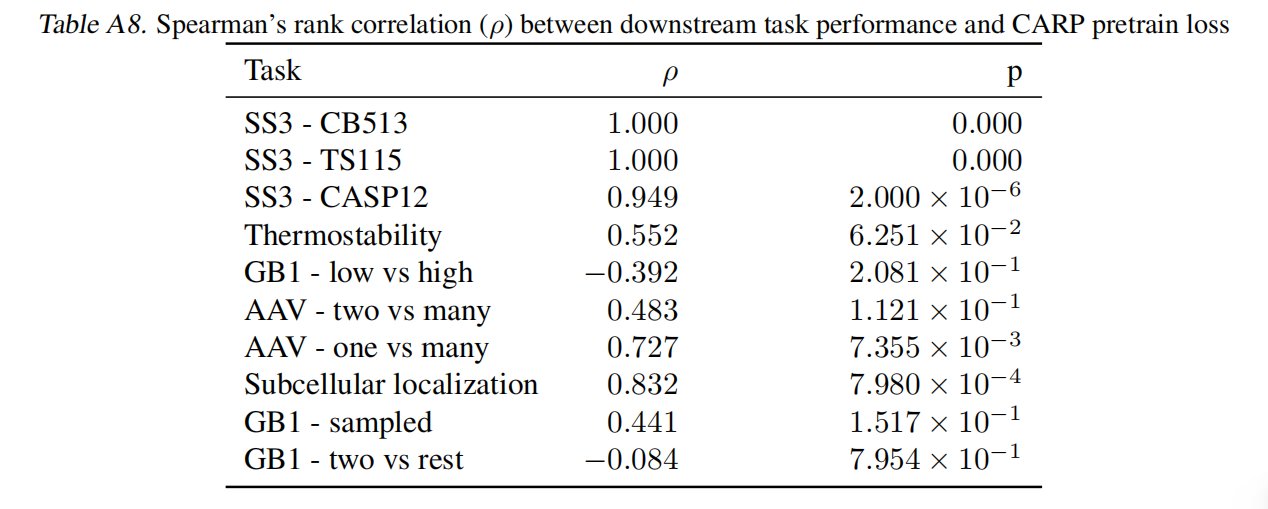
Results

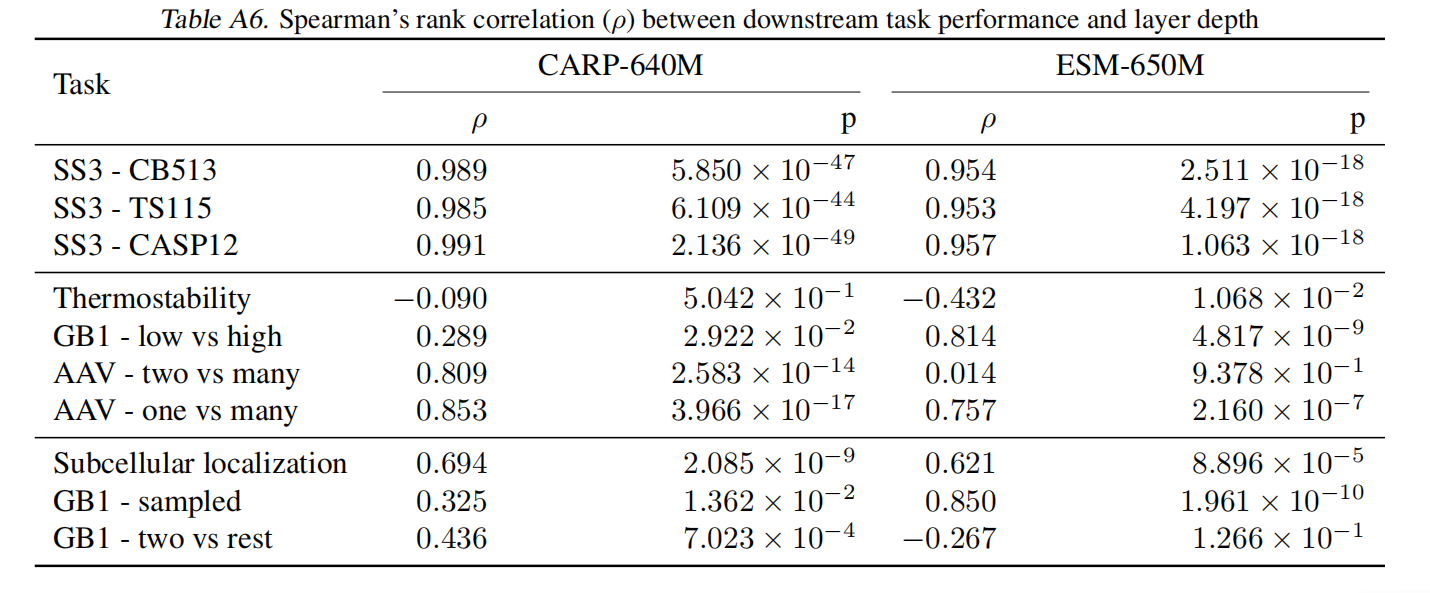
Structure Prediction Benefits from Transfer Learning Because It Is Well-Aligned with MLM pretraining
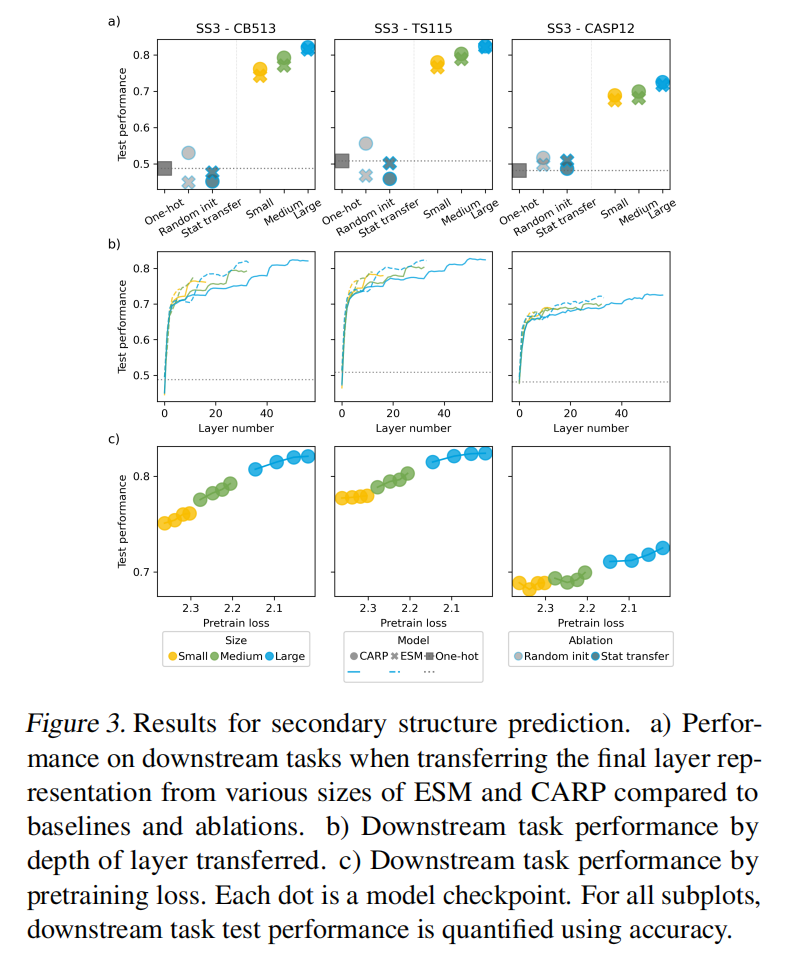
迁移学习提高二级结构预测性能,改进不是由于模型的归纳偏差或权重统计
Many Tasks Benefit from Transfer Learning Despite Lack of Alignment with MLM Pretraining
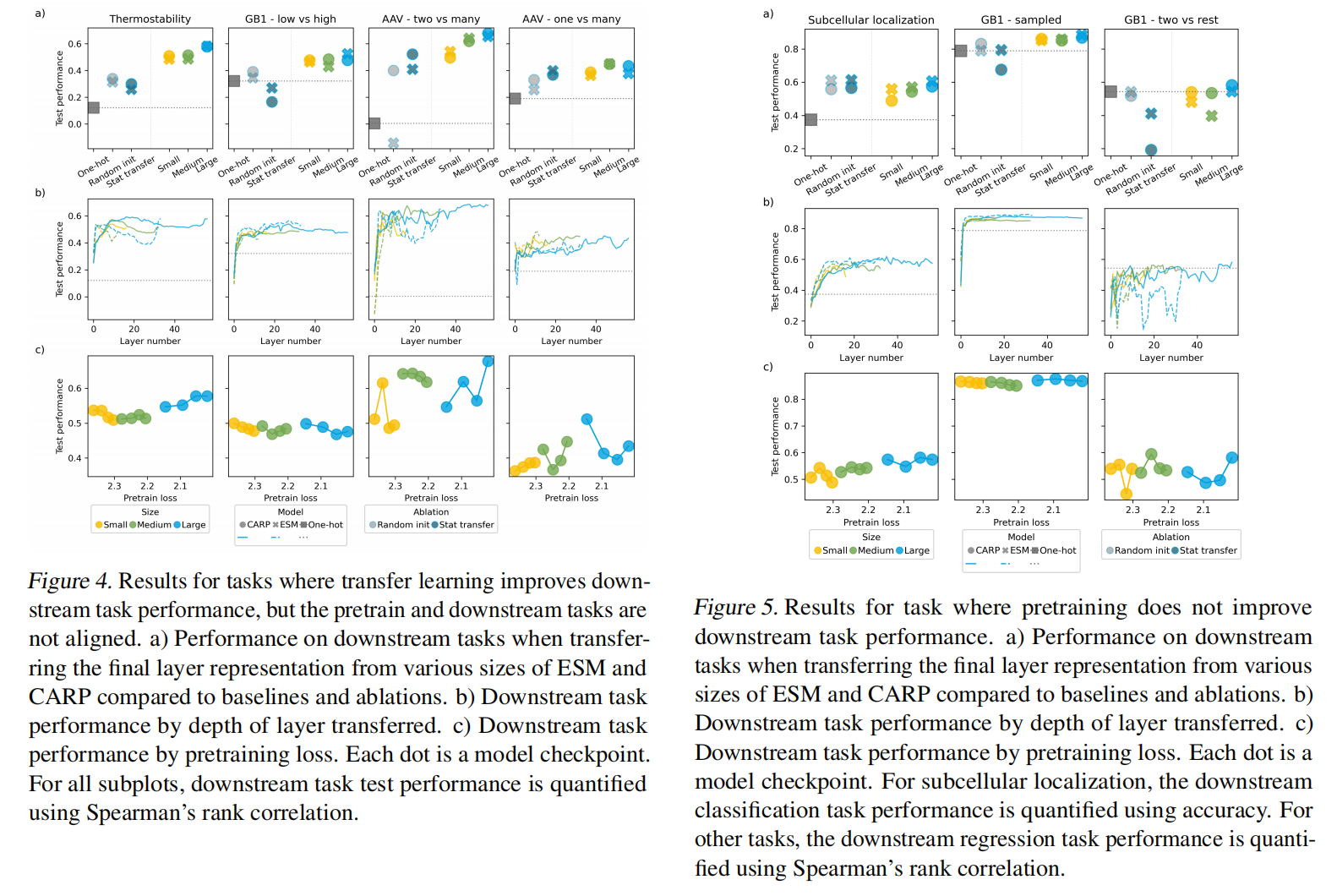
迁移学习提高了基线的表现,即使任务与预训练的任务不是很一致

