论文地址:DivideMix:Learning with Noisy Labels as Semi-supervised Learning
DivideMix:label noise+半监督训练
Abstract
深度学习方法是数据饥渴的,很多工作都在尝试使用深度学习时减少标注开销,两个突出的方向包括使用有噪声标签的学习和利用未标记数据的半监督学习。本文提出DivideMix,利用半监督学习技术进行噪声标签学习,DivideeMix采用混合模型对每个样本的损失分布进行建模,将训练数据动态划分为有干净样本的标记集和有噪声样本的未标记集,并以半监督的方式对有标记数据和未标记数据进行模型训练。为了避免确认偏差,同时训练两个分离的网络,每个网络使用来自另一个网络的数据集划分。在多个基准数据集上的实验表明,比最先进的方法有了实质性的改进。
Introduction
一些标注大规模数据的廉价方法,如搜索商业引擎,下载带有tag的媒体图片,利用机器生成的标签等都是带有Noisy labels,近期的研究又表明在noisy labels上过拟合会导致差的泛化性能
现有的从噪音标签中学习(LNL)的方法主要依赖于损失修正方法,比如用噪音转移矩阵修正loss function等。另一个方法是用半监督学习(SSL),比如使用无标注的数据强迫模型生成低熵预测或是对扰动输入进行一致性预测
尽管LNL和SSL的个体研究都取得了进步,但它们之间的联系尚未得到充分的探索。在这项工作中提出了DivideMix,它以半监督的方式解决标签噪声的学习,丢弃了极有可能是有噪声的样本标签,并利用有噪声的样本作为未标记的数据来规范模型的过度拟合,并提高泛化性能
主要的贡献如下:
- 提出了co-divide,同时训练两个网络,对于每个网络,我们在每个样本的损失分布上动态拟合一个高斯混合模型(GMM),将训练样本分为一个标记集和一个未标记集。然后,分割后的数据被用来训练另一个网络。共分使两个网络保持发散,从而可以过滤不同类型的误差,避免自我训练中的确认偏差
- 在SSL阶段,我们通过标签co-refinement和co-guessing来改进MixMatch来考虑标签噪声。对于标记样本,我们使用GMM对其他网络的网络预测来细化它们的ground-truth标签。对于未标记的样本,我们使用这两个网络的集成来对它们的标签进行可靠的猜测
- 实验表明,DivideeMix在不同类型和水平的标签噪声的多个基准上显著提高了最先进的结果,还提供了广泛的消融研究和定性结果,以检验不同成分的影响
Method
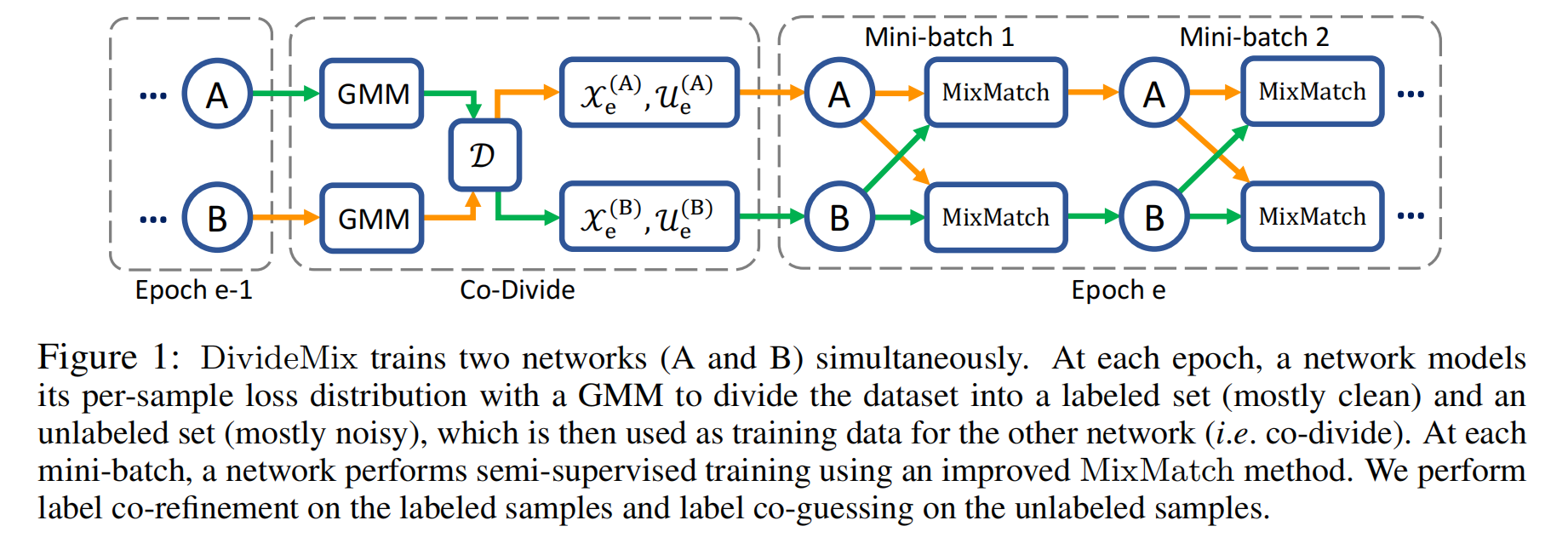

Co-divide by Loss Modeling
神经网络一般拟合clean样本比noisy样本更快,这也就意味着更低的损失,我们需要通过per-sample loss distribution找到一个样本是clean的概率,这里是通过Loss拟合一个two-componet GMM
Co-divide的作用是将训练数据集划分为干净数据集好噪声数据集。现考虑网络A,将训练集D中的每一个样本i 输入到网络A,网络A将输出其对应的预测结果,即预测向量。样本的预测向量和标签向量的交叉熵(Cross-Entropy)作为单样本的损失li 。采用最大化期望的方法将全部样本的损失的分布拟合一个二分量的高斯混合模型(Gaussian Mixture Model,GMM)。对每一个样本i ,后验概率p(g|li) 作为其属于干净样本的概率(g 表示高斯分量),表示为ωi 。用τ 表示干净样本和噪声样本的分类阈值。当ωi≥τ ,则样本i 视为干净样本;当ωi<τ ,则样本i 视为噪声样本。对网络A,利用上述方法即可将样本集划分为干净数据集χeB 和噪声数据集UeB (为什么上标是B,因为由网络A划分的数据集,后面送给网络B处理,也因此才叫co-divide)。同理,对网络B,利用上述方法即可将样本划分为干净数据集χeA 和噪声数据集UeA 。
Confidence Penalty for Asymmetric Noise
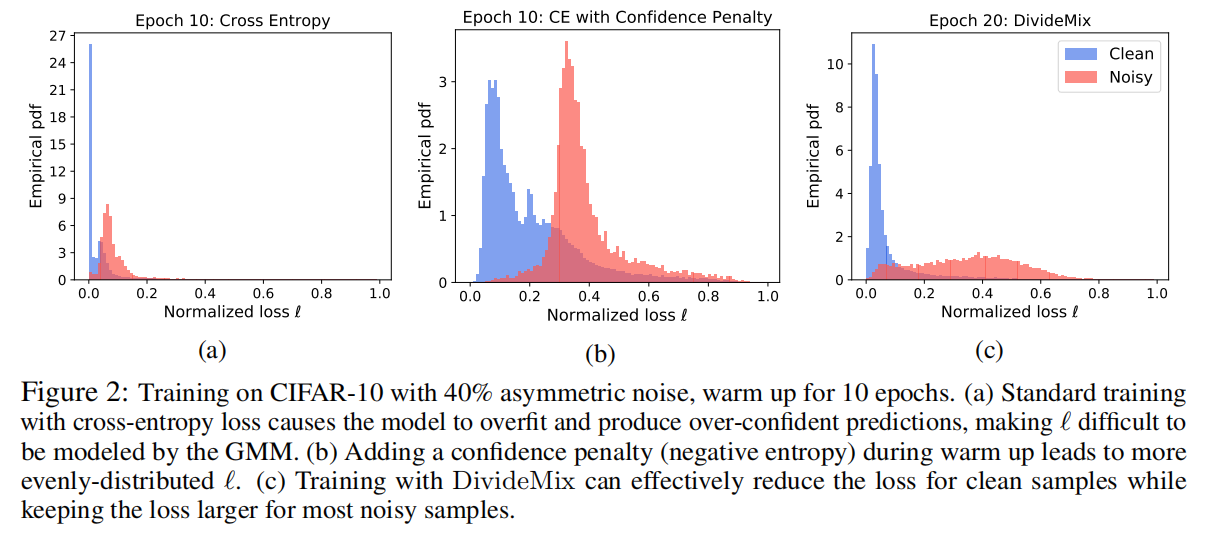
最开始的几个epoch使用标准的交叉熵函数训练。warm up对对称(即均匀随机)标签噪声是有效的。然而,对于不对称(即类条件)标签噪声,网络会在预热过程中迅速对噪声进行过适应,并产生过度自信(低熵)预测,这导致大多数样本的归一化损失接近零,如图2a。为了解决这个问题,我们通过添加一个负熵项来惩罚来自网络的自信预测
MixMatch with Label Co-Refinement and Co-Guessing
Co-Refinement
Co-refinement的作用是对干净样本重新打标签。现考虑网络A,将干净样本及其旋转增强后的m个样本输入当前状态的网络A,得出的m个预测向量取平均,作为该样本的预测向量。通过线性组合标签向量和预测向量,并运用sharpen函数处理,其结果作为该样本新的标签向量,仅在本Epoch有效。对网络B同理。
Co-Guessing
Co-guessing的作用是对噪声样本(其原来的标签已经被丢弃)赋予新的标签。现考虑网络A,将噪声样本及其旋转增强后的m个样本同时输入当前状态的网络A和网络B。网络A和网络B分别输出对应的预测向量,共计2m个预测向量。将这2m个预测向量取平均,并运用sharpen函数处理,其结果作为该样本的标签向量,仅在本Epoch有效。对网络B同理。
MixMatch
MixMatch的作用是混合经过Co-refinement和Co-guessing后的样本,生成实际用于完成本次训练的输入数据。它对每一个输入样本x1 ,从当前批量里面(包含干净样本子集和噪声样本子集)中随机抽取另一个样本x2 ,组成样本对(x1 ,x2 ),它们对应的标签为(p1 ,p2 )。混合的(x’ ,p’ )用如下公式计算:
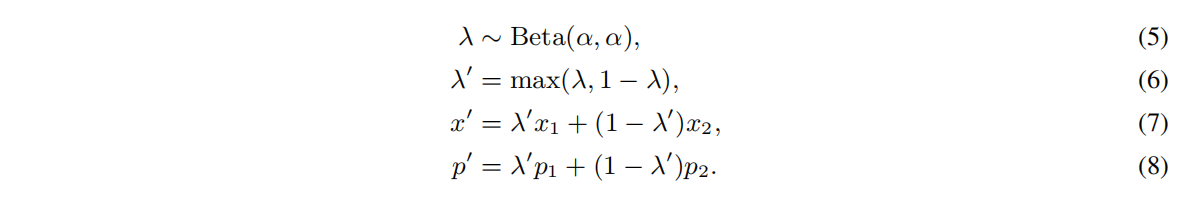
若x1 取自干净样本,则其经过计算后的新样本(包含计算后的标签)组成的集合表示为X’ ;若x1 取自噪声样本,则其经过计算后的新样本(包含计算后的标签)组成的集合表示为U’ 。X’ 和U’ 用作本次训练的实际输入数据
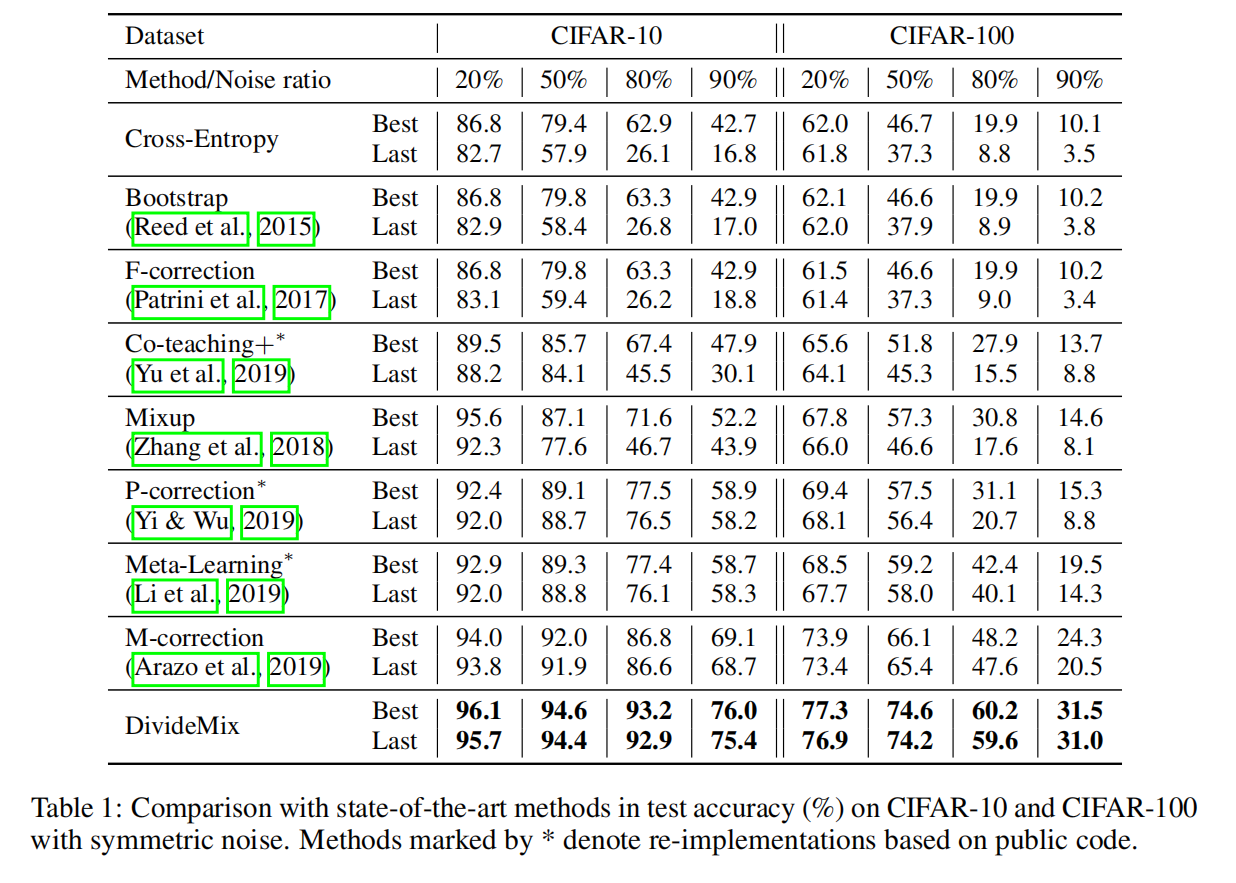
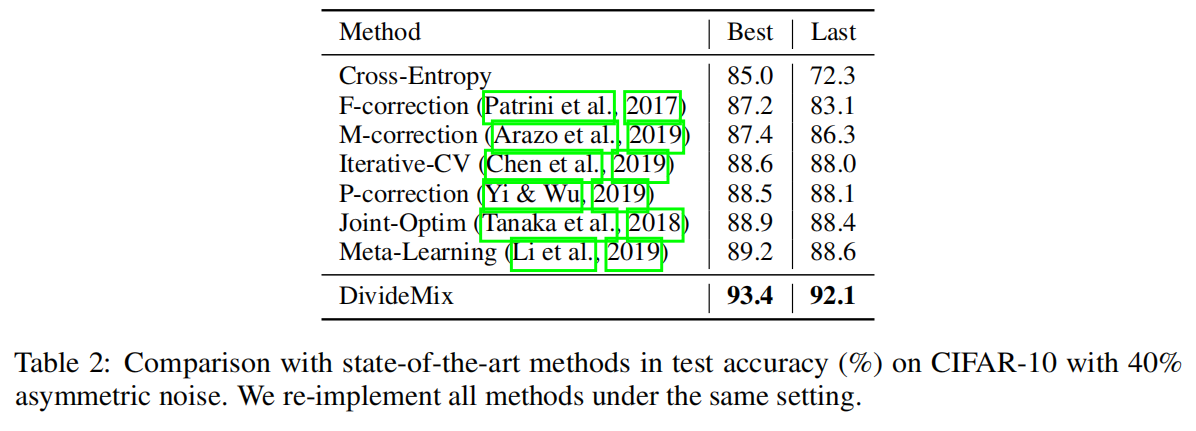
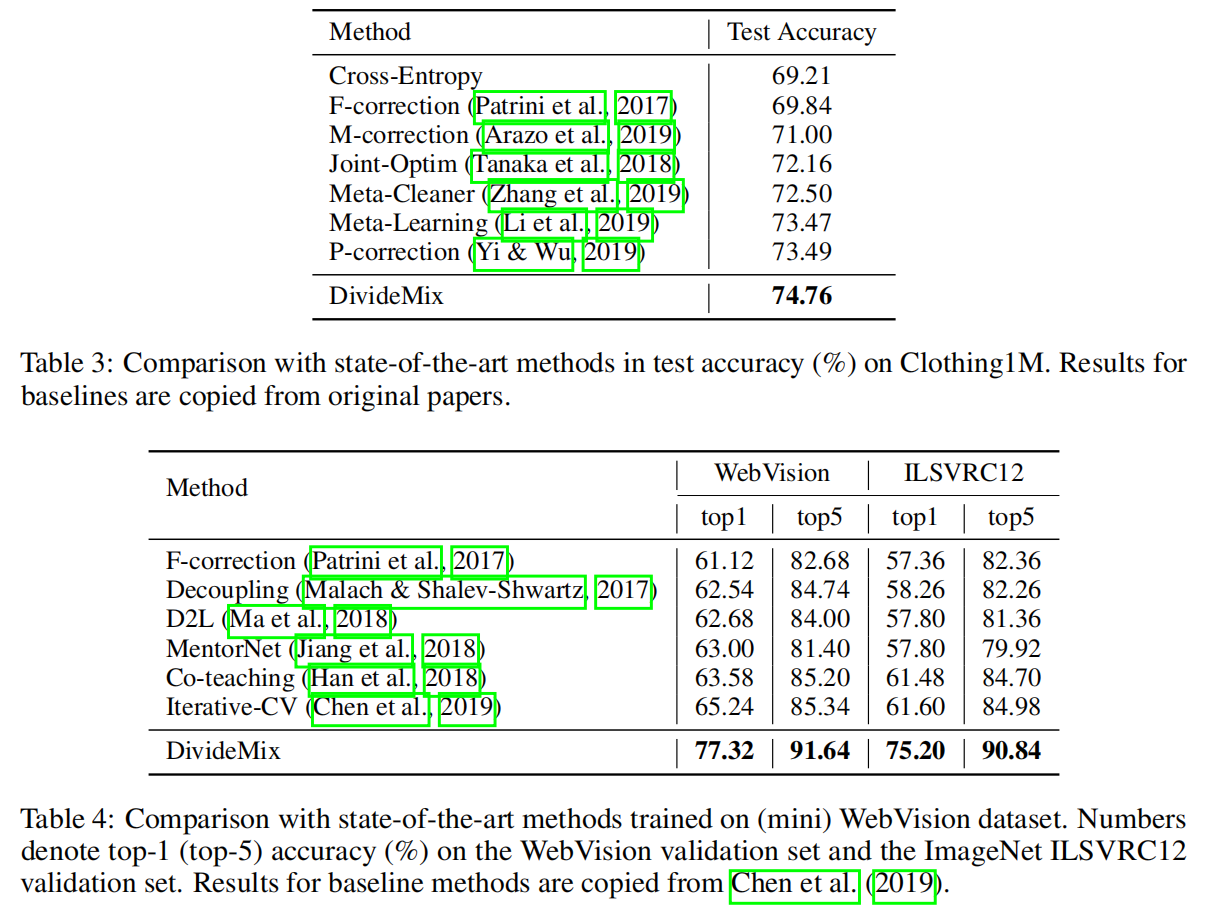
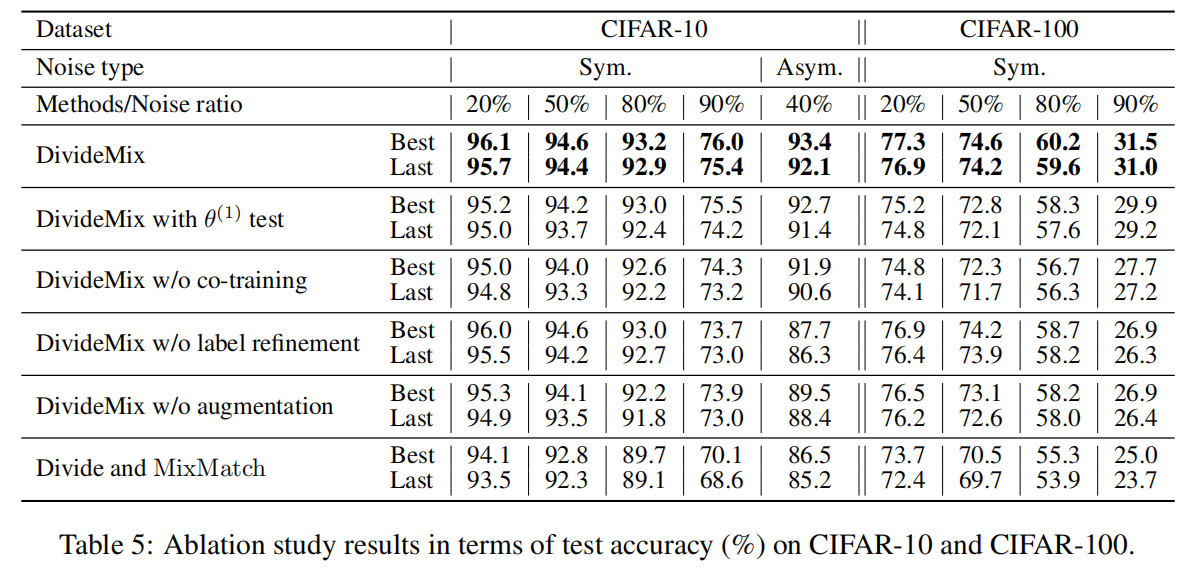
Experiments
实验了两种类型的标签噪声:对称和非对称。对称噪声是通过用所有可能的标签随机替换训练数据百分比的标签而产生的